

摘要:最近,讨论到数据库的优化问题,查看了很多网上的文章,说得都不是很全,有些经过测试还有错误,所以抽点空余时间写下这篇随笔,希望能对你有所帮助。
1、数据准备
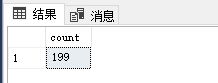
首先要准备数据来进行测试,这里我们准备了两张员工表,Employee表220888条数据,Employee_B 199条数据

2、SQL Server性能优化之SQL语句总结
1、SELECT
尽量避免使用SELECT * 应根据需求在SELECT中指定列 SELECT item1,item2,如图
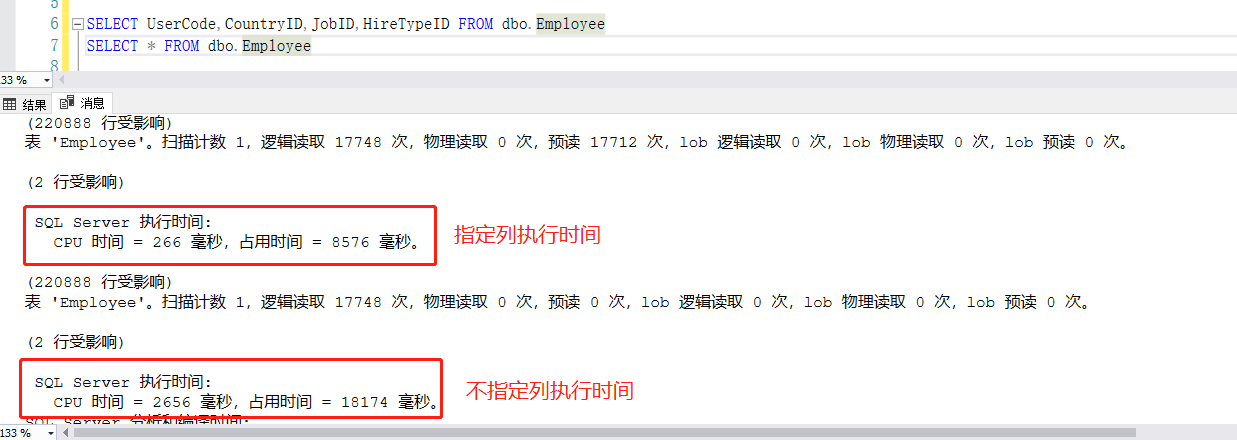
在select中指定所需要的列,将带来的好处:
(1)减少内存耗费和网络的带宽
(2)更安全
(3)给查询优化器机会从索引读取所有需要的列
2、COUNT(*)、COUNT(1)和COUNT([列])
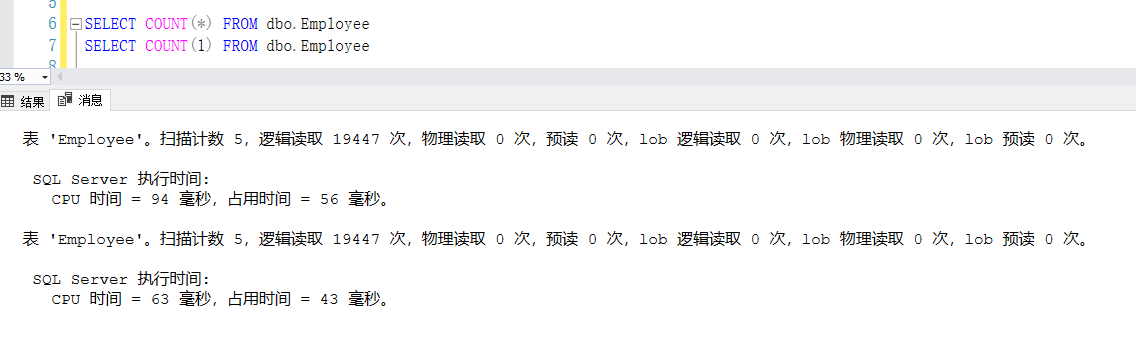
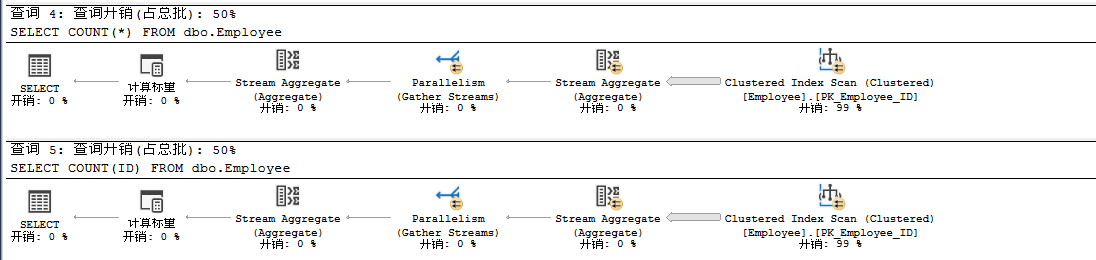
(1)COUNT(*)和COUN(1)的区别:
