
matplotlib可视化库---接口文档
https://matplotlib.org/stable/api/pyplot_summary.html
1、失业率数据
import pandas as pd unrate = pd.read_csv('unrate.csv')
# pd.to_datetime() 将int、float、str、datetime类型等数据转换为datetime unrate['DATE'] = pd.to_datetime(unrate['DATE']) #help(pd.to_datetime) unrate.head(12)

2、折线图:plt.plot(x,y) / plt.show() 使用不同的pyplot函数,我们可以创建、自定义和显示图形
import matplotlib.pyplot as plt # 使用不同的pyplot函数,我们可以创建、自定义和显示图形。 plt.plot() plt.show() #help(plt.plot) #help(plt.show) #help(plt.xticks)

3、折线图:plt.plot(x,y) 传入x,y对应的数据 plt.xticks(rotation=45) x坐标,文字45度
plt.xlabel('x坐标名')
plt.ylabel('y坐标名')
plt.title('图标题名')
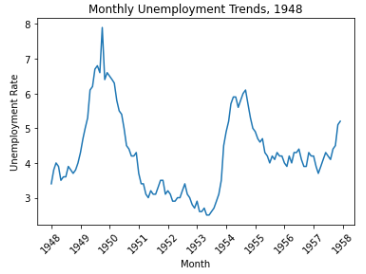
first_twelve = unrate[0:120] # plt.plot(x,y) 传入x,y对应的数据 plt.plot(first_twelve['DATE'], first_twelve['VALUE']) # x坐标,文字45度 plt.xticks(rotation=45) plt.xlabel('Month') plt.ylabel('Unemployment Rate') plt.title('Monthly Unemployment Trends, 1948') plt.show()
4、plt.figure(figsize=(10, 10))定义子图尺寸
import numpy as np
fig = plt.figure()
# plt.figure(figsize=(10, 10))定义子图尺寸
fig = plt.figure(figsize=(10, 10))
ax1 = fig.add_subplot(2,1,1)
ax2 = fig.add_subplot(2,1,2)
ax1.plot(np.random.randint(1,5,5), np.arange(5))
ax2.plot(np.arange(10)*3, np.arange(10))
plt.show()
5、figure.add_subplot(a,b,index) 构图函数,a*b个子图,a表示行,b表示列,index表示第几个
# figure.add_subplot(a,b,index) 构图函数,a*b个子图,a表示行,b表示列,index表示第几个 import matplotlib.pyplot as plt fig = plt.figure() # matplotlib.figure.Figure
# fig = plt.figure(figsize=(10,6)) # matplotlib.figure.Figure
type(fig) # matplotlib.figure.Figure # 3 * 2 个子图 # ax1位于第1个子图 ax1 = fig.add_subplot(3,2,1) # ax2位于第3个子图 ax2 = fig.add_subplot(3,2,3) # ax3位于第6个子图 ax3 = fig.add_subplot(3,2,6) plt.show()

6、折线图:plt.plot(x1, y1, c='colorName') plt.plot(x2, y2, c='colorName') 两个部分
unrate['MONTH'] = unrate['DATE'].dt.month # 定义图的尺寸 fig = plt.figure(figsize=(8,4)) # 第一年的月失业率,红色的线 plt.plot(unrate[0:12]['MONTH'], unrate[0:12]['VALUE'],c='red') # 第二年的月失业率,蓝色的线 plt.plot(unrate[12:24]['MONTH'],unrate[12:24]['VALUE'],c='blue') plt.show()
7、不同年份用不同颜色表示:1:红 2:蓝 3:绿 4:橙 5:黑
# 定义图的尺寸 fig = plt.figure(figsize=(12,6)) # 不同年份用不同颜色表示:1:红 2:蓝 3:绿 4:橙 5:黑 colors = ['red', 'blue', 'green', 'orange', 'black'] #[0:4] for i in range(5): # 按12行,进行数据分片 start_index = i * 12 end_index = (i + 1) * 12 subset = unrate[start_index:end_index] # 将每个数据分片,填充plot画图,MONTH作为x坐标值,VALUE作为y坐标值,颜色从colors中轮训 plt.plot(subset['MONTH'], subset['VALUE'], c=colors[i]) plt.show()
8、plt.legend(loc='xxx') 在坐标轴上显示标签注释图例
