
R-CNN:

-
输入图片
-
使用Selective Search算法生成多个候选框,再放入CNN一个个得到特征值
-
经过a.区域分割 b.合并子集最终得到大大减少的候选框
-
后用分类器如(SVM)进行分类。在分类(单个候选框)时,用IoU和NMS结合方法,解决多类别识别。
-
最后利用线性回归模型判定Bounding box的准确性进行微调。
Fast R-CNN:

在R-CNN上改进,提出共享卷积、ROI pooling,提高速度
(先经过CNN再进行anchor)
Faster R-CNN
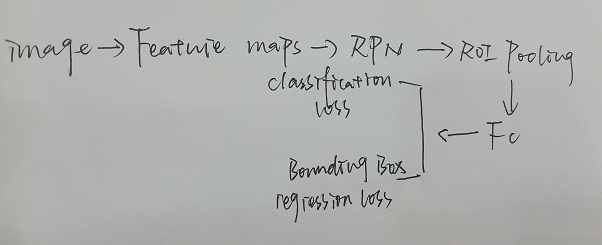
使用RPN(Region Proposal Network)网络代替Fast R-CNN中的选择性搜索
注:Feature maps是经过FPN得到不同维度的Feature maps
其他模型
Mask R-CNN
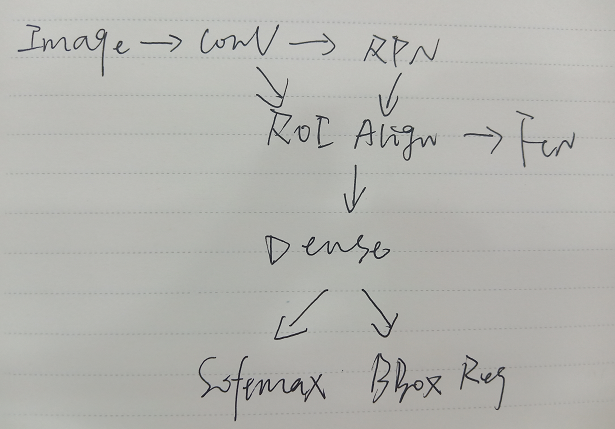
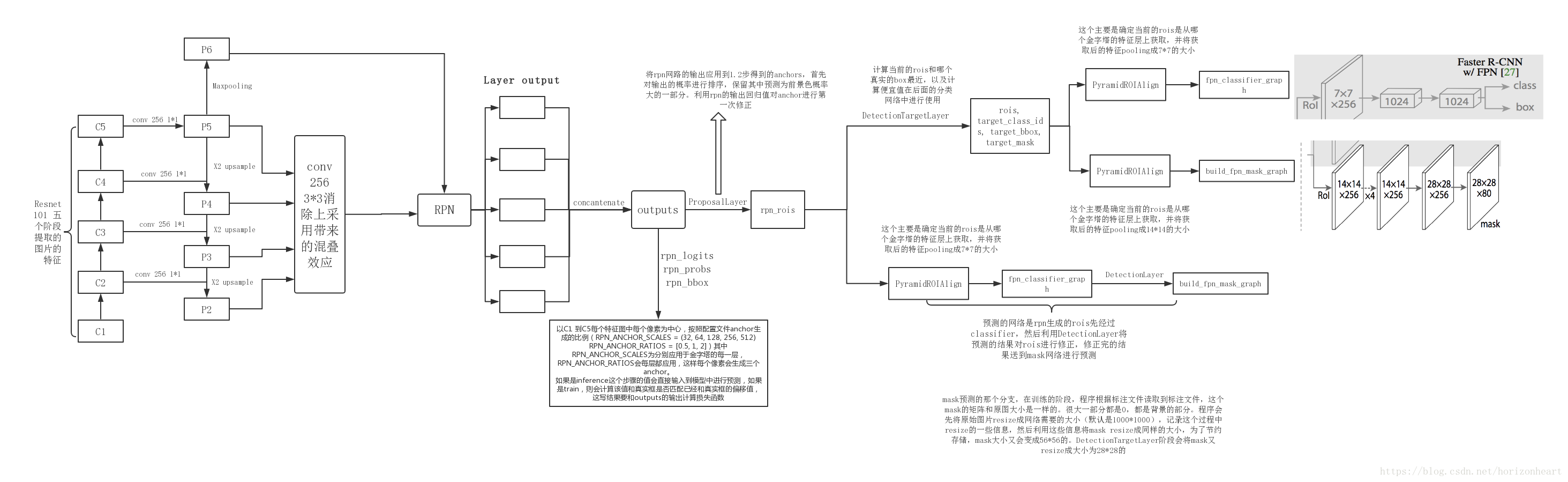
一个不错讲maskrcnn的网址:https://zhuanlan.zhihu.com/p/37998710
ROI Align
ROI Pooling总是取整,精确度有损失,ROI Align即取消量化操作,使用双线性内插的方法获得坐标为浮点数的像素点上的图像数值,从而将整个特征剧集过程转化为一个连续的操作
FCN
全连接网络
数据集->VOG(即label不是单纯的文本而是一个png)
通过加入转置卷积,可以把输入转回原来大小,使高级特征和低级特征结合起来,更加准确
-
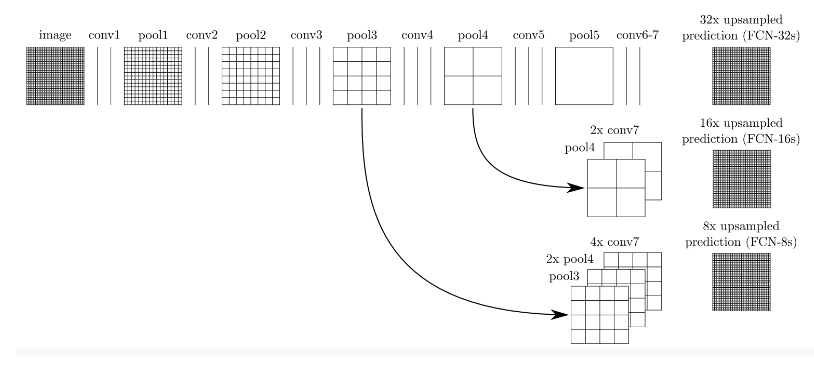
如下图所示:对原图进行卷积conv1、pool1后图像缩小为1/2;对图像进行第二次卷积conv2、pool2后图像缩小为1/4;对图像进行第三次卷积conv3、pool3后图像缩小为1/8,此时保留pool3的featuremap;对图像进行第四次卷积conv4、pool4后图像缩小为1/16,此时保留pool4的featuremap;对图像进行第五次卷积conv5、pool5后图像缩小为1/32,然后把原来CNN操作过程中的全连接编程卷积操作的conv6、conv7,图像的featuremap的大小依然为原图的1/32,此时图像不再叫featuremap而是叫heatmap。
-
其实直接使用前两种结构就已经可以得到结果了,这个上采样是通过反卷积(deconvolution)实现的,对第五层的输出(32倍放大)反卷积到原图大小。但是得到的结果还上不不够精确,一些细节无法恢复。于是将第四层的输出和第三层的输出也依次反卷积,分别需要16倍和8倍上采样,结果过也更精细一些了。这种做法的好处是兼顾了local和global信息。
SSD
YOLO

YOLO V2
不使用均匀的锚框,而是用训练数据的真实数据做K-means聚类,后使用聚类中心做锚框

 浙公网安备 33010602011771号
浙公网安备 33010602011771号