
栈?
后进先出的线性表。只能在表尾进行插入或删除
队列?
先进先出的线性表。只能一端插入一端删除
二叉树?
n个有限元素的集合,该集合或为空,或由一个称为根的元素及两个不相交的、被称为左子树右子树的二叉树组成
满二叉树?
一个每一层结点都达到最大值的二叉树
完全二叉树?
设二叉树的深度为h,除第h层,其他各层(1至h-1)的结点数都达到最大值,即1至h-1层是一个满二叉树,第h层所有结点都连续集中在最左边。
解决Hash冲突?
hash冲突是指,由于哈希算法被计算的数据是无限的,而计算后的结果范围有限,因此总会存在不同的数据经过计算后得到的值相同,这就是哈希冲突
解决方法有两种:
1.开放寻址法:从发生冲突的单元起,按照一定次序,在哈希表中找到个空闲单元,把发生冲突的元素放入此单元。
此方法需要表长度大于需存放的元素
2.链地址法:将哈希值相同的元素、构成一个称为“同义词链”的单链表,并将此链表的头指针存放在第i个单元中,因此查找插入删除主要在同义词链中进行。
此方法适用于经常插入删除的情况
3.再哈希法:同时构造多个不同的哈希函数。法1冲突时使用法2,直至冲突不再产生。这种方法不易产生聚集,但增加了计算时间。
4.建立公共溢出区:将哈希表分为基本表和溢出表两部分,凡是和基本表发生冲突的元素,一律填入溢出表。
平衡二叉树(AVL树)
引入平衡因子(左子支高度和右子支高度之差的绝对值),通过旋转使其尽量保持平衡
特点:
1.可以是空树。
2.假如不是空树,任何一个结点的左子树与右子树都是平衡二叉树,并且高度之差的绝对值不超过 1。
红黑树
说的都是啥?
稳定排序和非稳定排序
稳定排序:排序前后两个相等的数相对位置不变。算法如:插入排序、冒泡排序、归并排序
非稳定排序:排序前后两个相等的数相对位置改变。算法如:希尔排序、直接选择排序、堆排序、快速排序
插入排序?
每一趟将一个待排序记录按其关键字大小插入到已排好序的一组记录的适当位置上,知道全部插入完
算法稳定,时间复杂度O(N²),空间复杂度O(1)
希尔排序?
又称为缩小增量排序
把记录按下标的一定增量分组,对每组进行插入排序,每次排序后减小增量,当增量减少至1时排序完毕
算法不稳定,时间复杂度O(NlogN),空间复杂度O(1)
直接选择排序?
每次在未排序序列中找到最小元素,与未排序的第一个元素交换位置,再在剩余未排序序列重复操作直至排序完毕
算法不稳定,时间复杂度O(N²),空间复杂度O(1)
堆排序?
堆是近似完全二叉树的结构,且子结点的键值或索引总是小于(或者大于)它的父节点。可分为大顶堆(最大值堆)和小顶堆(最小值堆)
基本思想是利用大顶堆(小顶堆)堆顶记录的是最大关键字(或最小关键字)的特征,使每次从无序中选择最大(最小)记录变得简单:
① 将待排序的序列构造成一个最大堆,此时序列的最大值为根节点
② 依次将根节点与待排序序列的最后一个元素交换
③ 再维护从根节点到该元素的前一个节点为最大堆,如此往复,最终得到一个递增序列
算法不稳定,时间复杂度O(NlogN),空间复杂度O(1)
冒泡排序?
比较相邻元素,若第一个比第二个大就交换,对每一对相邻元素做同样工作
算法稳定,时间复杂度O(N²),空间复杂度O(1)
快速排序?
随机选择一个基准元素,通过一趟排序将数据分割成两部分,一部分小于等于基准元素,一部分大于等于基准元素。再对两部分继续同样步骤
算法稳定,时间复杂度O(NlogN),空间复杂度O(logN)
归并排序?
将待排序列分成两部分,再对两部分进行递归排序,最后合并
算法稳定,时间复杂度O(NlogN),空间复杂度O(N)
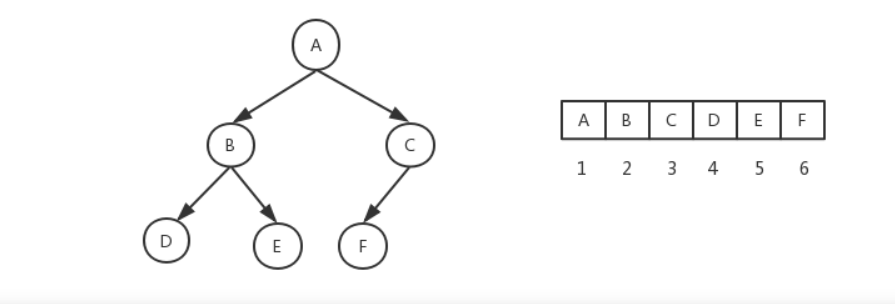
图?