# 定义图的尺寸 fig = plt.figure(figsize=(12,6)) # 不同年份用不同颜色表示:1:红 2:蓝 3:绿 4:橙 5:黑 colors = ['red', 'blue', 'green', 'orange', 'black'] #[0:4] for i in range(5): # 按12行,进行数据分片 start_index = i * 12 end_index = (i + 1) * 12 subset = unrate[start_index:end_index] # 为每个颜色的线命名 label = str(1948 + i) # 将每个数据分片,填充plot画图,MONTH作为x坐标值,VALUE作为y坐标值,颜色从colors中轮训 plt.plot(subset['MONTH'], subset['VALUE'], c=colors[i],label=label) # plt.legend(loc='xxx') 在坐标轴上显示标签注释图例 #plt.legend(loc='best') plt.legend(loc='upper left' ) plt.show() #help(plt.legend)
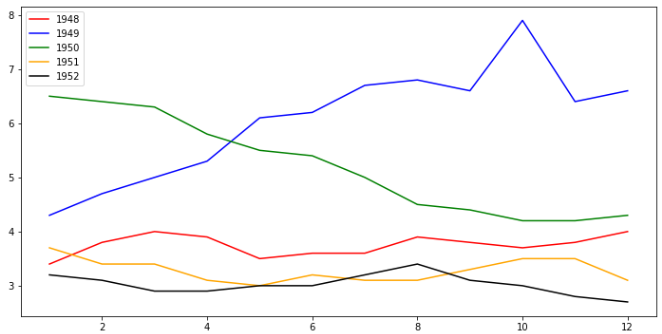
9、plt.legend(loc='xxx') 在坐标轴上显示注释图例 ; plt.xlabel(name)x轴名 ; plt.ylabel(name) y轴名 ; plt.title(name) 坐标轴名
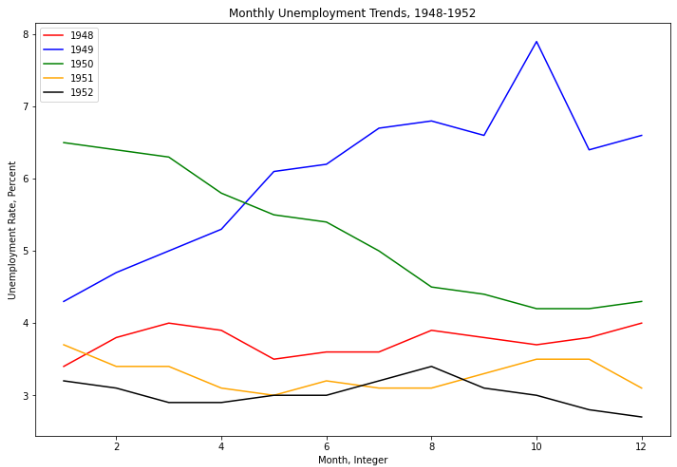
fig = plt.figure(figsize=(12, 6)) colors = ['red', 'blue', 'green', 'orange', 'black'] for i in range(5): # 按12行,进行数据分片 start_index = i * 12 end_index = (i + 1) * 12 subset = unrate[start_index: end_index] # 为每个颜色的线命名 label = str(1948 + i) # 将每个数据分片,填充plot画图,MONTH作为x坐标值,VALUE作为y坐标值,颜色从colors中轮训 plt.plot(subset['MONTH'], subset['VALUE'], c=colors[i], label=label) # plt.legend(loc='xxx') 在坐标轴上显示标签注释图例 plt.legend(loc='upper left') # x轴名 plt.xlabel('Month, Integer') # y轴名 plt.ylabel('Unemployment Rate, Percent') # plt.title('图名') 坐标轴名 plt.title('Monthly Unemployment Trends, 1948-1952') plt.show()
10、ax.bar()在柱形图中,展示第一部电影的各项分数
import pandas as pd reviews = pd.read_csv('fandango_scores.csv') cols = ['FILM', 'RT_user_norm', 'Metacritic_user_nom', 'IMDB_norm', 'Fandango_Ratingvalue', 'Fandango_Stars'] norm_reviews = reviews[cols] #print(reviews.head(3)) # 第一部电影的各项分数 norm_reviews[:1]

import matplotlib.pyplot as plt from numpy import arange num_cols = ['RT_user_norm', 'Metacritic_user_nom', 'IMDB_norm', 'Fandango_Ratingvalue', 'Fandango_Stars'] # 取出第一行,所有数值 bar_heights = norm_reviews.loc[0, num_cols].values # array([4.3, 3.55, 3.9, 4.5, 5.0], dtype=object) #bar_positions = arange(5) + 0.75 # array([0.75, 1.75, 2.75, 3.75, 4.75]) bar_positions = [0.3, 1.5, 3.0, 3.5, 8] # x坐标 # help(plt.subplots) # fig,axs = plt.subplots(nrows=1, mcols=1) 创建n行m列的子图集,默认生成一个子图 fig, ax = plt.subplots() # ax.bar(x,height,width=0.8) 条形图/柱形图 #help(ax.bar) ax.bar(bar_positions,bar_heights,0.3) # 柱形图的x坐标位置,柱形高度,柱形宽度0.3 plt.show() # help(plt)
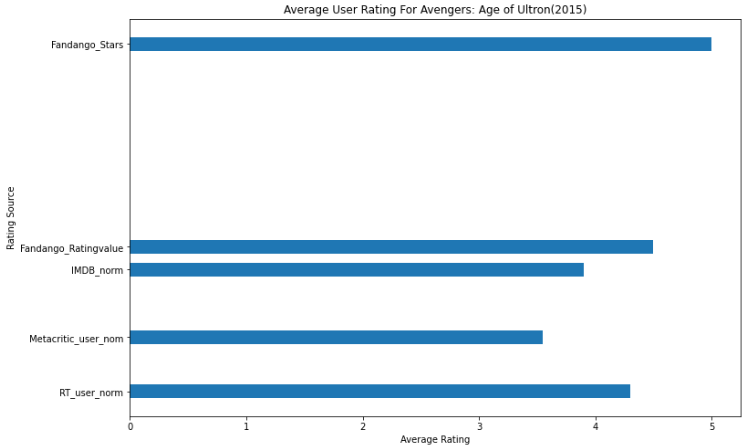
11、ax.bar(x,height,width=0.8) 柱形图:x坐标位置,柱形高度,柱形宽度0.3
ax.set_xticks(lst) 设置记号x坐标的位置:x轴上的一个记号
ax.set_xticklabels 设置字符串标签记号的x坐标,标签倾斜45度
ax.set_xlabel('x_name') 设置x坐标名
ax.set_ylabel('y_name') 设置y坐标名
ax.set_title('Avengers: Age of Ultron (2015)电影的平均用户评分')
fig.set_size_inches((w, h)) 设置子图尺寸(W宽,h高)
