
一、环境准备
ps:必须注意版本:python3.5.x 和spark1.6、spark2.2才兼容。
1、python下载
https://www.python.org/downloads/windows/
下载windows的执行安装包python3.5,按提示安装好,打开python3.5的目录。进入
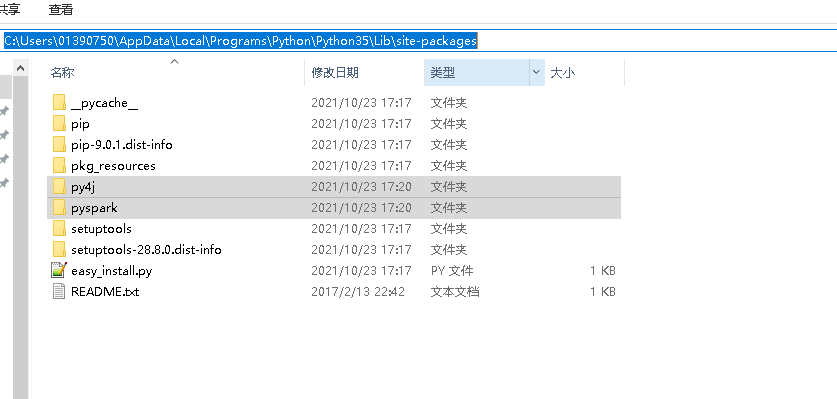
C:\Users\01390750\AppData\Local\Programs\Python\Python35\Lib\site-packages
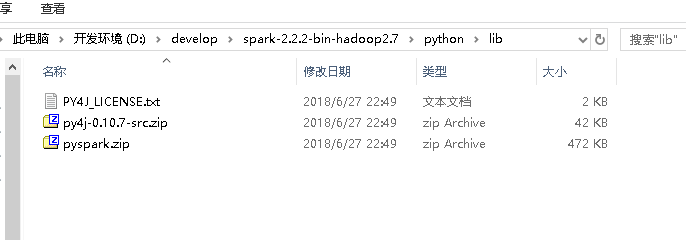
将pyspark依赖加入到python3.5环境。我用的是spark2.2(D:\develop\spark-2.2.2-bin-hadoop2.7\python\lib)
2、IDEA环境
2.1 安装python插件
https://plugins.jetbrains.com/plugin/631-python/versions
从官网下载IDEA对应版本的python插件 (IDEA的help -> About 查看版本)
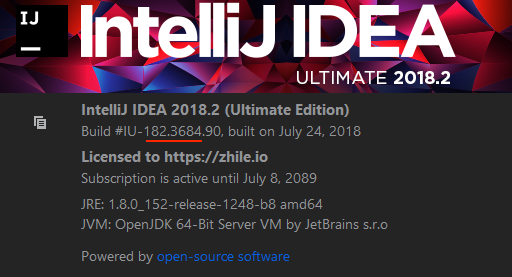
我下载的是 python-2018.2.182.3684.101.zip
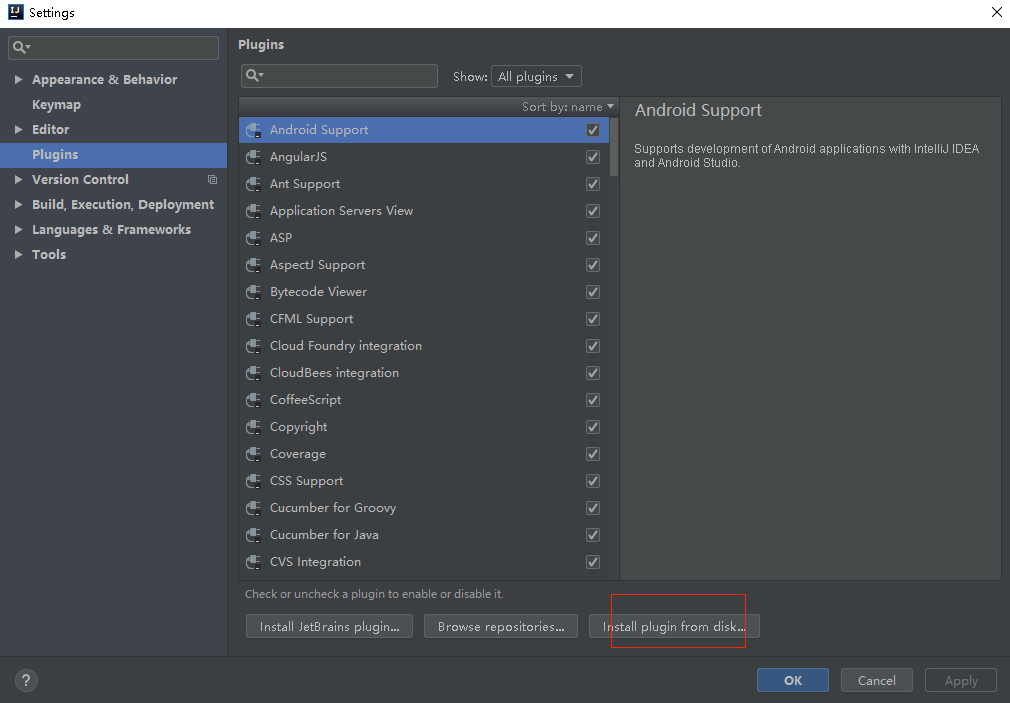
2.2 进入IDEA的setting,找到plugin,选择本地安装插件方式,找到“”python-2018.2.182.3684.101.zip“” ,自动安装后重启IDEA即可创建python的IDEA编程环境.