图是顶点集合和顶点之间的边集合组成的一种数据结构,根据边是否有方向性可分为有向图和无向图。
邻接矩阵?
通过链表表示图链接关系的一种方法
图的深度优先搜索DFS和广度优先搜索BFS
深度优先搜索DFS:对每一个可能的分支路径深入到不能再深入为止,且每个节点只能访问一次
广度优先搜索BFS:类似于树的层次遍历,是一种按照由近及远的方式访问图的顶点。在进行BFS时需要使用队列存储顶点信息
最小生成树和其对应算法
对于有n个结点的原图,生成原图的最小连通子图,其包含原图中所有n个节点,并且有保持图连通的最少的边
克鲁斯卡算法:是贪心算法。将图中节点按权重大小排序,每次从边集中取出权值最小且两个顶点不在同一个集合的边加入生成树中
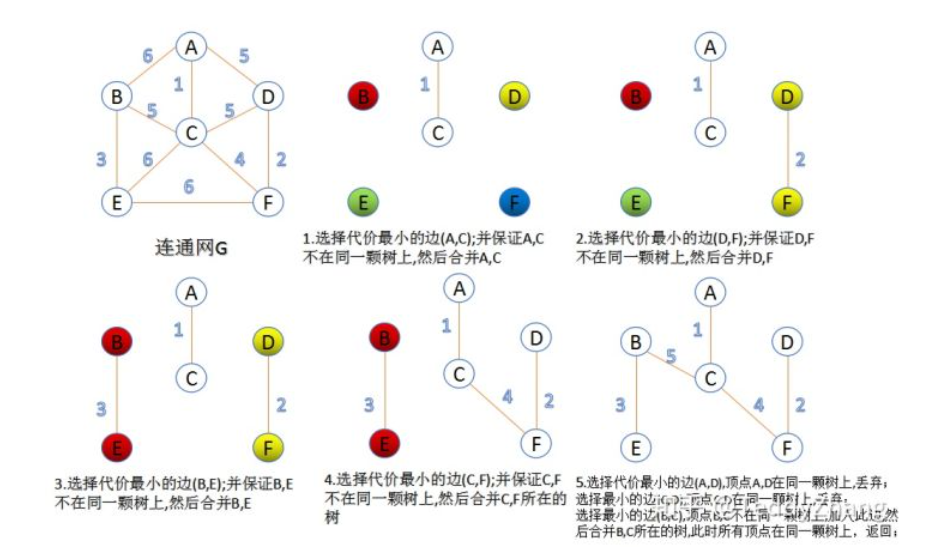
普利姆算法:是贪心算法。与上面主要对边操作的克鲁斯卡算法不同的是,普利姆算法主要是对点进行操作。
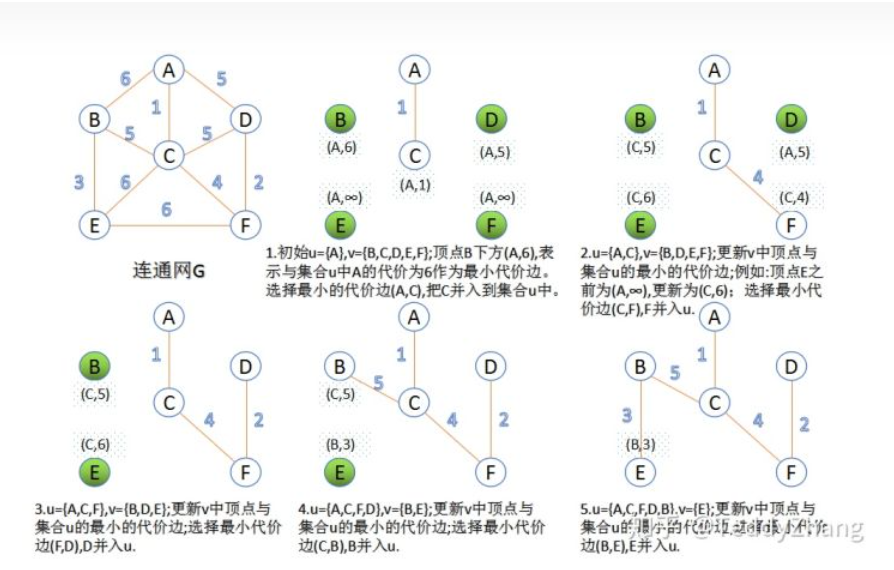
最短路径算法Dijkstral:
求解一个点v到其他各点最小路径的方法。算法步骤为:
n次循环至n个顶点全部遍历:
1.从权值数组中找到权值最小的,标记该边端点k
2.打印该路径及权值
3.如果存在经过顶点k到顶点i的边比v到i的权值小
4.更新权值数组及对应路径
集合Set?
集合中的对象不按待定方式排序,且没有重复对象

 浙公网安备 33010602011771号
浙公网安备 33010602011771号