软工实践寒假作业2/2
221801331 张晨星 第二次寒假作业
| 这个作业属于哪个课程 | 2021春软件工程实践W班(福州大学) |
|---|---|
| 这个作业要求在哪里 | 寒假作业2/2 |
| 这个作业的目标 | 学习《构建之法》;完成词频统计作业边学习相关知识 |
| 其他参考文献 | 《构建之法》 |
任务一——阅读《构建之法》并提问
《构建之法》阅读
- 问题一
关于团队合作的阶段
这部分提到了很多在企业开发中团队成员合作中各阶段的演变和问题;
我想知道的是,在大学期间学生团队的合作开发(例如这学期的软工实践组队)与企业开发会有什么不同,例如文中大量提到了领导的作用和权威性,而学生团队的合作中,鉴于较为平等的关系,所谓的领导该由什么样的人担任,学生团队中是否需要像企业开发中那样,领导拥有较高的决策权和权威呢?
其中又提到在创造阶段的团队他们一般不会关心或争执“方法论”的问题——我们究竟是瀑布模型,还是改良的螺旋模型,或者是超级敏捷型。我们是CMM 2级或3级。方法论对于他们,就像水对于鱼一样自然,那么多于处于萌芽或是磨合阶段的团队,“方法论”具有什么样的意义或是重要性呢?所谓的模型是否是团队开发中需要统一的标准呢?
同时,作为团队中的角色、身份不同的成员,需要怎么通过自己的方式帮助团队顺利、健康地迈入下一阶段,而不是陷入散伙阶段?
- 问题二
关于动物世界
这部分提到了三种动物猪、鸡、鹦鹉;按照作者的意思,应该是通过投入级别划分成了三种动物,但对于一个团队,一个项目,每个成员的贡献与投入并不完全契合,在我看来决策的权利也不应当由投入程度来分配,我认为决策与其说是一种权利,倒不如说是一项任务,一项职责,应当交付给适合做,有能力做的人。对于一个项目,往往投入最多的猪是工作在底层,日复一日从事类似CRUD工作的程序员,决策这一职责对于他们来说,是不是有些“超纲”了?
当然,文中的鹦鹉是除了一些人云亦云的观点和一些关于架构的空谈之外, 他们没有其他投入的鹦鹉,他也不足以执行决策的职责,那么,如何有一只“长着猪肉的鹦鹉”,提供顶层架构和天才想法的同时,深入项目本身,将决策权交给这样的鹦鹉,会不会比猪更合适?同时,如何才能成为这样的鹦鹉呢?一个成熟的项目经理可以担当这样的鹦鹉吗?
- 问题三
这部分提到了对于工程师能力的评估、发展指标,其中提到了NBA数据统计,我觉得这部分很有意思;
文中提到了通过数据的形式评估衡量工程师的能力,那么,是否所有的能力都能以数据衡量呢?类似编程思想、学习能力这样的软实力,是否能够以数据方式衡量?例如文中提到的NBA,诚然,数据能够一定程度下反映球员的能力,但是任何一种数据都有其缺陷与弊端,用”死“的数据去衡量”活“的球员,难免会有偏差,例如科比·布莱恩特,如果从数据的角度,他也许只是一个某一时代的一流球星,在很多数据榜单上都无法跻身历史级别,但客观的事实确是,他的球员生涯拿下了五个总冠军,也被公认为历史前十级别的超级球员。这一点,是”死“的数据永远得不出的结论。在一个相对客观、以直接竞技论输赢的篮球领域尚且如此,那么在更为主观、评价标准更为复杂的软件领域,数据统计真的就足以衡量工程师的能力吗?
同时,衡量的标准与尺度如何界定?怎么设计相对”客观“的标准呢?
- 问题四
关于创新的迷思
这部分提到了一些大众对于”创新“的误解,我刚看完就有一个问题——那么创新是为了什么呢?