num_cols = ['RT_user_norm', 'Metacritic_user_nom', 'IMDB_norm', 'Fandango_Ratingvalue', 'Fandango_Stars'] # 柱形的高度 bar_heights = norm_reviews.loc[0, num_cols].values # array([4.3, 3.55, 3.9, 4.5, 5.0], dtype=object) # 柱形的x坐标位置 bar_positions = [0.3, 1.5, 3.0, 3.5, 8] # 记号的x坐标位置 #tick_positions = range(1,6) tick_positions = [0.3, 1.5, 3.0, 3.5, 8] # fig, axs = plt.subplots(nrows=1, mcols=1) 创建n行m列的子图集,默认生成一个子图 # fig 设置子图尺寸 # ax 填充数据,及子图样式 fig, ax = plt.subplots() # fig.set_size_inches((w, h)) 设置子图尺寸(W宽,h高) fig.set_size_inches((12,8)) # ax.bar(x,height,width=0.8) 柱形图:x坐标位置,柱形高度,柱形宽度0.3 ax.bar(bar_positions, bar_heights, 0.3) # ax.set_xticks(lst) 设置记号x坐标的位置:x轴上的一个记号 ax.set_xticks(tick_positions) # ax.set_xticklabels 设置字符串标签记号的x坐标,标签倾斜45度 ax.set_xticklabels(num_cols, rotation=45) # ax.set_xlabel('x_name') 设置x坐标名 ax.set_xlabel('Rating Source') # ax.set_ylabel('y_name') 设置y坐标名 ax.set_ylabel('Average Rating') # ax.set_title('Avengers: Age of Ultron (2015)电影的平均用户评分') ax.set_title('Avengers: Age of Ultron (2015)') plt.show()

12、ax.barh() 横向柱形图
import matplotlib.pyplot as plt from numpy import arange num_cols = ['RT_user_norm', 'Metacritic_user_nom', 'IMDB_norm', 'Fandango_Ratingvalue', 'Fandango_Stars'] # 对比第一部电影的各项分数: 横向展示分数高低情况,纵向各项指标名 bar_widths = norm_reviews.loc[0, num_cols] # 纵向y坐标位置:各项指标名的位置 bar_positions = [0.3, 1.5, 3.0, 3.5, 8] tick_positions = [0.3, 1.5, 3.0, 3.5, 8] # fig, axs = plt.subplots(nrows=1, mcols=1) 创建n行m列的子图集,默认生成一个子图 # fig 设置子图尺寸 # ax 填充数据,及子图样式 fig, ax = plt.subplots() # fig.set_size_inches((w, h)) 设置子图尺寸(W宽,h高) fig.set_size_inches((12,8)) # ax.barh(y, width) 横向柱形图 ax.barh(bar_positions, bar_widths, 0.3) # ax.set_yticks(tick_positions) 设置y轴标签位置 ax.set_yticks(tick_positions) # ax.set_yticklabels(num_cols) 设置y轴标签名 ax.set_yticklabels(num_cols) # ax.set_ylabel('Rating Source') 设置y轴名 ax.set_ylabel('Rating Source') # ax.set_xlabel('Average Rating') 设置x轴名 ax.set_xlabel('Average Rating') # ax.set_title('子图标题') 设置子图标题名字 ax.set_title('Average User Rating For Avengers: Age of Ultron(2015)') plt.show
13、 ax.scatter(x, y) 散点图
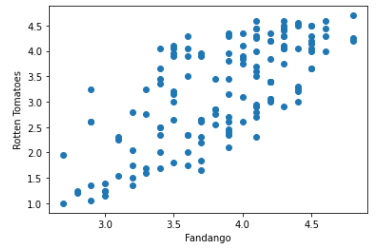
fig, ax = plt.subplots() # help(ax.scatter) # ax.scatter(x, y) 散点图: 影评分作为x,用户评分作为y ax.scatter(norm_reviews['Fandango_Ratingvalue'], norm_reviews['RT_user_norm']) # ax.set_xlabel('x_name') 设置x轴名字 ax.set_xlabel('Fandango') # ax.set_ylabel('y_name') 设置y轴名字 ax.set_ylabel('Rotten Tomatoes') plt.show()
# plt.figure(figsize=(5, 10))创建一个图形,定义子图尺寸 fig = plt.figure(figsize=(8, 16)) # fig.add_subplot(n, m, x) 定义图形,有n行m列的子图,添加一个子图位于第x个位置 ax1 = fig.add_subplot(2, 1, 1) # fig.add_subplot(2, 1, 2) 定义图形,有2行1列的子图,添加一个子图位于第2个位置 ax2 = fig.add_subplot(2, 1, 2) # ax1散点图:数据填充x和y轴数据 ax1.scatter(norm_reviews['Fandango_Ratingvalue'], norm_reviews['RT_user_norm']) # ax1散点图:设置x轴名字 ax1.set_xlabel('Fandango') # ax1散点图:设置y轴名字 ax1.set_ylabel("Rotten Tomatoes") # ax2散点图: 填充x和y轴数据。对调ax1的xy轴 ax2.scatter(norm_reviews['RT_user_norm'], norm_reviews['Fandango_Ratingvalue']) # ax2散点图:设置x轴名字。对调ax1的xy轴 ax2.set_xlabel("Rotten Tomatoes") # ax2散点图:设置y轴名字。对调ax1的xy轴 ax2.set_ylabel("Fandango") plt.show()
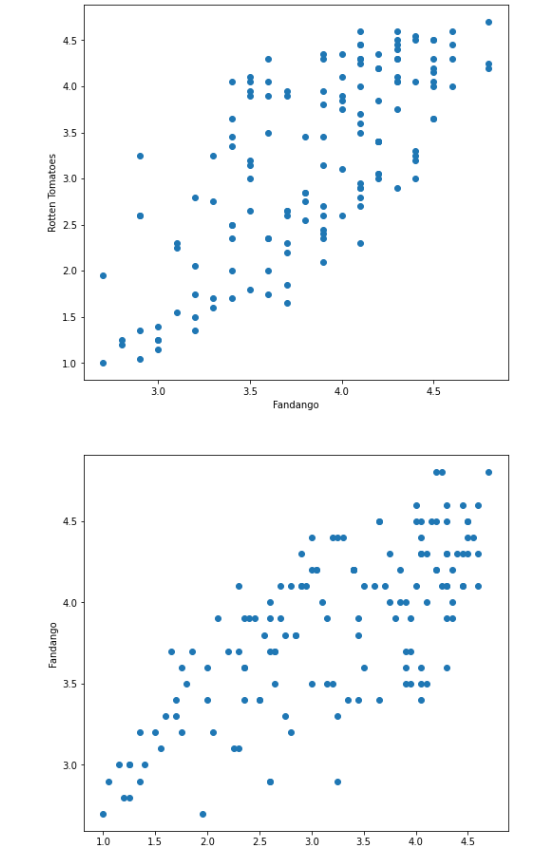
