
正则表达式函数
所有正则表达式函数都使用Java模式语法,但有一些值得注意的例外:
使用多行模式(通过(?m)标志启用)时,仅\n被识别为行终止符。此外,该(?d)标志不受支持,并且不得使用。
不区分大小写的匹配(通过(?i)标志启用)始终以Unicode感知的方式执行。但是,不支持上下文相关和本地敏感匹配。此外,该 (?u)标志不受支持,因此不能使用。
不支持代理对。例如,\uD800\uDC00不被视为U+10000,必须将其指定为\x{10000}。
\b没有基本字符的非空格标记的边界()处理不正确。
\Q并且\E在字符类(例如[A-Z123])中不受支持,而是被视为文字。
支持Unicode字符类(\p{prop}),但有以下差异:
名称中的所有下划线都必须删除。例如,使用 OldItalic代替Old_Italic。
脚本必须直接指定,如果没有 Is,script=或sc=前缀。例:\p{Hiragana}
必须使用In前缀指定块。将block=与blk=前缀不被支持。例:\p{Mongolian}
分类必须直接指定,如果没有Is, general_category=或gc=前缀。例:\p{L}
二进制属性必须直接指定,不带Is。例:\p{NoncharacterCodePoint}
regexp_extract_all(字符串,模式)->数组(varchar )
由正则表达式匹配的返回子(一个或多个)pattern 中string:
SELECT regexp_extract_all('1a 2b 14m', '\d+'); -- [1, 2, 14]
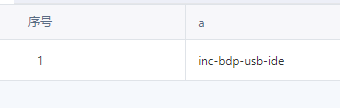
select regexp_extract( '$timezone_offset:-480,$screen_height:720,$screen_width:1280,$viewport_height:569,$viewport_width:1280,$lib:js,$lib_version:1.26.11,$latest_traffic_source_type:直接流量,$latest_search_keyword:未取到值_直接打开,$latest_referrer:,userId:110,system_code:INC-xxx-USB,platform_env:PROD,product_code:inc-bdp-usb-ide,platform_name:PC,platform_type:Web,event_id:BDP_AI_quick_message,pageName:智能助手,applicationId:-9999,requirementId:-9999,productId:ide,promptKey:ide_ai_assistant,tenantId:110,combineRequirementInfo:0,$is_first_day:false,$url:http://data.xxxx,$title:临时查询,$ip:xx.xx.1xx.xx,$url_host:fff.com,$os:Windows,$os_version:10,$browser:Chrome,$browser_version:1xx.0.0.0,$track_signup_original_id:1xxeb0-0cf140436c82a2-efdsaf-921600-efafds234dsf,$is_login_id:true,$city:深圳,$province:广东,$country:中国', '.*product_code\:([a-zA-Z-]+)\,platform_name.*',1 ) as a
regexp_extract_all(字符串,模式,组)->数组(varchar )
发现正则表达式的所有出现pattern在string 与返回所述捕获组号码 group:
SELECT regexp_extract_all('1a 2b 14m', '(\d+)([a-z]+)', 2); -- ['a', 'b', 'm']
regexp_extract(字符串,模式) →varchar
返回由正则表达式匹配的第一个字符串pattern 中string:
SELECT regexp_extract('1a 2b 14m', '\d+'); -- 1
regexp_extract(字符串,模式,组) →varchar
查找中出现的第一个正则表达式pattern, string并返回捕获组号 group:
SELECT regexp_extract('1a 2b 14m', '(\d+)([a-z]+)', 2); -- 'a'
regexp_like(字符串,模式) →布尔值
计算正则表达式pattern并确定它是否包含在中string。
此功能类似于LIKE运算符,除了模式仅需要包含在其中string,而不需要匹配所有string。换句话说,它执行 包含操作而不是匹配操作。您可以通过使用^和锚定模式来匹配整个字符串$:
SELECT regexp_like('1a 2b 14m', '\d+b'); -- true
regexp_replace(字符串,模式) →varchar
pattern从中删除与正则表达式匹配的子字符串的每个实例 string:
SELECT regexp_replace('1a 2b 14m', '\d+[ab] '); -- '14m'
regexp_replace(字符串,模式,替换) →varchar
通过替换正则表达式匹配的子串的每个实例 pattern中string使用replacement。可以在使用编号组或 命名组时引用捕获组。通过用反斜杠()进行转义,可以将美元符号()包括在替换中:replacement$g${name}$\$
SELECT regexp_replace('1a 2b 14m', '(\d+)([ab]) ', '3c$2 '); -- '3ca 3cb 14m'
regexp_replace(字符串,模式,函数) →varchar
pattern在stringusing中替换与正则表达式匹配的子字符串的每个实例 function。所述lambda表达式 function被调用为每个匹配与捕获基团作为数组传递。捕获组号从1开始;没有用于整个匹配的分组(如果需要,请用括号将整个表达式括起来)。
SELECT regexp_replace('new york', '(\w)(\w*)', x -> upper(x[1]) || lower(x[2])); --'New York'
regexp_split(字符串,模式)->数组(varchar )
string使用正则表达式拆分pattern并返回一个数组。尾随的空字符串被保留:
SELECT regexp_split('1a 2b 14m', '\s*[a-z]+\s*'); -- [1, 2, 14, ]
参考:官网手册
https://prestodb.io/docs/current/
https://prestodb.io/docs/current/functions/regexp.html
相当好用,感觉自己无所不能了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号