在经过一些思考后,我有一些个人的想法——软件工程乃至大众的工作,都是服务于需求,都是为了解决一部分人(可能是一大群人,也可能是一小群人)的问题。为了解决问题,每一个软件工程从业者都有自己的解决方案。有的人从质量入手,力求写入精美的程序;有的人从创新入手,另辟蹊径走出一条前人没有走过的解决之路。但是不论是求质量还是求创新,根本的目的还是为了解决问题,满足需求,创新,抑或是质量,都是手段,而从来就不是目的。能解决问题、满足需求的创新才是好创新,才是我们需要的创新,不能解决问题,或是大众不需要的创新,与废纸无异。
同时,一个创新在开发者眼中可能是天才之作,但是在用户眼中,可能因为这样那样的问题而一文不值。那么,什么样的创新,才是好创新?如何避免自己眼中的创新,在用户眼里一文不值?怎么样才能让你的创新变为所有人眼中的创新?
- 问题五
关于PSP
其实我对于PSP不是很赞同,PSP中的步骤大多笼统且宽泛,往往与实际开发想去甚远,粗略地估计各项工作的所需时间,在我看来意义好像不是很大;一方面是步骤分得过于笼统,直接导致估计与实际开发相去甚远,往往会发现”计划赶不上变化“;另一方面,这些步骤往往也不是按照表中顺序执行的,甚至很多时候,这些任务都是并行的。那么,PSP的步骤是否可以根据自身需求改变呢?
当然也可能是因为过去开发的都是小型程序,不知道以后从事了大型项目的开发,对于PSP的理解会不会有新的改变。
任务二——WordCount编程
Github项目地址
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 15 |
| • Estimate | • 估计这个任务需要多少时间 | 30 | 15 |
| Development | 开发 | 350 | 435 |
| • Analysis | • 需求分析 (包括学习新技术) | 60 | 45 |
| • Design Spec | • 生成设计文档 | 20 | 15 |
| • Design Review | • 设计复审 | 20 | 40 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 10 | 25 |
| • Design | • 具体设计 | 30 | 25 |
| • Coding | • 具体编码 | 120 | 150 |
| • Code Review | • 代码复审 | 30 | 15 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 60 | 120 |
| Reporting | 报告 | 95 | 115 |
| • Test Report | • 测试报告 | 45 | 60 |
| • Size Measurement | • 计算工作量 | 20 | 10 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 30 | 45 |
| 合计 | 475 | 565 |
解题思路描述
拿到题目后,我从下面几个方面进行了思考和分析
需求分析
-
核心功能:对文本文件的解析——这就涉及了两个主要部分
- 文件的读写(I/O)
- 对内容的解析
-
应用场景
- 命令行
- 单元测试框架
- 与数据可视化部分结合
- .......
结合核心功能和应用场景,这个程序需要完成两个任务——完成核心功能;
将核心功能模块独立出来,适配于各个应用场景
技术分析
- 实现技术
- I/O
- 集合框架的使用
- 异常处理
- 单元测试
性能分析
- 影响程序性能的主要因素
- I/O处理方式的选择
- 集合框架的使用选择
- 算法的选择
在经过分析和自己检视之后,认为自己对I/O流和各集合框架的性能理解不足,因此主要查找了这些方向的资料
代码规范
设计与实现过程
项目架构
我主要从这几个方面进行项目的架构
- 将整个核心模块与其调用方式(命令行、main函数或是其他方式)分离
- 将I/O处理与文本内容的解析分离
- 将文本内容的具体解析规则与功能接口分离(如果需求改变了,例如将单词的规则改为6个字母开头,程序该如何拓展?)