COUNT(*)和COUNT(1)两者没有太大的区别,执行结果都是一样的,根据当时的业务场景,选择适用的Count,相对来说Count(1)的执行时间比较少。如图
(2)COUNT(*)和COUNT([列])的区别:
COUNT(*) 返回组中的项数。包括 NULL 值和重复项。
COUNT([列]) 返回非空值的数量
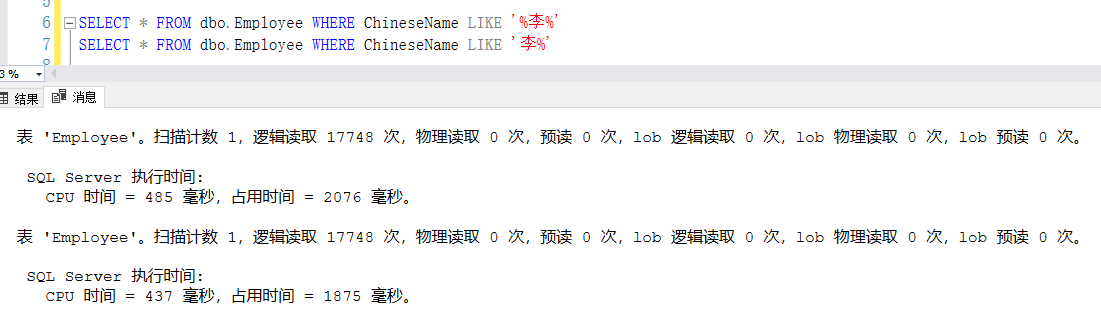
3、LIKE
应尽量避免'%Item%'的方式,除非必要,否则不要在关键字前加%,如下图
4、IN 、NOT IN、EXISTS、NOT EXISTS
1、IN 和 EXISTS区别:
IN 是把外表和内表作hash 连接,而EXISTS是对外表作loop循环,每次loop循环再对内表进行查询。EXISTS 和 IN 在执行时效率基本一致,执行时间相差不大(执行10次有时EXISTS快有时IN快,经测试:数据量小的表为主表速度会快很多,如果数据量一致,根据个人爱好选择)。如下图
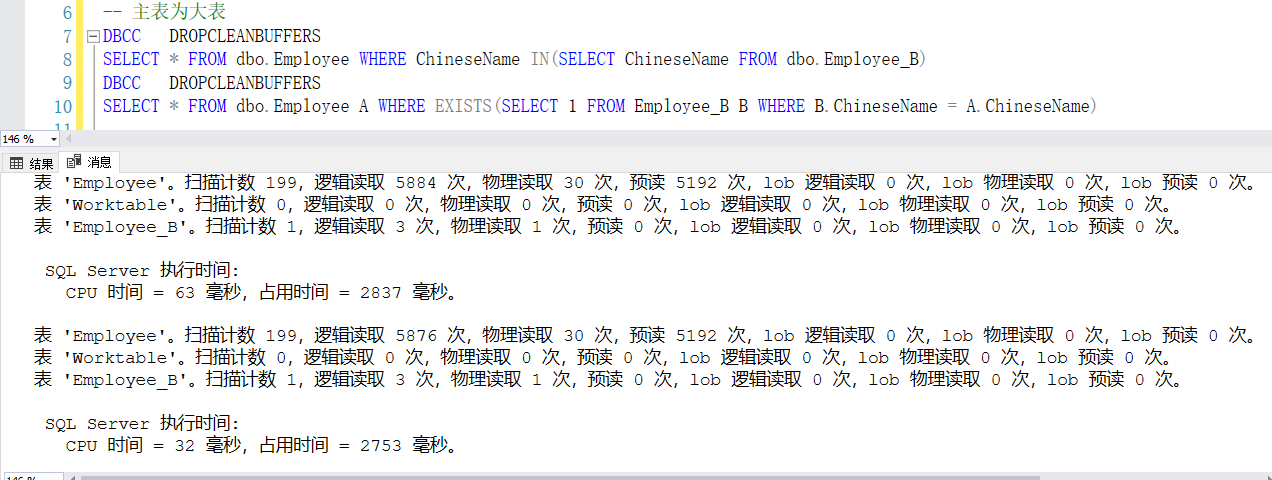
