


问题:从食品伙伴网上爬取txt,先爬取了<a>标签下的链接url,保存在txt中,然后遍历txt中的url,通过selenium.webdriver.Chrome().get(url)得到url页面的内容(就是get(url)出错了),然后取所需要的。错误如下:
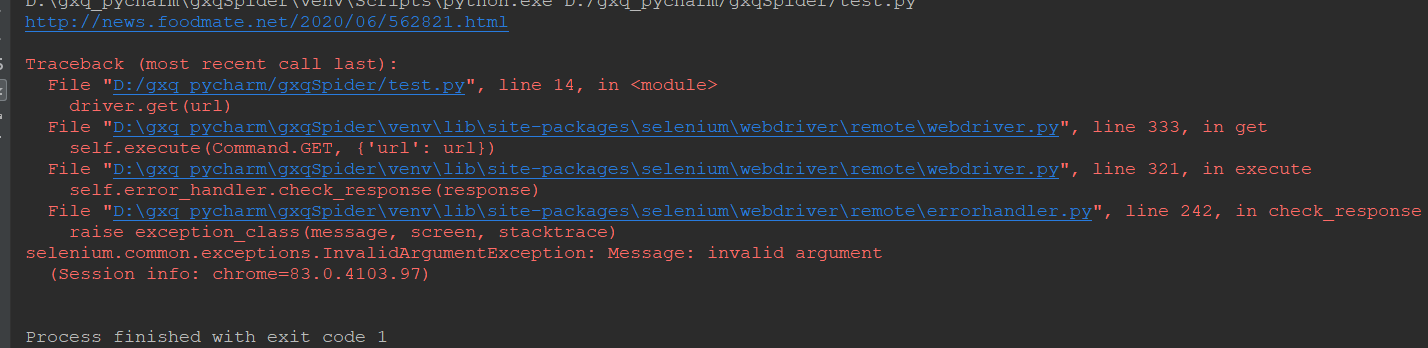
百度解决啊,找到了一个类似问题的博客还解决不了我的问题,只能自己捣鼓。
遍历url,get(url)关键代码如下:
1 2 3 4 | urls = open("finalUrls.txt", 'r', encoding="utf8")driver = webdriver.Chrome("E:\\chromedriver_win32\\chromedriver.exe")for url in urls: driver.get(url) |
这始终发现不了错误,找到个解决方法,就是取出来的url放在一个list中,然后遍历这个列表取get,结果还是不行。代码如下:
1 2 3 4 | urls = open("finalUrls.txt", 'r', encoding="utf8")urls = urls.read().split() # 加了此行,就是放在了list中driver = webdriver.Chrome("E:\\chromedriver_win32\\chromedriver.exe")for url in urls: driver.get(url) |
接着调,自己捣鼓,是不是把url转成str就行了,好像本就是str,试试吧,不怕啥。结果不行。
接着试:在for循环里加入了split,即url = url.split()
错误依旧,但是发现一个好玩意,如下:
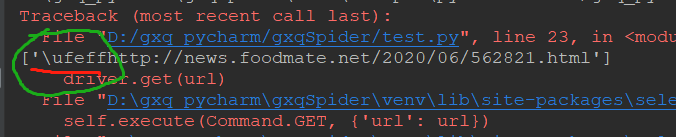
然后就想啊,是不是因为这么个东西搞得我get不了啊。百度去, https://www.cnblogs.com/chongzi1990/p/8694883.html
说是编码的问题,我一开始保存的时候是utf8啊,就按照人家的试试呗,utf-8-sig,然后问题解决。。。
1 2 3 4 | urls = open("finalUrls.txt", 'r', encoding="utf-8-sig")driver = webdriver.Chrome("E:\\chromedriver_win32\\chromedriver.exe")for url in urls: driver.get(url) |
总结:就是\ufeff这么个东西搞我


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 25岁的心里话
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现