本文如果有错,欢迎留言更正;此外,转载请标明出处 http://www.cnblogs.com/IClearner/ ,作者:IC_learner
对进行时序路径、工作环境、设计规则等进行约束完成之后,DC就可以进行综合、优化时序了,DC的优化步骤将在下面进行讲解。然而,当普通模式下不能进行优化的,就需要我们进行编写脚本来改进DC的优化来达到时序要求。理论部分以逻辑综合为主,不涉及物理库信息。在实战部分,我们将在DC的拓扑模式下进行。(本文主要参考虞希清的《专用集成电路设计实用教程》来写的总结整理与实验拓展)主要内容有:
·DC的逻辑综合及优化过程
·时序优化及方法
·实战
1.DC的综合优化阶段
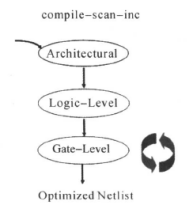
我们使用compile命令就可以让DC进行综合优化我们的设计了,这里是使用普通模式,在拓扑模式下,不支持compile命令,而是使用compile_ultra命令。电路综合优化包括三个阶段,在这三个阶段,都对设计作优化,如下图所示:
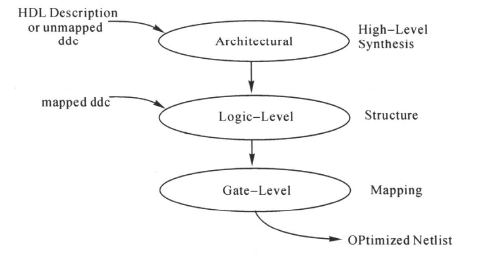
主要包括:第一阶段的结构级的优化(Architectural-Level Optimization)、第二阶段的逻辑级优化(Logic-Level Optimization)、最后阶段的门级优化(Gate-Level Optimization)。
(1)结构级的优化(Architectural-Level Optimization)
结构级优化包括的内容如下:

①设计结构的选择(Implementation Selection):
在DesignWare中选择最合适的结构或算法实现电路的功能。
②数据通路的优化(Data-path Optimization):
选择CSA等算法优化数据通路的设计。
③共享共同的子表达式(Sharing Common Subexpressions):
也就是多个表达式/等式中,有共同的表达式,进行共享,举例如下:
有等式:
SUM1<=A+B+C;
SUM2<=A+B+D;
SUM3<= A+B+E;
很容易看出,上面的等式中有共同的表达式A+B,那么代码子表达式A+B可以被共用,原等式可改为:
Temp=A+B;
SUM1<=Temp+C;
SUM2<= Temp+D;
SUM3<=Temp+E;
这种方法可以把比较器的数目减少,共享共同的子表达式。
④资源共享(Resource Sharing):
对于下面的代码:

DC中经过资源共享之后,就会得到综合出仅用一个加法器和两个多路传输器的设计,如下图所示,从而节省资源:

算术运算资源共享的默认策略是约束驱动的。我们也可以指示DC使用面积优化的策略。即将变量hlo_resource_allocation设置为area,如下所示:
set hlo_resource_allocation area
如果不希望资源共享,可以将即将变量hlo_resource_allocation设置为none,这时候,我们还是要进行算术运算的资源共享,那么我们必须在RTL代码中写出相应的代码,如下所示:

⑤重新排序运算符号(Reordering Operators):
RTL代码包含有电路的拓扑结构。HDL编译器从左到右解析表示式。括号的优先级更高。DC中DesignWare以这个次序作为排序的开始。
例如:表达式SUM<= A*B+C*D+E+F+G,在DC中的综合的结构如下图所示:
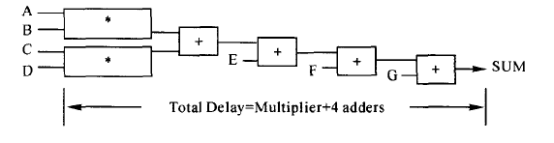
电路的总延迟等于一个乘法器的延迟加上4个加法器的延迟。为了使电路的延迟减少,我们可以改变表达式的次序或用括号强制电路用不同的拓扑结构。如:

这时得到的综合结构为:
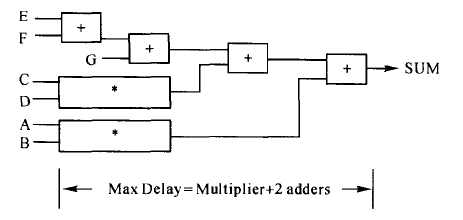
电路的总延迟等于一个乘法器的延迟加上2个加法器的延迟,比原来的电路少了2个加法器的延迟。
(2)逻辑级优化(Logic-Level Optimization)
逻辑优化的内容如下:

做完结构的优化后,电路的功能以GTECH的器件来表示。在逻辑级优化的过程中,可以作结构(Structuring)优化和展(开)平(Flattening)优化。
①结构优化:
结构(Structuring)优化用共用子表达式来减少逻辑,这种方式既可用作速度优化又可用作面积优化。结构优化是DC默认的逻辑级优化策略。结构优化在作逻辑优化时,在电路中加入中间变量和逻辑结构。DC作结构优化时,寻找设计中的共用子表达式。例如,对于下面的电路,优化前为:
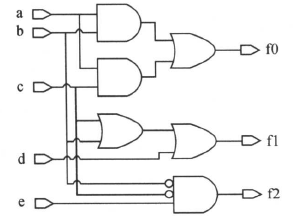