- 将解析规则分为对字符的解析和对单词的解析
故最后的程序分为两个模块,七个文件(两个interface和五个class)
项目架构如图
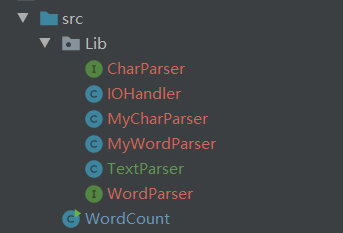
其中,
-
Wordcount为执行文件,即用于本次作业通过命令行调用; -
Lib包为这次核心模块,即需求对应的整套解决方案 -
Lib包下的IOHandler是针对I/O处理的工具类 -
Lib包下的TextParser是针对文本解析的实现类,对文本的解析分为字符解析CharParser和单词解析WordParser两部分 -
Lib包下的MyWordParser和MyCharParser分别实现了字符解析CharParser和单词解析WordParser接口,其解析规则基于本次作业的需求
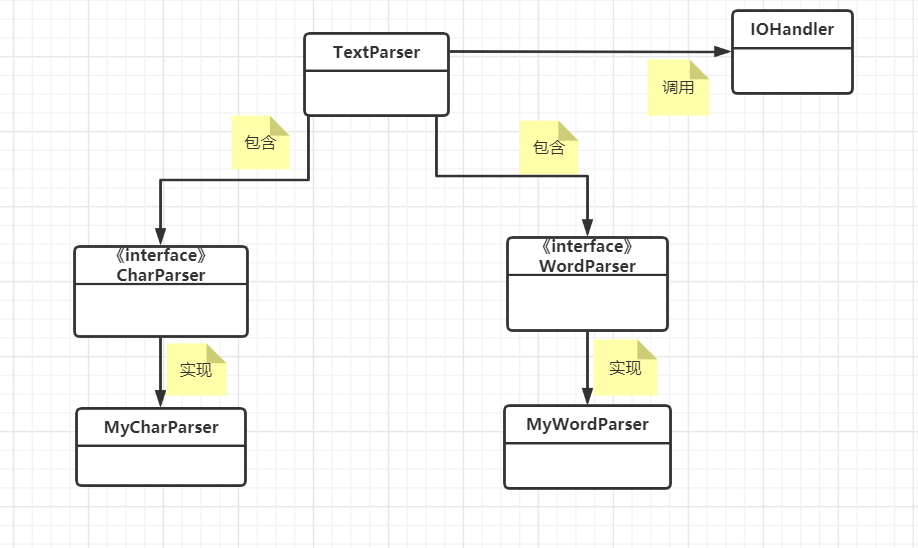
各模块功能介绍
IOHandler
用于I/O处理的工具类;有两个静态方法
readFile和writeToFile
readFile根据用户传入的输入文件路径;读取文本文件的内容,并返回内容字符串writeToFile接收两个参数输出文件路径和输出内容;将指定内容输出至目标路径
TextParser
根据用户提供的解析规则对文本内容进行解析;其中分为字符解析
CharParser和解析WordParser两部分
- 用户需要提供输入文件和输出文件的路径;并给出字符解析规则和单词解析规则
public TextParser(String inputFile,String outputFile,CharParser charParser,WordParser wordParser)
{
this.outputFile = outputFile;
this.inputFile = inputFile;
this.validCharsNum=0;
this.validLinesNum=0;
this.wordNum=0;
this.readFile(); //读取文件内容
this.wordCountMap=new HashMap<>();
this.charParser=charParser; //配置字符解析器
charParser.parseText(textContent); //字符解析器解析文本
this.wordParser=wordParser; //配置单词解析器
}
- TextParser会调用IOHandler的静态方法,读取输入文件的内容,并存入textContent中
public String readFile()
{
return textContent=IOHandler.readFile(inputFile);
}
- TextParser根据题目需求,提供了ASCII字符统计、有效行数统计、单词数量统计、单词频率统计方法;这些方法调用用户配置的字符解析器和单词解析器,进行解析和统计;
/**
* 统计有效ASCII字符
* @return
*/
public int countValidChars()
{
return validCharsNum=charParser.countValidChars();
}
/**
* 统计有效行数
* @return
*/
public int countValidLines()
{
return validLinesNum=charParser.countValidLines();
}
/**
* 统计单词数量
* @return
*/
public int countWordNum()
{