# fig, axs = plt.subplots(nrows=1, mcols=1) 创建n行m列的子图集,默认生成一个子图 fig,(ax1, ax2) = plt.subplots(2,1) # fig.set_size_inches((w, h)) 设置子图尺寸(W宽,h高) fig.set_size_inches((12,8)) # ax1散点图:数据填充x和y轴数据 ax1.scatter(norm_reviews['Fandango_Ratingvalue'], norm_reviews['RT_user_norm']) # ax1散点图:设置x轴名字 ax1.set_xlabel('Fandango') # ax1散点图:设置y轴名字 ax1.set_ylabel("Rotten Tomatoes") # ax2散点图: 填充x和y轴数据。对调ax1的xy轴 ax2.scatter(norm_reviews['RT_user_norm'], norm_reviews['Fandango_Ratingvalue']) # ax2散点图:设置x轴名字。对调ax1的xy轴 ax2.set_xlabel("Rotten Tomatoes") # ax2散点图:设置y轴名字。对调ax1的xy轴 ax2.set_ylabel("Fandango") plt.show()

14、ax.hist(x, 20)用于绘制直方图
直方图(Histogram),又称质量分布图,是一种统计报告图,由一系列高度不等的纵向条纹或线段表示数据分布的情况。 一般用横轴表示数据类型,纵轴表示分布情况。
直方图是数值数据分布的精确图形表示。 这是一个连续变量(定量变量)的概率分布的估计,并且被卡尔·皮尔逊(Karl Pearson)首先引入。它是一种条形图。 为了构建直方图,第一步是将值的范围分段,即将整个值的范围分成一系列间隔,然后计算每个间隔中有多少值。 这些值通常被指定为连续的,不重叠的变量间隔。 间隔必须相邻,并且通常是(但不是必须的)相等的大小。
import pandas as pd import matplotlib.pyplot as plt reviews = pd.read_csv('fandango_scores.csv') cols = ['FILM', 'RT_user_norm', 'Metacritic_user_nom', 'IMDB_norm', 'Fandango_Ratingvalue'] norm_reviews = reviews[cols] norm_reviews[:5] # Series.value_counts(): 每个值有在该列中有多少重复值。 fandango_distribution = norm_reviews['Fandango_Ratingvalue'].value_counts() # Series.sort_index() 按索引排序,默认升序 fandango_distribution = fandango_distribution.sort_index() imdb_distribution = norm_reviews['IMDB_norm'].value_counts() imdb_distribution = imdb_distribution.sort_index() print(fandango_distribution) print(imdb_distribution)
2.7 2 2.8 2 2.9 5 3.0 4 3.1 3 3.2 5 3.3 4 3.4 9 3.5 9 3.6 8 3.7 9 3.8 5 3.9 12 4.0 7 4.1 16 4.2 12 4.3 11 4.4 7 4.5 9 4.6 4 4.8 3 Name: Fandango_Ratingvalue, dtype: int64 2.00 1 2.10 1 2.15 1 2.20 1 2.30 2 2.45 2 2.50 1 2.55 1 2.60 2 2.70 4 2.75 5 2.80 2 2.85 1 2.90 1 2.95 3 3.00 2 3.05 4 3.10 1 3.15 9 3.20 6 3.25 4 3.30 9 3.35 7 3.40 1 3.45 7 3.50 4 3.55 7 3.60 10 3.65 5 3.70 8 3.75 6 3.80 3 3.85 4 3.90 9 3.95 2 4.00 1 4.05 1 4.10 4 4.15 1 4.20 2 4.30 1 Name: IMDB_norm, dtype: int64
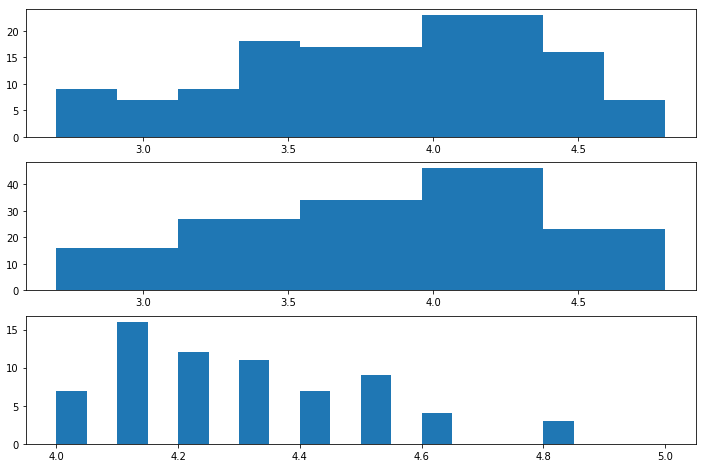
fig, (ax1,ax2,ax3) = plt.subplots(3,1) # fig.set_size_inches((w, h)) 设置子图尺寸(W宽,h高) fig.set_size_inches((12,8)) # ax.hist(x, 20)用于绘制直方图 # ax.hist(a,bins=10,range=None,weights=None,density=False); # a是待统计数据的数组; # bins指定统计的区间个数; # range是一个长度为2的元组,表示统计范围的最小值和最大值,默认值None, # 表示范围由数据的范围决定 # weights为数组的每个元素指定了权值,histogram()会对区间中数组所对应的权值进行求和 # density为True时,返回每个区间的概率密度;为False,返回每个区间中元素的个数 ax1.hist(norm_reviews['Fandango_Ratingvalue']) ax2.hist(norm_reviews['Fandango_Ratingvalue'],bins=5) ax3.hist(norm_reviews['Fandango_Ratingvalue'], range=(4, 5),bins=20) plt.show()
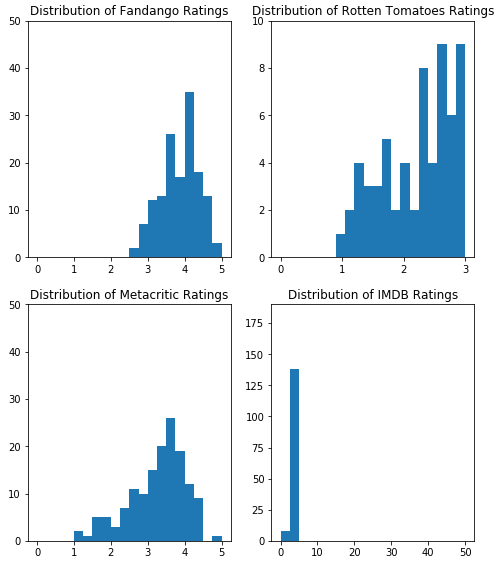
