
读取Oracle的数据存入HDFS中
1)编写配置文件
[oracle@hadoop102 datax]$ vim job/oracle2hdfs.json { "job": { "content": [ { "reader": { "name": "oraclereader", "parameter": { "column": ["*"], "connection": [ { "jdbcUrl": ["jdbc:oracle:thin:@hadoop102:1521:orcl"], "table": ["student"] } ], "password": "000000", "username": "jason" } }, "writer": { "name": "hdfswriter", "parameter": { "column": [ { "name": "id", "type": "int" }, { "name": "name", "type": "string" } ], "defaultFS": "hdfs://hadoop102:9000", "fieldDelimiter": "\t", "fileName": "oracle.txt", "fileType": "text", "path": "/", "writeMode": "append" } } } ], "setting": { "speed": { "channel": "1" } } } }
2)执行
[oracle@hadoop102 datax]$ bin/datax.py job/oracle2hdfs.json
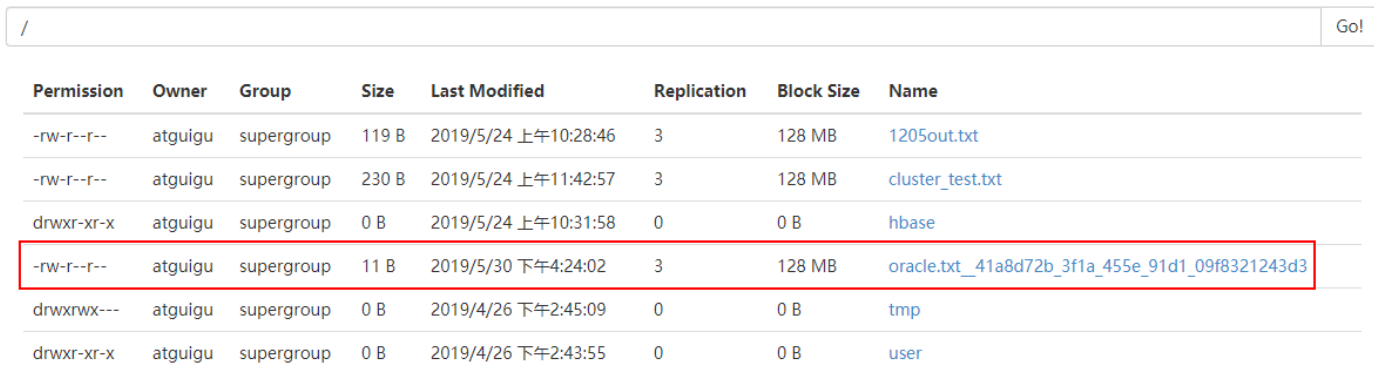
3)查看HDFS结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号