3、创建python项目
3.1 File -》New Project -》 python -》 选择python3.5编译环境 -》 next -》
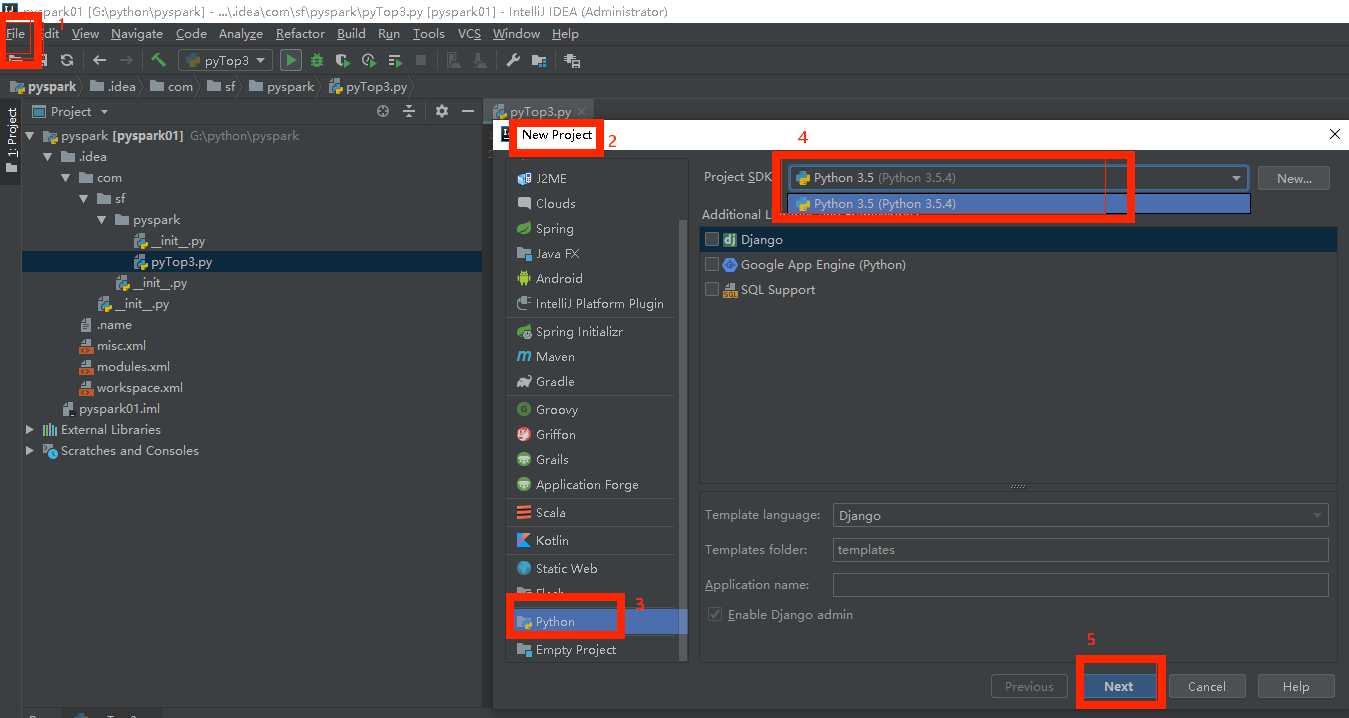
3.2 选择项目目录,需要的话创建一个目录与项目同名
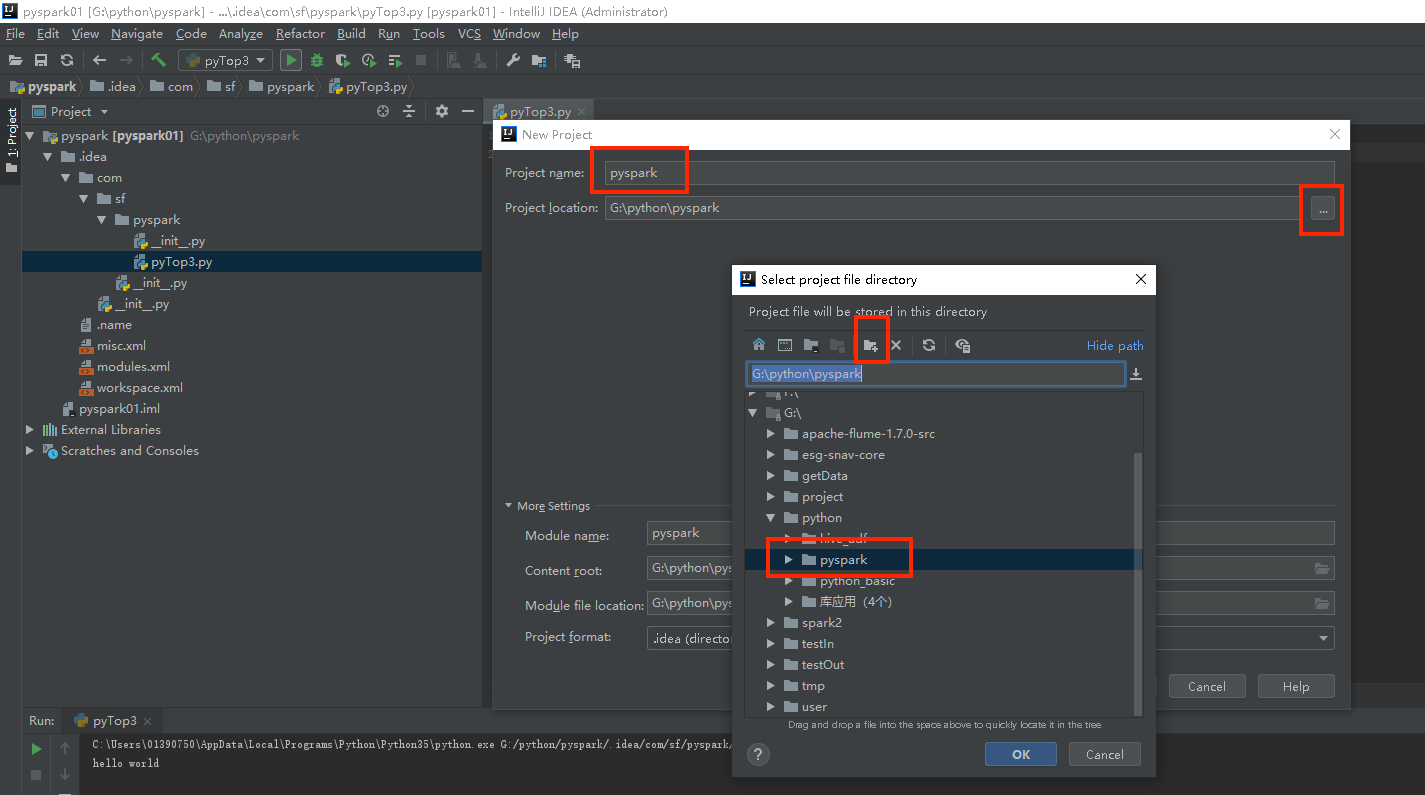
3.3 编写项目,创建python package包
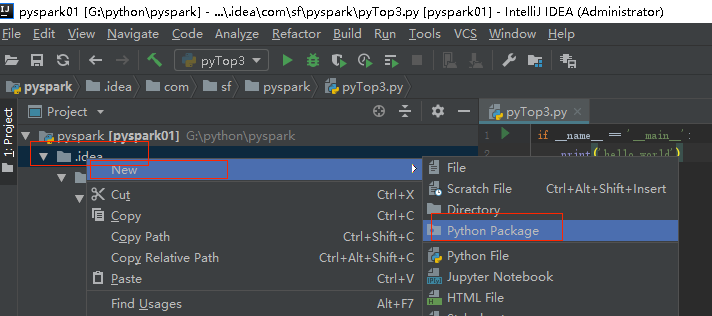
3.4 编辑python代码

4、python开发spark的问题
1) 关于安装路径
jdk,anaconda及python的安装路径中不能有空格和中文。
2) 指定spark使用的python版本
如果使用的anaconda更换了python3.5.x版本,之后在开发工具中指定了python解析器为3.5.x版本之后,运行python spark 代码时spark默认的使用的python版本使环境变量中指定的版本。