return wordNum=wordParser.countWord(textContent);
}
/**
* 根据size获取单词频率统计map
* @param size
* @return
*/
public Map<String,Integer> getWordCountMapBySize(int size)
{
return wordCountMap=wordParser.getWordCountMapBySize(size);
}
- TextParser调用IOHandler的静态方法;将统计结果输出至目标文件
自认为的亮点:将各功能与具体实现分离;用户可以根据不同的解析、统计规则,配置不同的解析器;从而降低了代码的耦合度,增加了可扩展性
CharParser
CharParser接口定义了解析文本、统计有效字符、统计有效行数的方法;用户可以通过实现该接口,自定义解析和统计的规则
/**
* 解析文本;解析后进行统计
* @return
*/
String parseText(String text);
/**
* 统计有效字符
* @return
*/
int countValidChars();
/**
* 统计有效行数
* @return
*/
int countValidLines();
MyCharParser
根据本次作业需求编写的
CharParser实现类
- 解析文本
遍历文本内容,判断是否为ASCII码,删去所有非ASCII码的字符
StringBuilder sb=new StringBuilder(); //保存解析结果
for (int i=0;i<text.length();i++)
{
c = text.charAt(i);
if (isCharValid(c)) //判断是否为有效字符(在这里指ASCII码)
{
sb.append(c); //若有效则加入stringbulider
}
}
- 统计有效字符
返回解析后文本的长度
- 统计有效行数
遍历解析后的文本,用一个标志位isLineHasChar判断当前读的行是否有非空白字符;
每当读到换行或是文本结束,检查一次isLineHasChar,若当前行有非空白字符,则计数+1;检查后重置标志位
if(c!='\t'||c!='\r'||c!='\n'||c!=' ') //非空白字符
{
isLineHasChar=true;
}
if(c=='\n'||i==textContent.length()-1) //遇到换行或文本内容结束
{
if(isLineHasChar==true) //若改行有非空字符
{
num++; //计数
isLineHasChar=false; //重置标志位
}
}
WordPaser
WordPaser接口定义了解析并统计单词、获取单词统计map中前n位的方法;;用户可以通过实现该接口,自定义解析和统计的规则
/**
* 解析并统计单词
* @return
*/
int countWord(String text);
/**
* 获取单词统计map中前size位
* @return
*/
Map<String, Integer> getWordCountMapBySize(int size);
MyWordparser
根据本次作业需求编写的
WordParser实现类
-
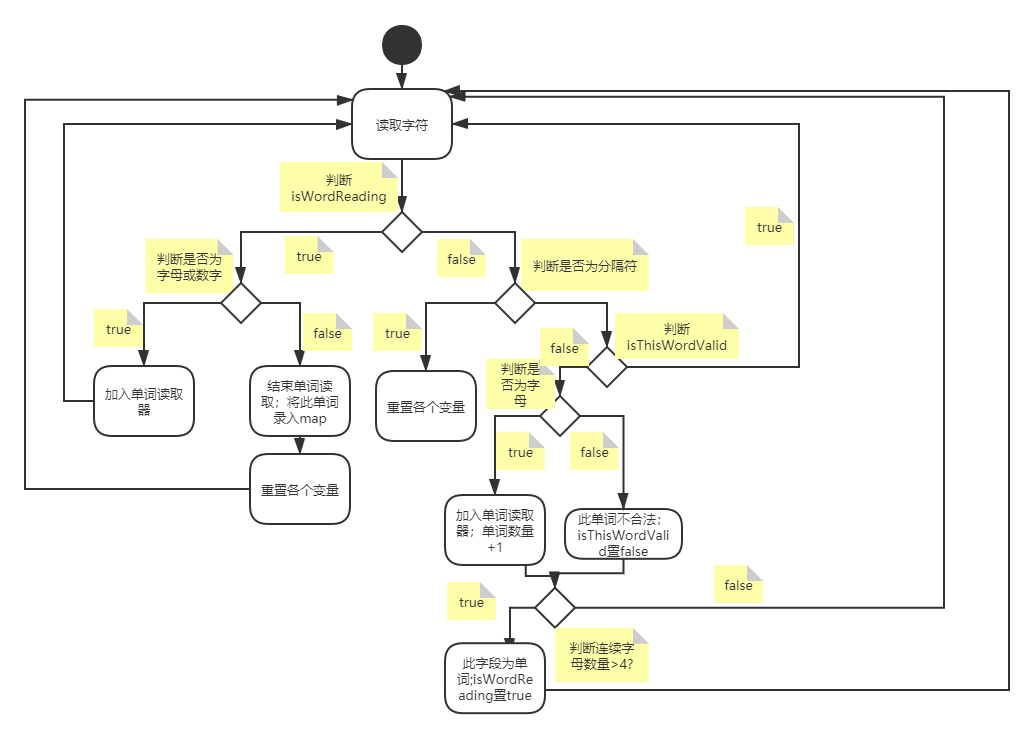
解析并统计单词
定义:两个分隔符之间的字符为一个字段
-
设置:
-
一个int类型变量
letterNum记录连续读取的字母数量;一个读词器StringBuilder保存这些连续读取的字母 -