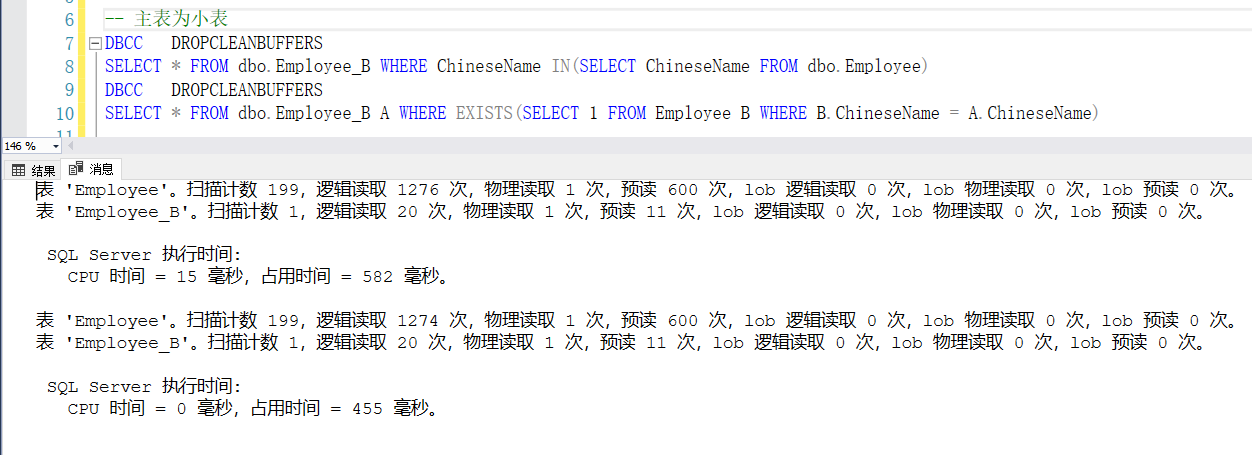
2、NOT IN 和 NOT EXISTS区别:
NOT IN 在查询时主子查询都进行全表扫描,且没有用到索引;NOT EXISTS 的子查询会使用表中索引,所以无论主子结果集的大小 。所以NOT EXISTS执行效率都要比NOT IN高,如下图
5、IS NULL、IS NOT NULL
(1)应尽量避免在 WHERE子句中对字段进行 NULL值判断,否则将导致引擎放弃使用索引而进行全表扫描,如下图
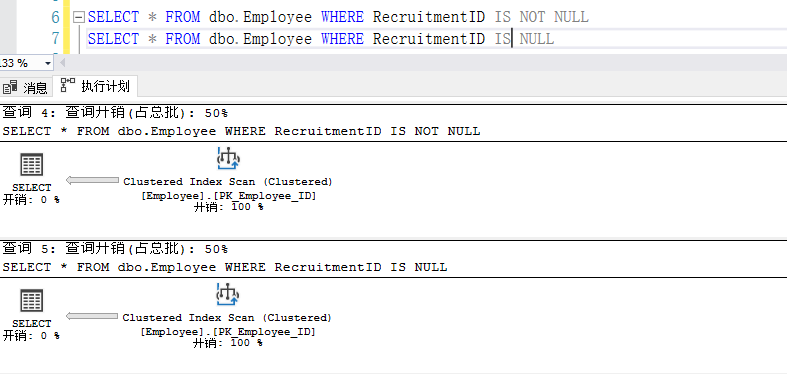
(2)尽可能不要给数据库留NULL,备注、描述、评论之类的可以设置为 NULL,其他的,最好不要使用NULL。如下图(使用了索引)
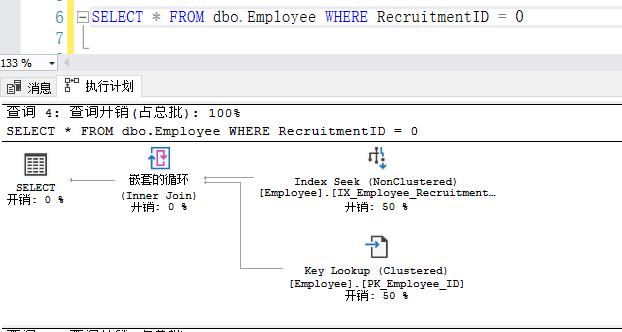
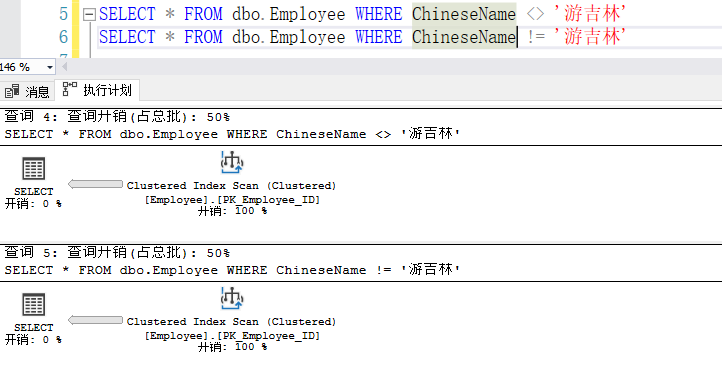
6、!=、<>
在where子句中使用 != 或 <>操作符,索引将被放弃使用,会进行全表查询。如下图

 浙公网安备 33010602011771号
浙公网安备 33010602011771号