#help(ax1.hist) fig = plt.figure(figsize=(8, 20)) ax1 = fig.add_subplot(4,2,1) ax2 = fig.add_subplot(4,2,2) ax3 = fig.add_subplot(4,2,3) ax4 = fig.add_subplot(4,2,4) # ax.hist()绘制直方图 ax1.hist(norm_reviews['Fandango_Ratingvalue'], bins=20, range=(0,5)) # ax.set_title 设置图标题 ax1.set_title('Distribution of Fandango Ratings') # ax.set_xlim, ax.set_ylim 设置x,y轴的数据范围限制 ax1.set_ylim(0, 50) # ax2.hist(norm_reviews['RT_user_norm'], 20, range=(0,3)) ax2.set_title('Distribution of Rotten Tomatoes Ratings') ax2.set_ylim(0,10) ax3.hist(norm_reviews['Metacritic_user_nom'], 20, range=(0,5)) ax3.set_title('Distribution of Metacritic Ratings') ax3.set_ylim(0, 50) ax4.hist(norm_reviews['IMDB_norm'], 20, range=(0,50)) ax4.set_title('Distribution of IMDB Ratings') ax4.set_ylim(0, 190) plt.show()
15、Axes.boxplot() 箱形图
它由五个数值点组成:最小值(min),下四分位数(Q1),中位数(median),上四分位数(Q3),最大值(max)。也可以往盒图里面加入平均值(mean)。
fig, ax = plt.subplots() type(norm_reviews['RT_user_norm']) # pandas.core.series.Series # ax.boxplot() 箱线图 ax.boxplot(norm_reviews['RT_user_norm']) # ax.set_xticklabels(str_list) 设置x刻度标签名 ax.set_xticklabels(['Rotten Tomatoes']) #help(ax.set_xticklabels) ax.set_ylim(0,5) plt.show()

fig = plt.figure(figsize=(10,8)) ax = fig.add_subplot(1,1,1) # 数据 num_cols = ['RT_user_norm', 'Metacritic_user_nom', 'IMDB_norm', 'Fandango_Ratingvalue'] # type(norm_reviews[num_cols].values) # numpy.ndarray # ax.boxplot(arr) 箱线图 ax.boxplot(norm_reviews[num_cols].values) # ax.set_xticklabels(x_label_arr, rot) 设置x刻度的标签 ax.set_xticklabels(num_cols, rotation=90) # ax.set_ylim() 设置y轴的数据范围限制 ax.set_ylim(0, 5) plt.show()

16、 plt.plot(x, y) 折线图
plt.plot(x, y,c='blue/green/yellow',label='折现名') 折线图:线颜色、名字
import pandas as pd import matplotlib.pyplot as plt women_degrees = pd.read_csv('percent-bachelors-degrees-women-usa.csv') women_degrees[:3] # plt.plot(x, y) 折线图 plt.plot(women_degrees['Year'], women_degrees['Biology']) plt.show()

# 生物学学位按性别授予的百分比 x% # plt.plot(x, y,c='blue/green/yellow',label='折现名') 折线图 plt.plot(women_degrees['Year'], women_degrees['Biology'],c='blue', label='Women') plt.plot(women_degrees['Year'], 100-women_degrees['Biology'],c='red', label='Men') # plt.legend(loc='xxx') 在坐标轴上显示标签注释图例,这里指定注解在图右上侧 plt.legend(loc='upper right') # plt.title('图名') 坐标轴名 ps:中文名会报错 plt.title('Percentage of Biology Degrees Awarded By Gender') plt.show()

ax.tick_params(axis=‘both’, **kwargs) 设置图展示参数
axis : 可选{‘x’, ‘y’, ‘both’} ,选择对哪个轴操作,默认是’both’
reset : bool,如果为True,则在处理其他参数之前将所有参数设置为默认值。 它的默认值为False。
which : 可选{‘major’, ‘minor’, ‘both’} 选择对主or副坐标轴进行操作
direction/tickdir : 可选{‘in’, ‘out’, ‘inout’}刻度线的方向
size/length : float, 刻度线的长度
width : float, 刻度线的宽度
color : 刻度线的颜色,我一般用16进制字符串表示,eg:’#EE6363’
pad : float, 刻度线与刻度值之间的距离
labelsize : float/str, 刻度值字体大小
labelcolor : 刻度值颜色
colors : 同时设置刻度线和刻度值的颜色
zorder : float ,Tick and label zorder.
