
一、单数据源多出口案例1
1)案例需求:
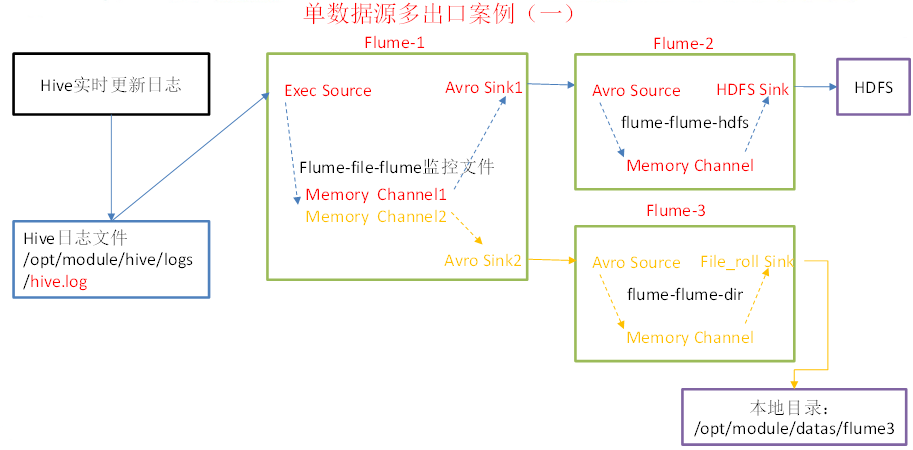
使用flume-1监控文件变动,flume-1将变动内容传递给flume-2,flume-2负责存储到HDFS。
同时flume-1将变动内容传递给flume-3,flume-3负责输出到local filesystem。
2)需求分析:
3)实现步骤:
0.准备工作
在/opt/module/flume/job目录下创建group1文件夹
[jason@hadoop102 job]$ cd group1/
在/opt/module/datas/目录下创建flume3文件夹
[jason@hadoop102 datas]$ mkdir flume3
1.创建flume-file-flume.conf
配置实时接收日志文件的1个source和两个channel、两个sink,分别输送给flume-flume-hdfs和flume-flume-dir这两个agent。
创建配置文件
[jason@hadoop102 group1]$ vim flume-file-flume.conf
添加如下内容
# Name the components on this agent a1.sources = r1 a1.sinks = k1 k2 a1.channels = c1 c2 # 将数据流复制给多个channel a1.sources.r1.selector.type = replicating # Describe/configure the source a1.sources.r1.type = exec a1.sources.r1.command = tail -F /opt/module/hive/logs/hive.log a1.sources.r1.shell = /bin/bash -c # Describe the sink a1.sinks.k1.type = avro a1.sinks.k1.hostname = hadoop102 a1.sinks.k1.port = 4141 a1.sinks.k2.type = avro a1.sinks.k2.hostname = hadoop102 a1.sinks.k2.port = 4142 # Describe the channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 a1.channels.c2.type = memory a1.channels.c2.capacity = 1000 a1.channels.c2.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 c2 a1.sinks.k1.channel = c1 a1.sinks.k2.channel = c2
注:Avro是由Hadoop创始人Doug Cutting创建的一种语言无关的数据序列化和RPC框架。
注:RPC(Remote Procedure Call)远程过程调用,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。
2.创建flume-flume-hdfs.conf
接收上级flume数据。flume-flume-hdfs输入为avro source,输出是到hdfs的sink。
创建配置文件
[jason@hadoop102 group1]$ vim flume-flume-hdfs.conf
添加如下内容
# Name the components on this agent a2.sources = r1 a2.sinks = k1 a2.channels = c1 # Describe/configure the source a2.sources.r1.type = avro a2.sources.r1.bind = hadoop102 a2.sources.r1.port = 4141 # Describe the sink a2.sinks.k1.type = hdfs a2.sinks.k1.hdfs.path = hdfs://hadoop102:9000/flume2/%Y%m%d/%H #上传文件的前缀 a2.sinks.k1.hdfs.filePrefix = flume2- #是否按照时间滚动文件夹 a2.sinks.k1.hdfs.round = true #多少时间单位创建一个新的文件夹 a2.sinks.k1.hdfs.roundValue = 1 #重新定义时间单位 a2.sinks.k1.hdfs.roundUnit = hour #是否使用本地时间戳 a2.sinks.k1.hdfs.useLocalTimeStamp = true #积攒多少个Event才flush到HDFS一次 a2.sinks.k1.hdfs.batchSize = 100 #设置文件类型,可支持压缩 a2.sinks.k1.hdfs.fileType = DataStream #多久生成一个新的文件 a2.sinks.k1.hdfs.rollInterval = 600 #设置每个文件的滚动大小大概是128M a2.sinks.k1.hdfs.rollSize = 134217700 #文件的滚动与Event数量无关 a2.sinks.k1.hdfs.rollCount = 0 #最小冗余数 a2.sinks.k1.hdfs.minBlockReplicas = 1 # Describe the channel a2.channels.c1.type = memory a2.channels.c1.capacity = 1000 a2.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a2.sources.r1.channels = c1 a2.sinks.k1.channel = c1
3.创建flume-flume-dir.conf
