一.状态估计的解释

我们知道每个方程都受噪声的影响,这里把位姿x和路标y看成服从某种概率分布的随机变量。因此我们关心的问题就变成了:当我们已知某些运动数据u和观测数据z时,如何确定状态量x,y的分布?比较常见且合理的情况下,我们假设状态量和噪声项服从高斯分布---这意味着在程序中只需存储它们的均值和协方差即可。均值可看作是对变量最优值的估计,而协方差矩阵度量了它的不确定性。如果认为k时刻状态只与k-1时刻状态有关,而与再之前无关,我们就会得到以卡尔曼滤波(EKF)为代表的滤波器方法,在滤波方法综合那个,我们会将某时刻的状态估计,推导到下一时刻;另一种方法考虑k时刻状态与之前所有状态的关系,将得到以非线性优化为主体的优化框架。目前SLAM的主流是非线性优化方法。
二.EKF
[1] 卡尔曼滤波 -- 从推导到应用(一)
卡尔曼滤波 -- 从应用(一) 到 (二)
|
高斯分布,又称为正态分布:  |
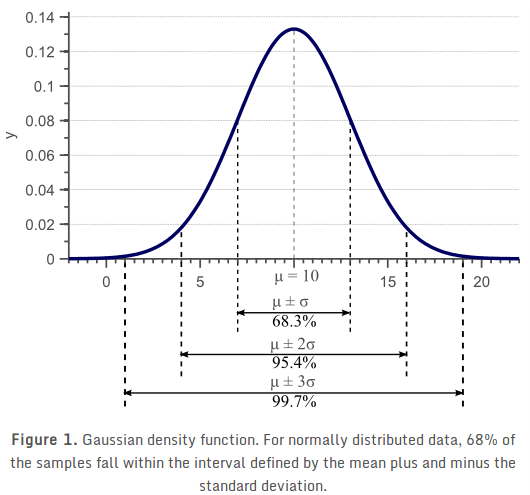
|
样本方差的无偏估计可以通过以下方式获得(μ为期望,即均值):
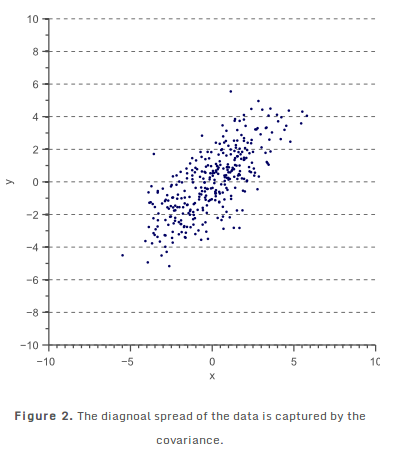
方差只能用来解释数据在与特征空间轴线平行的方向上的传播。图2所示的2d特征空间: 协方差: 协方差矩阵: 二维正态分布数据完全由均值和2×2协方差矩阵来解释。类似地,一个3×3的协方差矩阵用于捕捉三维数据的传播,而n×n次协方差矩阵捕捉n维数据的传播。
前两个:协方差对称,最大方差方向与轴不重合,并且数据被旋转。 后两个:协方差为0,最大方差方向是轴对齐
2.特征值分解Eigendecomposition of a covariance matrix 3.Covariance matrix as a linear transformation 协方差矩阵的特征向量的最直观的解释之一是,它们是数据变化最多的方向。(更准确地说,第一特征向量是数据变化最多的方向,第二特征向量是那些正交(垂直)到第一特征向量的最大方差的方向,第三个特征向量是与前两个正交的最大方差的方向,等等)。下面是2个维度的示例[ 1 ]:
每个数据样本是一个2维点,坐标x,y。这些数据样本的协方差矩阵的特征向量是向量u和v;u,长箭头,是第一特征向量,v,短箭头,是第二个。(特征值是箭头的长度),正如你所看到的,第一个特征向量点(从数据的平均值)到数据在欧氏空间中变化最大的方向,第二特征向量是正交的(垂直的)到第一个。
在这种情况下,假设所有的数据点都位于椭球内。V1,方向的数据变化最大,是第一特征向量(λ1是相应的特征值)。V2是在那些与V1正交的方向上数据变化最大的方向。V3是那些方向与V1和V2正交的最大方差方向(虽然只有一个这样的正交方向)。 |
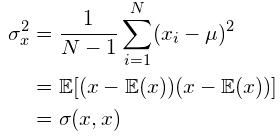
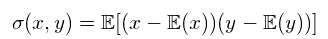
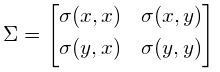 ,其中
,其中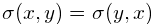