bottom, top, left, right : bool, 分别表示上下左右四边,是否显示刻度线,True为显示
labelbottom, labeltop, labelleft, labelright :bool, 分别表示上下左右四边,是否显示刻度值,True为显示
labelrotation : 刻度值逆时针旋转给定的度数,如20
gridOn: bool ,是否添加网格线; grid_alpha:float网格线透明度 ; grid_color: 网格线颜色; grid_linewidth:float网格线宽度; grid_linestyle: 网格线型
tick1On, tick2On : bool分别表表示是否显示axis轴的(左/下、右/上)or(主、副)刻度线
label1On,label2On : bool分别表表示是否显示axis轴的(左/下、右/上)or(主、副)刻度值
# 画一个图 fig, ax = plt.subplots() # 再画一个图 fig, ax = plt.subplots() # ax.plot(x, y,c='blue/green/yellow',label='折现名') 折线图 :如果不指定c='color'会自动赋值不同颜色 # ax.plot(women_degrees['Year'], women_degrees['Biology'],c='blue', label='Women') # ax.plot(women_degrees['Year'], 100-women_degrees['Biology'],c='red', label='Men') ax.plot(women_degrees['Year'], women_degrees['Biology'], label='Women') ax.plot(women_degrees['Year'], 100-women_degrees['Biology'], label='Men') # ax.tick_params(axis=‘both’, **kwargs) 设置图展示参数 ax.tick_params(bottom=False, top=False, left=False, right=False) # ax.set_title('name') 图标题名 ps:中文名会报错 ax.set_title('Percentage of Biology Degrees Awarded By Gender') # ax.legend(loc='xxx') 在坐标轴上显示标签注释图例,这里指定注解在图右上侧 ax.legend(loc='upper right') plt.show()
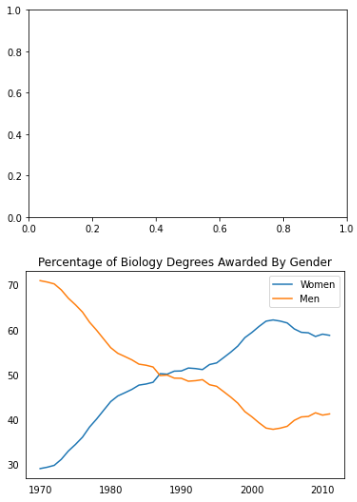
fig, (ax1, ax2) = plt.subplots(2,1) # fig.set_size_inches((w, h)) 设置子图尺寸(W宽,h高) fig.set_size_inches((12,8)) ax1.plot(women_degrees['Year'], women_degrees['Biology'], c='yellow', label='Women') ax1.plot(women_degrees['Year'], 100-women_degrees['Biology'],c='green', label='Man') ax2.plot(women_degrees['Year'], women_degrees['Biology'], c='red', label='Women') ax2.plot(women_degrees['Year'], 100-women_degrees['Biology'],c='green', label='Man') # 隐藏刻度线 ax.tick_params(bottom=False, top=False, left=False, right=False) # ax.spines: axes会获取到四个轴 # type(ax.spines) # collections.OrderedDict # type(ax.spines.items()) # odict_items # 将四个轴都隐藏 for key, spine in ax2.spines.items(): spine.set_visible(False) # 将折线注解展示在右上角 ax1.legend(loc='upper right') ax2.legend(loc='upper right') plt.show()

# 学科大类 major_cats = ['Biology', 'Computer Science', 'Engineering', 'Math and Statistics'] # 初始化画板 fig = plt.figure(figsize=(12,12)) for sp in range(0,4): ax = fig.add_subplot(2, 2, sp+1) # ax.plot(x,y,c='color',label='line label') ax.plot(women_degrees['Year'], women_degrees[major_cats[sp]], c='blue', label='Women') ax.plot(women_degrees['Year'], 100-women_degrees[major_cats[sp]], c='red', label='Man') # plt.legend(loc='upper/right/center/..') plt.legend(loc='upper right') plt.show() major_cats = ['Biology', 'Computer Science', 