两个标志位
isWordReading和isThisWordValid用来辅助判断; -
isWordReading表示当前字段是否为单词;当前字段为单词时,字母和数字都加入读词器,若当前字段暂时还不满足单词条件,只有字母才能加入读词器
if(isWordReading) //正在读取单词 { if(isValidChar(c)) //若是有效字符 { wordReader.append(c); //加入单词读取器 } else //否则 { num=recordWord(num); //将单词记入map;并统计数量 endThisWordReading(); //结束本单词的读取;重置标志位;开始读取下一单词 } }isThisWordValid表示当前字段是否合法;若当前字段已经不合法(即已不可能满足单词条件),则跳过读取任何字段,直到读到分隔符,重置各个标志位,开始读取下一字段
if(!isValidChar(c)) //若为分隔符 { endThisWordReading(); //结束本单词的读取;重置标志位;开始读取下一单词 continue; } if(!isThisWordValid) //若此单词已不合法 { continue; } if(isLetter(c)) //若为字母 { wordReader.append(c); //加入单词读取器 letterNum++; //字母数量+1 } else { isThisWordValid=false; //此单词不合法;将合法位置false } if(letterNum>=4) //连续字母数量超过4个 { isWordReading=true; //开始读取单词 } -
流程图:
- 获取单词统计map中前n位
根据用户传入的参数size;选取单词记录map中频率最高的前n位;
借鉴了博客https://segmentfault.com/a/1190000020276225的写法,采用了链式编程的方式
return wordCountMap
.entrySet()
.stream()
.sorted(Map.Entry.<String, Integer> comparingByValue() //按value排序(默认为升序)
.reversed()//倒序
.thenComparing(Map.Entry.comparingByKey()))//按照key排序(字典序)
.limit(size) //选择前面n个
.collect( //以map形式返回
Collectors.toMap(Map.Entry::getKey,Map.Entry::getValue,
(oldValue, newValue) -> oldValue,
LinkedHashMap::new //返回LinkedHashMap
)
);
性能改进
我认为这个项目在性能上主要有两个方面可以改进——I/O与集合框架的选择;解析统计文本的算法
- I/O选择
最早选用的是FileInputStream和FileOutputStream,后来改用了带缓存的BufferedReader和BufferWriter;
BufferedReader和BufferWriter没有阻塞问题,提高了I/O效率
- 集合框架选择
对于单词统计map的排序,在参考了别人的博客后,选择用stream流式编程的方式进行排序
- 算法
这方面提升得不多;主要是两个方面——一个是将I/O和文本解析拆分后,只需要读取一次文件,代替了之前的多次读取;另一个是统计单词时,一边统计频率一边统计数量,将频率和数量都用变量存起来,统计的接口直接返回这两个变量即可
