
从csv文件中读取数据生成DataFrame
import pandas as pd #从csv文件中读取数据,生成DataFrame fandango = pd.read_csv('G:\\python\\库应用(4个)\\3-可视化库matpltlib\\fandango_scores.csv') #读取'FILM'列的[0~5)的值 fandango['FILM'][0:5] #访问'RottenTomatoes'列的[0~5)的值 fandango['RottenTomatoes'][0:5]
查看类型
fandango[['FILM','RottenTomatoes','RottenTomatoes_User']] type(fandango[['FILM','RottenTomatoes','RottenTomatoes_User']]) # pandas.core.frame.DataFrame type(fandango['RottenTomatoes']) # pandas.core.series.Series #fandango['RottenTomatoes'].index # RangeIndex(start=0, stop=146, step=1)
1、Series的生成:从DataFrame中获取Series
from pandas import Series # 从DataFrame中获取series:“FILM”列,得到Series type(fandango['FILM']) # pandas.core.series.Series film_series = fandango['FILM']
2、构建Series,值为rt_scores,索引为film_names
# series.values属性,获取所有值列表 film_names = film_series.values type(film_names) # type(film_names) 返回numpy.ndarray rt_series = fandango['RottenTomatoes'] rt_scores = rt_series.values type(rt_scores) # type(rt_scores) 返回numpy.ndarray # 构建Series,值为rt_scores,索引为film_names custom_series = Series(rt_scores, index=film_names)
custom_series.index # Index([...],dtype='object', length=146)
3、Series中元素的访问
# 通过数字进行访问 custom_series[[3,5,8]] # 通过索引名进行访问 custom_series[['Minions (2015)', 'Leviathan (2014)']]
4、series.index属性
# series.index属性,获取所有索引 type(custom_series.index) # pandas.core.indexes.base.Index type(custom_series.index.tolist()) # list original_index = custom_series.index.tolist()
5、sorted(iterable)是python内置函数,对list进行排序
# sorted(iterable)是python内置函数,对list进行排序 sorted_index = sorted(original_index)
6、series.reindex(index_arr_like)重置series的索引
#help(custom_series.reindex) # series.reindex(index_arr_like)重置series的索引 sorted_by_index = custom_series.reindex(sorted_index)
7、series按索引排序Series.sort_index()、按值排序Series.sort_values()
# series按索引排序Series.sort_index()、按值排序Series.sort_values() custom_series.sort_index() custom_series.sort_values()
8、numpy的add/sin/max运算
#numpy的add/sin/max运算 np.add(custom_series, custom_series) # 等同于 custom_series + custom_series np.sin(custom_series) np.max(custom_series)
9、Series条件判断
custom_series > 98 greater_than_98_series = custom_series[custom_series > 98] condition_one = custom_series > 60 condition_two = custom_series < 66 custom_series[condition_one & condition_two]
10、两个Series的运算:每部电影,影评员与用户的平均评分
# 每部电影,影评员与用户的平均评分 rt_critics = Series(fandango['RottenTomatoes'].values, index=fandango['FILM']) rt_users = Series(fandango['RottenTomatoes_User'].values, index=fandango['FILM'].values) (rt_critics + rt_users)/2
type(fandango['RottenTomatoes']) # pandas.core.series.Series #fandango['RottenTomatoes'].index # RangeIndex(start=0, stop=146, step=1) #rt_users.index # Index([...],dtype='object', length=146)
11、Series.value_counts(): 统计每个值有在该列中有多少重复值。
import pandas as pd import matplotlib.pyplot as plt reviews = pd.read_csv('fandango_scores.csv') cols = ['FILM', 'RT_user_norm', 'Metacritic_user_nom', 'IMDB_norm', 'Fandango_Ratingvalue'] norm_reviews = reviews[cols] norm_reviews[:5]
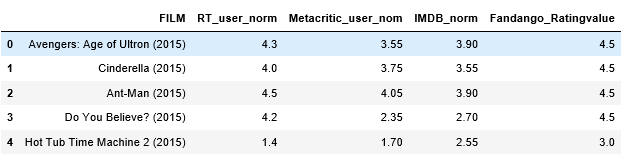
# Series.value_counts(): 每个值有在该列中有多少重复值。 fandango_distribution = norm_reviews['Fandango_Ratingvalue'].value_counts() # Series.sort_index() 按索引排序,默认升序 fandango_distribution = fandango_distribution.sort_index() imdb_distribution = norm_reviews['IMDB_norm'].value_counts() imdb_distribution = imdb_distribution.sort_index() print(fandango_distribution) print(imdb_distribution)
2.7 2 2.8 2 2.9 5 3.0 4 3.1 3 3.2 5 3.3 4 3.4 9 3.5 9 3.6 8 3.7 9 3.8 5 3.9 12 4.0 7 4.1 16 4.2 12 4.3 11 4.4 7 4.5 9 4.6 4 4.8 3 Name: Fandango_Ratingvalue, dtype: int64 2.00 1 2.10 1 2.15 1 2.20 1 2.30 2 2.45 2 2.50 1 2.55 1 2.60 2 2.70 4 2.75 5 2.80 2 2.85 1 2.90 1 2.95 3 3.00 2 3.05 4 3.10 1 3.15 9 3.20 6 3.25 4 3.30 9 3.35 7 3.40 1 3.45 7 3.50 4 3.55 7 3.60 10 3.65 5 3.70 8 3.75 6 3.80 3 3.85 4 3.90 9 3.95 2 4.00 1 4.05 1 4.10 4 4.15 1 4.20 2 4.30 1 Name: IMDB_norm, dtype: int64
13、

 浙公网安备 33010602011771号
浙公网安备 33010602011771号