'Engineering', 'Math and Statistics'] fig = plt.figure(figsize=(18, 12)) for sp in range(0, 4): # fig.add_subplot(2, 2, sp+1) 定义n*m个子图,初始化第k个图 ax = fig.add_subplot(2, 2, sp+1) # ax.plot(x,y,c='color',label='line name') 折线图,并设置颜色,折线注解 ax.plot(women_degrees['Year'], women_degrees[major_cats[sp]], c='yellow', label='Women') ax.plot(women_degrees['Year'], 100-women_degrees[major_cats[sp]], c='green', label='Man') # 将ax的四个坐标轴隐藏 for key, spine in ax.spines.items(): spine.set_visible(False) # ax.set_xlim(start, end) 设置x轴范围 ax.set_xlim(1968, 2011) # ax.set_ylim(start,end) 设置y轴范围 ax.set_ylim(0, 100) # ax.set_title('title name') 设置图的标题 ax.set_title(major_cats[sp]) # ax.tick_params() 设置刻度线参数,这里隐藏四个轴上的所有刻度线 ax.tick_params(bottom=False, top=False, left=False, right=False) #plt.legend(loc='upper/right/left/..') 设置折线注解位置 plt.legend(loc='upper right') #plt.legend(loc='upper/right/left/..') 设置折线注解位置 #plt.legend(loc='upper right') plt.show()
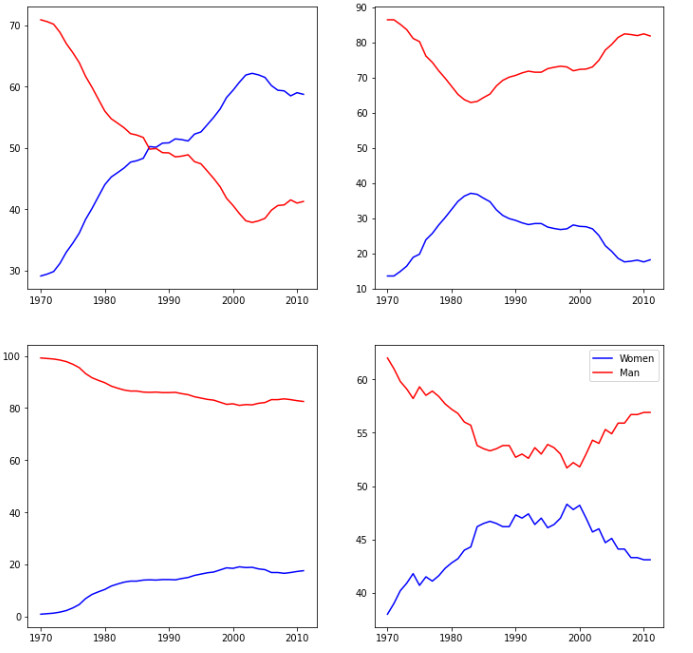

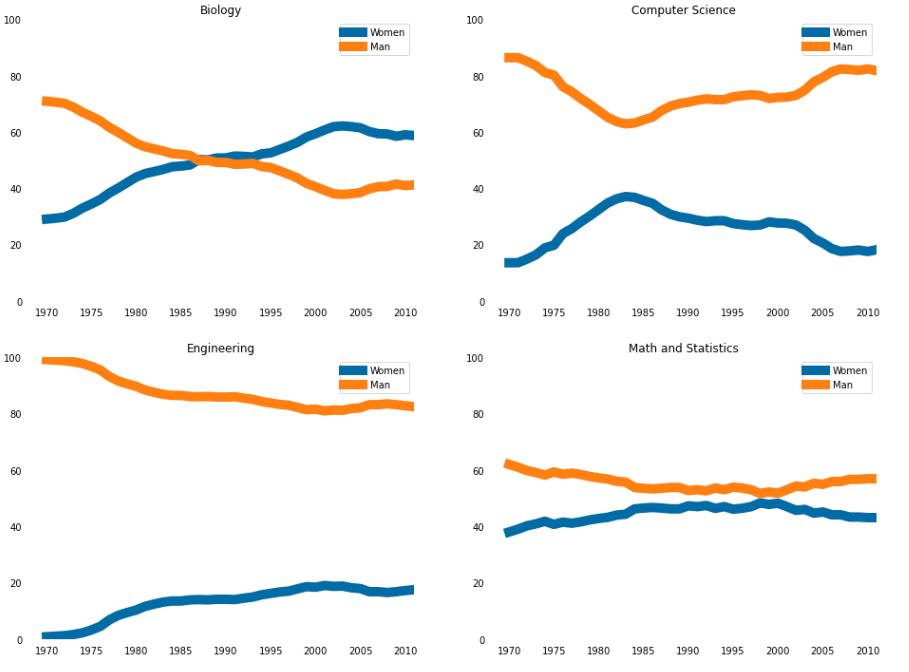
# 颜色 import pandas as pd import matplotlib.pyplot as plt # pandas.read_csv('file_path') 从csv文件读取数据到DataFrame women_degrees = pd.read_csv('percent-bachelors-degrees-women-usa.csv') # 学科大类 major_cats = ['Biology', 'Computer Science', 'Engineering', 'Math and Statistics'] # 自定义颜色 cb_dark_blue = (90/255, 107/255, 164/255) cb_orange = (255/255, 128/255, 114/255) # matplotlib.pyplot.figure(figsize=(x,y)) 初始化一个画板 fig = plt.figure(figsize=(18, 12)) # for循环画子图 for sp in range(0,4): # fig.add_subplot(2,2,n) 画2*2的第n个子图 ax = fig.add_subplot(2,2,sp+1) # ax.plot(x,y,c=color,label='label name') ax.plot(women_degrees['Year'], women_degrees[major_cats[sp]], c=cb_dark_blue, label='Women') ax.plot(women_degrees['Year'], 100-women_degrees[major_cats[sp]], c=cb_orange, label='Man') # for循环: spine.set_visible(False) 隐藏四个轴 for key, spine in ax.spines.items(): # print(key) # left right bottom top spine.set_visible(False) # ax.set_xlim(n,m) 设置x范围 ax.set_xlim(1968, 2011) # ax.set_ylim(n,m) 设置y范围 ax.set_ylim(0,100) # ax.set_title('title name') 设置标题名 ax.set_title(major_cats[sp]) # ax.tick_params() 设置刻度线 ax.tick_params(bottom=False, top=False, left=False, right=False) # plt.legend(loc='upper/right/left/center/..') 设置折线注解位置 plt.legend(loc='upper right') plt.show()
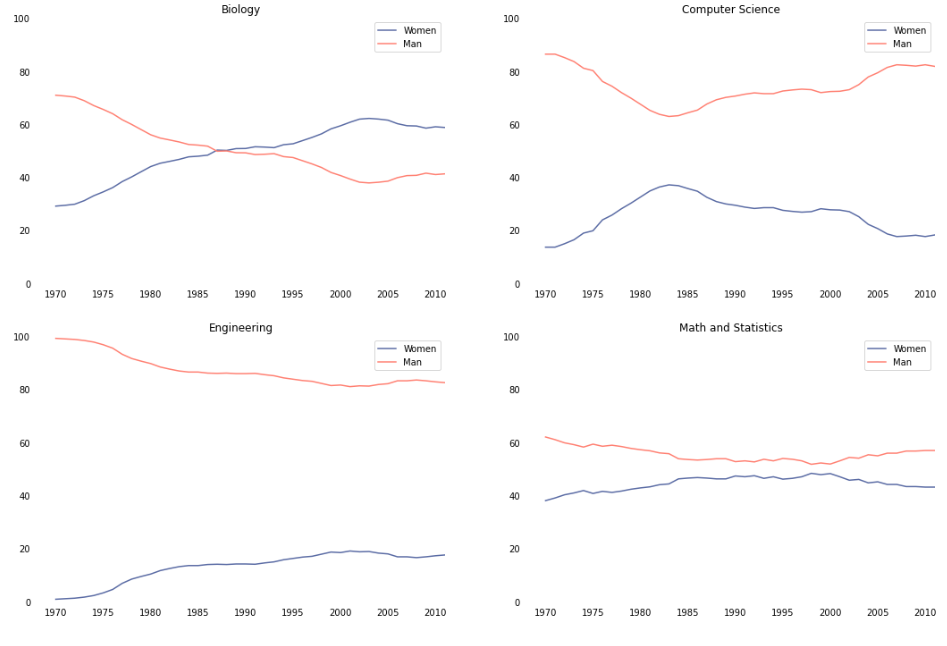