- 运行1.4亿个字符的程序耗时

单元测试
测试代码
单元测试通过固定的输入输出路径,调用核心模块的各个方法进行测试;
- countValidChars方法测试示例
public class Test
{
private static TextParser textParser =new TextParser("D:\\DeskTop\\input.txt",
"D:\\DeskTop\\output.txt",
new MyCharParser(),new MyWordParser());
public static void countValidCharsTest()
{
textParser.countValidChars();
textParser.writeToFile();
}
}
覆盖率
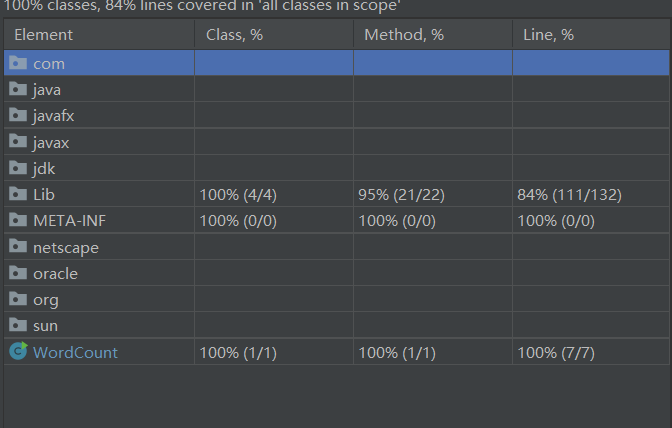
测试数据思路
-
单词测试思路
- 4个字母的合法单词
- 3个字母的非法单词
- 字母与数字混合的非法单词
- 字母与数字混合的合法单词
- 空字符开头
- 空字符结尾
-
有效行测试思路
- 空字符开头
- 空字符结尾
- 文件结尾部分
- 连续多行空字符
- 连续多个换行
- 字符+空白字符+换行
-
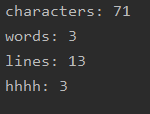
测试样例及结果
hhhh
hhh
1hhh
hhh1hhh
hhhh
hhh
hhhh
h hhhh
hhh
1hhh
hhh1hhh
hhhh
hhh
hhhh
h
异常处理说明
文件输入异常
catch (FileNotFoundException e)
{
e.printStackTrace();
System.out.println("无法找到该路径下的文件!!!");
}
catch (IOException e)
{
e.printStackTrace();
System.out.println("文件内容读取异常!!!");
}
文件输出异常
catch (FileNotFoundException e)
{
e.printStackTrace();
System.out.println("无法找到该路径下的文件!!!");
}
catch (UnsupportedEncodingException e)
{
e.printStackTrace();
System.out.println("不支持的编码类型!!!");
}
catch (IOException e)
{
e.printStackTrace();
System.out.println("IO异常!!!");
}
命令行参数数量异常
if(args.length!=2)
{
System.out.println("参数数量应为2个!!!");
return;
}
心路历程与收获
心路历程
整个项目开发过程中思考最多的就是如何让代码可移植性更强,耦合度更低,所以一遍又一遍重构代码,从两个类慢慢变成了七个类;在不断重构的过程,一直在思考耦合度、可移植性和性能之间的取舍,一开始没有把文本解析拆分成字符解析和单词解析,解析1.4亿个字符的文件只需要8s多,将文本解析拆分后,虽然降低了耦合度,也提高了复用性和拓展性,但运行时间提高到了10s左右,牺牲了部分的性能;所以在这二者之间的取舍我还没有很好的想法,希望在未来的开发和实践中能进一步思考,有所收获吧
收获
-
从开发的准备阶段,就应该做好项目的架构工作,并对其功能、要解决的问题、可能遇到的问题有所预期;这样才不会出现这次反复修改架构的情况
-
项目的测试非常重要