[2]卡尔曼滤波原理及实现---介绍的详细,适合初学者;卡尔曼增益K解释的较好
http://www.tina-vision.net/docs/memos/2003-003.pdf
|
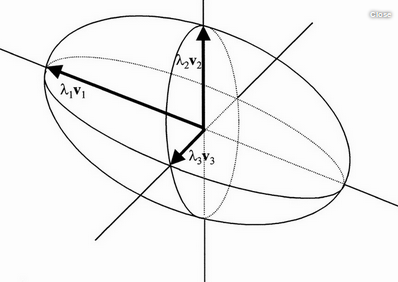
在求解卡尔曼增益的过程中: 对两个云团进行重叠,找到重叠最亮的点(实际上我们能够把云团看做一帧图像,这帧图像上面的每一个像素具有一个灰度值,灰度值大小代表的是该事件发生在这个点的概率密度),最亮的点,从直觉上面讲,就是以上两种预测准确的最大化可能性,也就是得到了最终的结果。非常神奇的事情是,对两个高斯分布进行乘法运算,得到新的概率分布规律仍然符合高斯分布,然后就取下图当中蓝色曲线峰值对应的横坐标不就是结果了嘛。证明如下: σ
是不是下式成立:
注意:我这里铅笔书写的标注和上面博客中的是反的,只要按步骤推导还是容易理解的。 N
|

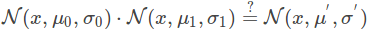
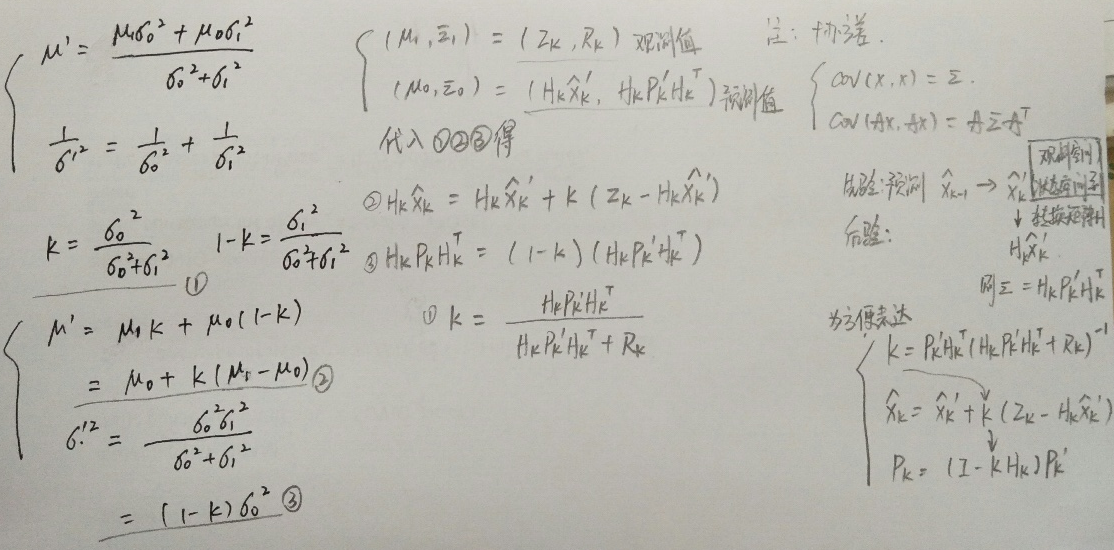

 浙公网安备 33010602011771号
浙公网安备 33010602011771号