# 设置线的粗细 # 定义线的颜色 cb_dark_blue = (0/255, 107/255, 164/255) cb_orange = (255/255, 128/255, 16/255) # plt.figure(figsize=(n,m)) 初始化画板 fig = plt.figure(figsize=(16,12)) # for循环 for sp in range(0, 4): # fig.add_subplot(n, m, k) # 定义n*m个子图的第k个子图 ax = fig.add_subplot(2, 2, sp+1) # ax.plot(x,y,c=color,label='label name') # 绘制折线图,设置颜色,线的标签,linewidth=10线的粗细 ax.plot(women_degrees['Year'], women_degrees[major_cats[sp]], c=cb_dark_blue, label='Women', linewidth=10) ax.plot(women_degrees['Year'], 100-women_degrees[major_cats[sp]], c=cb_orange, label='Man', linewidth=10) # for循环:隐藏四个轴 for key, spine in ax.spines.items(): # spine.set_visible(False) 隐藏轴 spine.set_visible(False) # ax.set_xlim(n,m) # 设置x的范围 ax.set_xlim(1968, 2011) # ax.set_ylim(n,m) # 设置y的范围 ax.set_ylim(0,100) # ax.set_title(major_cats[sp]) # 设置子图的标题 ax.set_title(major_cats[sp]) # ax.tick_params() # 设置刻度线 ax.tick_params(bottom=False, top=False, left=False, right=False) # plt.legend(loc='upper right') # 设置线注解的位置 plt.legend(loc='upper right') plt.show()
stem_cats = ['Engineering', 'Computer Science', 'Psychology', 'Biology', 'Physical Sciences', 'Math and Statistics'] # 定义画板 fig = plt.figure(figsize=(12,8)) # for循环,绘制子图 for sp in range(0, 6): # fig.add_subplot(n,m,k) # 定义n*m个子图,初始化第k个子图 ax = fig.add_subplot(1, 6, sp+1) # ax.plot(x,y,c=color,label='xx',linewidth=3) # 绘制折线图,设置颜色,线粗细linewidth ax.plot(women_degrees['Year'], women_degrees[stem_cats[sp]],c=cb_dark_blue, label='Women', linewidth=3) ax.plot(women_degrees['Year'], 100-women_degrees[stem_cats[sp]], c=cb_orange, label='Man', linewidth=3) # for循环:隐藏所有轴 for key, spine in ax.spines.items(): spine.set_visible(False) # ax.set_xlim(n,m) # 设置x轴范围 ax.set_xlim(1968, 2011) ax.set_ylim(0,100) # ax.set_title('xx') # 设置标题 ax.set_title(stem_cats[sp]) ax.tick_params(bottom=False, top=False, left=False, right=False) plt.legend(loc='center') plt.show()
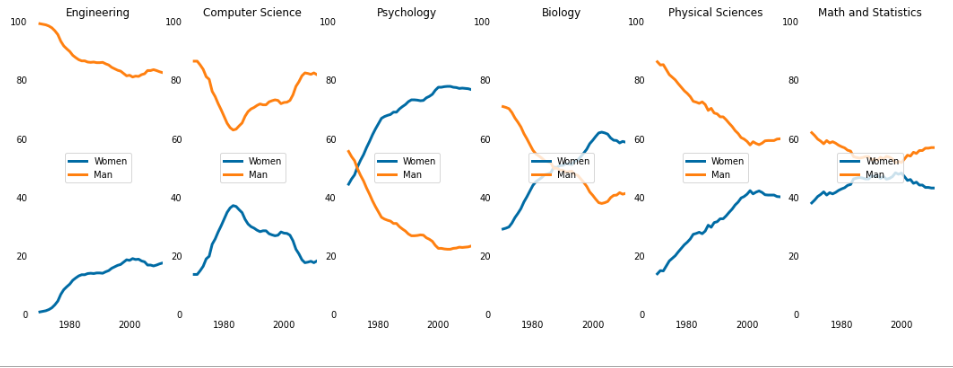
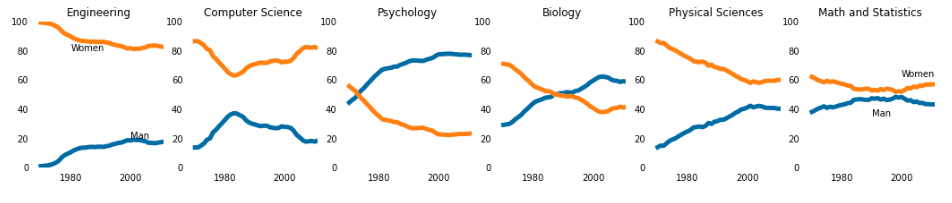
# fig=plt.figure(figsize=(n,m)) # 定义一个画板 fig = plt.figure(figsize=(18,3)) # for绘制子图 for sp in range(0,6): ax = fig.add_subplot(1, 6, sp+1) # 绘制第sp+1个图 ax.plot(women_degrees['Year'], women_degrees[stem_cats[sp]], c=cb_dark_blue, label='Women', linewidth=5) ax.plot(women_degrees['Year'], 100-women_degrees[stem_cats[sp]], c=cb_orange, label='Man', linewidth=5) for key, spine in ax.spines.items(): spine.set_visible(False) ax.set_xlim(1968, 2011) ax.set_ylim(0, 100) ax.set_title(stem_cats[sp]) ax.tick_params(bottom=False, top=False, left=False, right=False) if sp == 0: # ax.text(x,y,str) # 设置str显示位置(x,y) ax.text(1980,80,'Women') ax.text(2000,20,"Man") elif sp == 5: ax.text(2000,62,'Women') ax.text(1990,35,'Man') plt.show()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号