接收上级flume数据。flume-flume-dir输入是avro source,输出是到本地目录的sink。
创建配置文件
[jason@hadoop102 group1]$ vim flume-flume-dir.conf
添加如下内容
# Name the components on this agent a3.sources = r1 a3.sinks = k1 a3.channels = c2 # Describe/configure the source a3.sources.r1.type = avro a3.sources.r1.bind = hadoop102 a3.sources.r1.port = 4142 # Describe the sink a3.sinks.k1.type = file_roll a3.sinks.k1.sink.directory = /opt/module/datas/flume3 # Describe the channel a3.channels.c2.type = memory a3.channels.c2.capacity = 1000 a3.channels.c2.transactionCapacity = 100 # Bind the source and sink to the channel a3.sources.r1.channels = c2 a3.sinks.k1.channel = c2
提示:输出的本地目录必须是已经存在的目录,如果该目录不存在,并不会创建新的目录。
4.执行配置文件
分别开启对应配置文件:flume-flume-dir,flume-flume-hdfs,flume-file-flume。
[jason@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a3 --conf-file job/group1/flume-flume-dir.conf [jason@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a2 --conf-file job/group1/flume-flume-hdfs.conf [jason@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a1 --conf-file job/group1/flume-file-flume.conf
5.启动hadoop和hive
[jason@hadoop102 hadoop-2.7.2]$ sbin/start-dfs.sh [jason@hadoop103 hadoop-2.7.2]$ sbin/start-yarn.sh [jason@hadoop102 hive]$ bin/hive hive (default)>
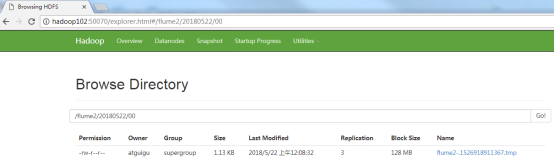
6.检查HDFS上数据
7检查/opt/module/datas/flume3目录中数据
[jason@hadoop102 flume3]$ ll 总用量 8 -rw-rw-r--. 1 jason jason 5942 5月 22 00:09 1526918887550-3
二、单数据源多出口案例2
1)案例需求:
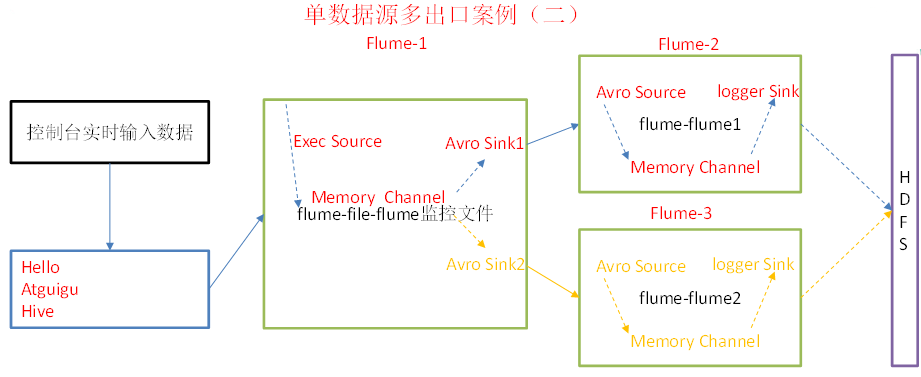
使用flume-1监控文件变动,flume-1将变动内容传递给flume-2,flume-2负责存储到HDFS。同时flume-1将变动内容传递给flume-3,flume-3也负责存储到HDFS
2)需求分析:
3)实现步骤:
0.准备工作
在/opt/module/flume/job目录下创建group2文件夹
[jason@hadoop102 job]$ cd group1/
1.创建flume-netcat-flume.conf
配置1个接收日志文件的source和1个channel、两个sink,分别输送给flume-flume1和flume-flume2。
创建配置文件
[jason@hadoop102 group1]$ vim flume-netcat-flume.conf
添加如下内容
