
第一次接触爬虫,之所以选择WebMagic,是因为文档齐全、用法简单、而且框架一直在维护。
WebMagic是一个简单灵活的Java爬虫框架。基于WebMagic,我们可以快速开发出一个高效、易维护的爬虫。
官网地址:http://webmagic.io/
官方文档:http://webmagic.io/docs/zh/
文档写的很详细,重头到尾看一遍,编写简单的爬虫基本上没有任何问题了(如果不行,那就看两遍)。
我这里就不在讲解怎么使用了(讲解的没有官网详细,甚至可能讲错)。这里我放两个我写的小工具。简单的网站可以用它直接抓取。
上图
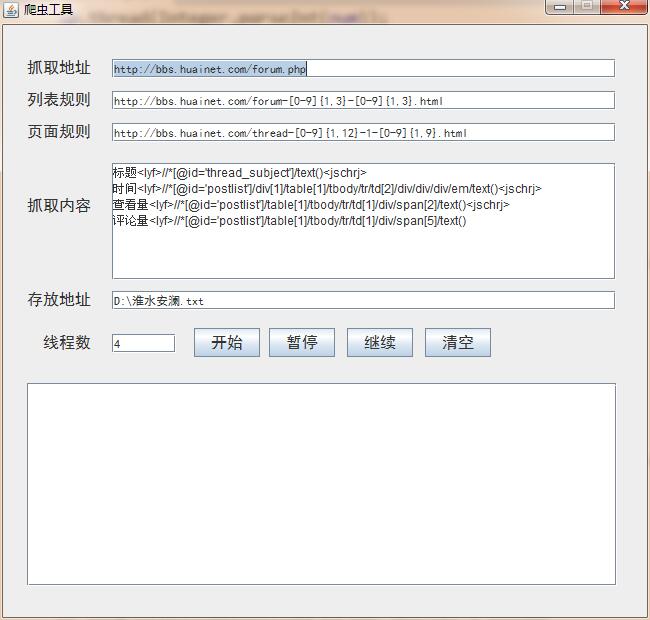
抓取地址:是我们的起始网页。
列表规则(正则表达式):存放具体页面链接的列表页面
页面规则(正则表达式):我们要抓取的具体页面
抓取内容(Xpath):我们要抓取的具体内容,其中"<jschrj>" 为每个字段的分隔符,“<lyf>”是字段显示的名称和内容的分隔符。
存放地址:爬取下来的文件存放的位置。
线程数:开启多少个线程爬取(没有用代理,所以线程开多了,IP容易被网站封杀)。
下面的文本框为控制台,用来输出爬取的详细信息。
工具下载地址:https://download.csdn.net/download/lyfzxf/10533865。
源码下载地址:https://download.csdn.net/download/lyfzxf/10533892。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号