
转载自:http://www.cnblogs.com/xrq730/p/4841518.html
public class TestMain { public static void main(String[] args) { String str0 = "123"; String str1 = "123"; System.out.println(str0 == str1); } }
结果:true
public class TestMain { public static void main(String[] args) { String str2 = new String("234"); String str3 = new String("234"); System.out.println(str2 == str3); } }
结果:false
原因:
在JVM中有一块区域叫常量池,常量池中的数据是那些在编译期间被确定,并被保存在已编译的.class文件中的一些数据。除了包含所有的8种基本数据类型(char, byte, short, int, long, float, double, boolean)外,还有String及其数组的常量值,另外还有一些以文本形式出现的符号引用。
Java栈的特点是存取速度快(比堆块),但是空间小,数据生命周期固定,只能生存到方法结束。我们定义的boolean b = true、char c = 'c'、String str = “123”,这些语句,我们拆分为几部分来看:
1、true、c、123,这些等号右边的指的是编译期间可以被确定的内容,都被维护在常量池中
2、b、c、str这些等号左边第一个出现的指的是一个引用,引用的内容是等号右边数据在常量池中的地址
3、boolean、char、String这些是引用的类型
栈有一个特点,就是数据共享。回到我们第一个例子,第五行String str0 = "123",编译的时候,在常量池中创建了一个常量"123",然后走第六行String str1 = "123",先去常量池中找有没有这个"123",发现有,str1也指向常量池中的"123",所以第七行的str0 == str1返回的是true,因为str0和str1指向的都是常量池中的"123"这个字符串的地址。当然如果String str1 = "234",就又不一样了,因为常量池中没有"234",所以会在常量池中创建一个"234",然后str1代表的是这个"234"的地址。分析了String,其实其他基本数据类型也都是一样的:先看常量池中有没有要创建的数据,有就返回数据的地址,没有就创建一个。
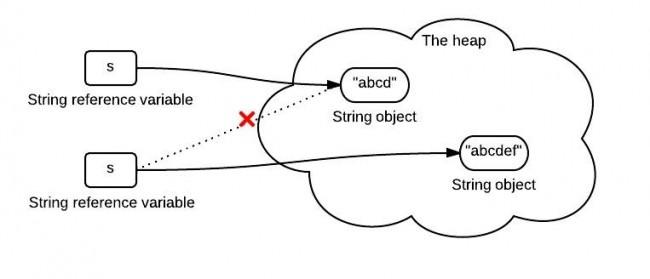
第二个例子呢?Java虚拟机的解释器每遇到一个new关键字,都会在堆内存中开辟一块内存来存放一个String对象,所以str2、str3指向的堆内存中虽然存储的是相等的"234",但是由于是两块不同的堆内存,因此str2 == str3返回的仍然是false,网上找到一张图表示一下这个概念:
为什么要使用StringBuilider和StringBuffer拼接字符串?
public class StringTest { @Test public void testStringPlus() { String str = "111"; str += "222"; str += "333"; System.out.println(str); } }
编译器每次碰到"+"的时候,会new一个StringBuilder出来,接着调用append方法,在调用toString方法,生成新字符串。
那么,这意味着,如果代码中有很多的"+",就会每个"+"生成一次StringBuilder,这种方式对内存是一种浪费,效率很不好。
以StringBuilder为例:
public class TestMain { public static void main(String[] args) { StringBuilder sb = new StringBuilder("111"); sb.append("222"); sb.append("111"); sb.append("111"); sb.append("444"); System.out.println(sb.toString()); } }
StringBuffer和StringBuilder原理一样,无非是在底层维护了一个char数组,每次append的时候就往char数组里面放字符而已,在最终sb.toString()的时候,用一个new String()方法把char数组里面的内容都转成String,这样,整个过程中只产生了一个StringBuilder对象与一个String对象,非常节省空间。StringBuilder唯一的性能损耗点在于char数组不够的时候需要进行扩容,扩容需要进行数组拷贝,一定程度上降低了效率。
StringBuffer和StringBuilder用法一模一样,唯一的区别只是StringBuffer是线程安全的,它对所有方法都做了同步,StringBuilder是线程非安全的,所以在不涉及线程安全的场景,比如方法内部,尽量使用StringBuilder,避免同步带来的消耗。
另外,StringBuffer和StringBuilder还有一个优化点,上面说了,扩容的时候有性能上的损耗,那么如果可以估计到要拼接的字符串的长度的话,尽量利用构造函数指定他们的长度。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号