
一.faster rcnn整体框架:
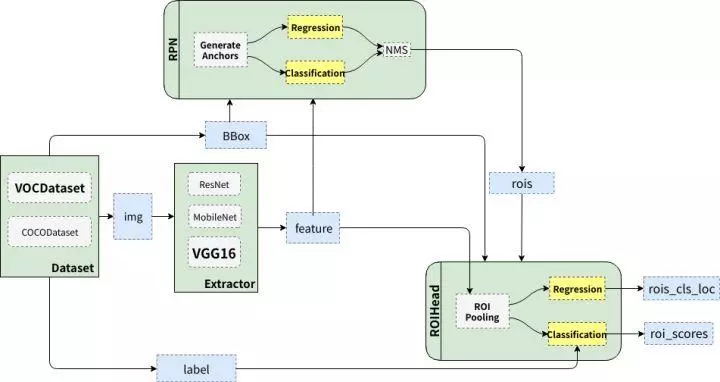
FRCNN主要分为四部分:
- Dataset:数据,提供符合要求的数据格式。(VOC/COCO)
- Extractor:利用CNN提取图片特征features(原始论文用的是ZF/VGG16,后用ResNet101)
- RPN(Region Proposal Network):负责提供候选区域rois
- RoIHead:负责对rois的分类和微调。对RPN找出的rois进行挑选和位置回归
二.各部分实现思路:
2.1数据Dataset。
图片进行缩放。长<=1000,宽<=600(至少有一个等于),并对相应的bboxes也进行同等尺度的缩放。
对Caffe的VGG16预训练模型,需要图片位于0-255,RGB格式并减去一个均值使图片像素均值为0.
返回值:
- image:3*H*W(RGB三通道)
- bboxes:4k(k个bboxes的坐标)
- labels:k(k个bboxes的label,voc为[0-19])
- scales:缩放倍数(H',w'->H,W,scale=(H'/H) )
2.2Extractor
使用预训练好的模型提取图片的特征。论文中使用Caffe的VGG16。此处在上面进行一点修改:为了节省显存,前四层卷积层学习率设为0。
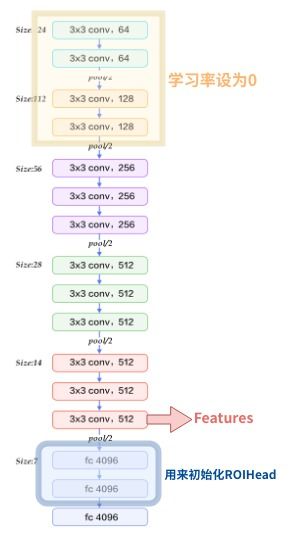
Conv5-3的输出作为features,conv5-3相比于输入,下采样16倍(因为pooling,此处Conv由于补边,不改变尺寸)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号