# Name the components on this agent a1.sources = r1 a1.channels = c1 a1.sinkgroups = g1 a1.sinks = k1 k2 # Describe/configure the source a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444 a1.sinkgroups.g1.processor.type = load_balance a1.sinkgroups.g1.processor.backoff = true a1.sinkgroups.g1.processor.selector = round_robin a1.sinkgroups.g1.processor.selector.maxTimeOut=10000 # Describe the sink a1.sinks.k1.type = avro a1.sinks.k1.hostname = hadoop102 a1.sinks.k1.port = 4141 a1.sinks.k2.type = avro a1.sinks.k2.hostname = hadoop102 a1.sinks.k2.port = 4142 # Describe the channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinkgroups.g1.sinks = k1 k2 a1.sinks.k1.channel = c1 a1.sinks.k2.channel = c1
注:Avro是由Hadoop创始人Doug Cutting创建的一种语言无关的数据序列化和RPC框架。
注:RPC(Remote Procedure Call)—远程过程调用,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。
2.创建flume-flume1.conf
接收上级flume数据。输入是的avro source,输出是到本地控制台。
创建配置文件
[jason@hadoop102 group1]$ vim flume-flume1.conf
添加如下内容
# Name the components on this agent a2.sources = r1 a2.sinks = k1 a2.channels = c1 # Describe/configure the source a2.sources.r1.type = avro a2.sources.r1.bind = hadoop102 a2.sources.r1.port = 4141 # Describe the sink a2.sinks.k1.type = logger # Describe the channel a2.channels.c1.type = memory a2.channels.c1.capacity = 1000 a2.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a2.sources.r1.channels = c1 a2.sinks.k1.channel = c1
3.创建flume-flume2.conf
配置上级flume输出的source,输出是到本地控制台。
创建配置文件
[jason@hadoop102 group1]$ vim flume-flume2.conf
添加如下内容
# Name the components on this agent a3.sources = r1 a3.sinks = k1 a3.channels = c2 # Describe/configure the source a3.sources.r1.type = avro a3.sources.r1.bind = hadoop102 a3.sources.r1.port = 4142 # Describe the sink a3.sinks.k1.type = logger # Describe the channel a3.channels.c2.type = memory a3.channels.c2.capacity = 1000 a3.channels.c2.transactionCapacity = 100 # Bind the source and sink to the channel a3.sources.r1.channels = c2 a3.sinks.k1.channel = c2
4.执行配置文件
分别开启对应配置文件:flume-flume2,flume-flume1,flume-netcat-flume。
[jason@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a3 --conf-file job/group1/flume-flume2.conf -Dflume.root.logger=INFO,console
[jason@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a2 --conf-file job/group1/flume-flume1.conf -Dflume.root.logger=INFO,console
[jason@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a1 --conf-file job/group1/flume-netcat-flume.conf
5. 使用telnet工具向本机的44444端口发送内容
$ telnet localhost 44444
6. 查看flume2及flume3的控制台打印日志

 浙公网安备 33010602011771号
浙公网安备 33010602011771号