会导致与指定的python解析器的python版本不一致。这时需要在环境变量中指定下PYSPARK_PYTHON环境变量即可,值为指定的python3.5.x python解析器路径。如:C:\Users\AppData\Local\Programs\Python\Python35\python.exe

3) python依赖jar包的指定
python开发spark中有可能用到外部的jar包,那么在本地测试可以通过Run As -> Run Configuration->Environment来设置SPARK_CLASSPATH 指定依赖的jar包:
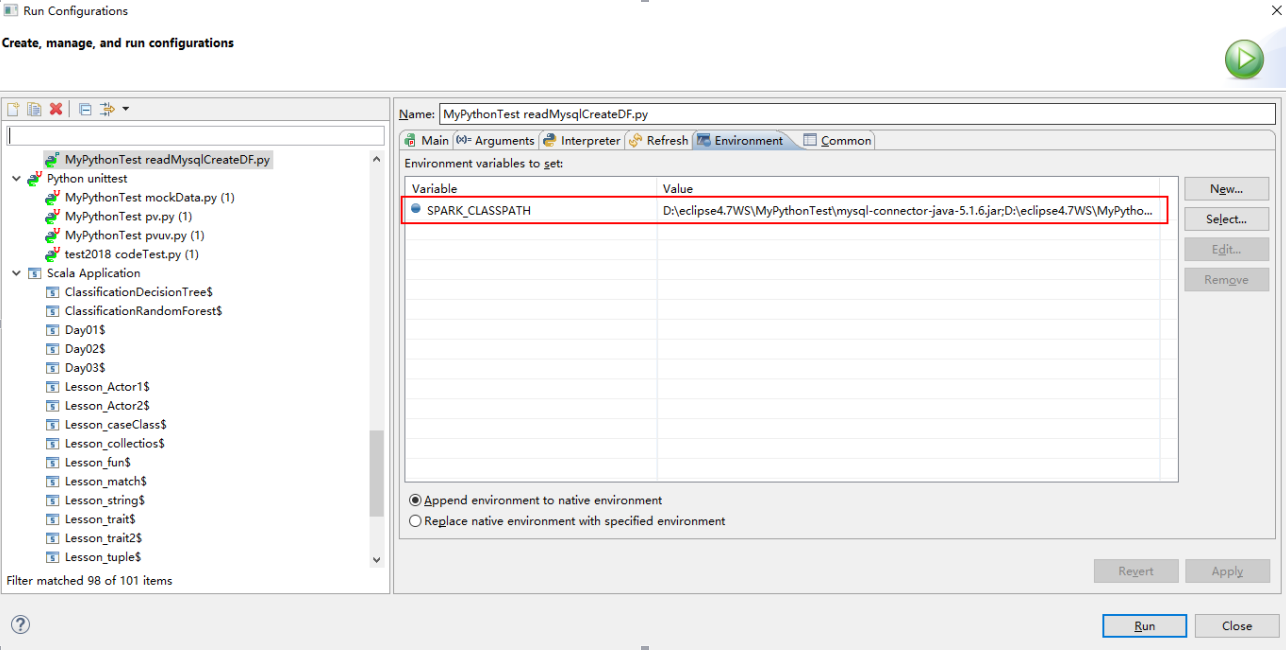
如果在集群中提交任务,需要指定依赖的jar包,可以通过--jars或者—driver-class-path来指定依赖的jar包。也可以在集群spark中../conf/spark-defaults.conf中设置变量spark.driver.extraClassPath或者spark.executor.extraClassPath来指定pySpark依赖的jar包。
例如:如果使用python来开发SparkStreaming Application 还需要在进行如下配置:
在conf目录的spark-default.conf目录下添加两行配置信息
① spark.driver.extraClassPath F:/spark-1.6.0-bin-hadoop2.6/lib/spark-streaming-kafka-assembly_2.10-1.6.0.jar
② spark.executor.extraClassPath F:/spark-1.6.0-bin-hadoop2.6/lib/spark-streaming-kafka-assembly_2.10-1.6.0.jar

 浙公网安备 33010602011771号
浙公网安备 33010602011771号