做完结构优化后,电路和功能表达式为:

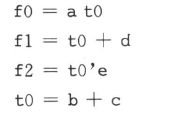
值得一提的是逻辑级的结构优化中共用子表达式和前面结构级的共用子表达式是不同的,逻辑级的结构优化指门级电路的共用子表达式,结构级的是算术电路的共用子表达式。逻辑级结构优化并不会改变设计的层次,用下面的命令设置结构优化:
set_structure true
②展平优化:
展平优化把组合逻辑路径减少为两级,变为乘积之和(sum-of-products,简称SOP)的电路,即先与(and)后或(or)的电路,如下图所示:
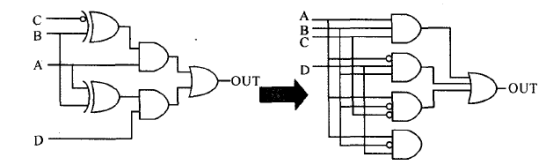
这种优化主要用作速度的优化,电路的面积可能会很大。用下面的命令设置展平优化:
set_flatten true -effort low | medium | high(low 、 medium、high其中一个就可以了)
命令选项“-effort”后的默认值为low,对大部分设计来说,默认值都能收到好的效果。如果电路不易展平,优化就停止。如果把选项“-effort”后的值设为medium, DC将花更多的CPU时间来努力展平设计。如果把选项“-effort”后的值设为high,展平的进程将继续直到完成。这时,可能要花很多时间进行展平优化。
结构(Structuring)优化和展平(Flattening)优化的比较:

(3)门级优化(Gate-Level Optimization)
门级优化时,Design Compiler开始映射,完成实现门级电路。主要有以下内容:
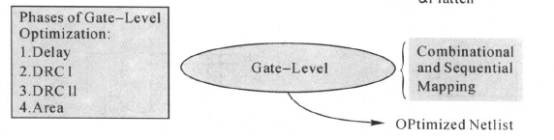
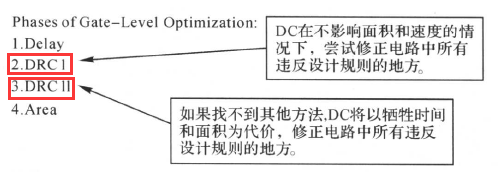
映射的优化过程包括4个阶段:
阶段1:延迟优化、阶段2:设计规则修整、阶段3:以时序为代价的设计规则修整、阶段4:面积优化。
如果我们在设计上加入了面积的约束,Design Compiler在最后阶段(阶段4)将努力地去减少设计的面积。门级优化时需要映射组合功能和时序功能:
组合功能的映射的过程为:DC从目标库中选择组合单元组成设计,该设计能满足时间和面积的要求,如下图所示:


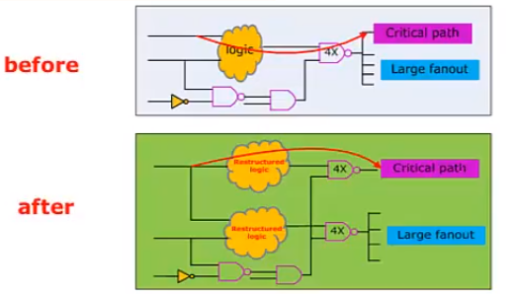

时序功能的映射的过程为:DC从目标库中选择时序单元组成设计,该设计能满足时间和面积的要求,为了提高速度和减少面积,DC会选择比较复杂的时序单元,如下所示:
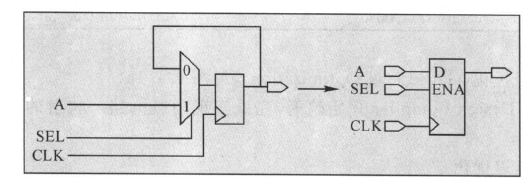


设计规则修整的介绍如下:工艺库中包括厂商为每个单元指定的设计规则。设计规则有:max_capacitance,max_transition和max_fanout。映射过程中,DC会检查电路是否满足设计规则的约束,如有违反之处.DC会通过插入缓冲器( buffers)和修改单元的驱动能力(resizes cells)进行设计规则的修整。修正设计规则的步骤如下所示:
DC进行进行优化的时候,如果下面的条件之一都满足了:
①所有的约束都满足了;②用户中断;③Design Compiler到了综合结果收益递减的阶段,即再综合下去对结果也不能有多大的改善。
这时DC就会进行中断优化,停止综合。
(4)其他的优化情况(需要加上一定的综合选项开关)
比如一个寄存器驱动多个寄存器时,可能会违反设计规则,DC会把就驱动寄存器进行复用,同时把被驱动的进行分割,如下图所示:
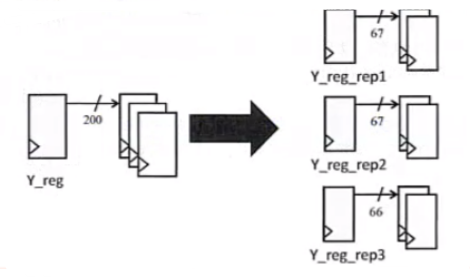
(使用DC的拓扑模式,加上 -timing选项才能自动地使用上面的这种寄存器复制的优化)
当你的设计中出现多次例化的情况时,也就是下面的情况:

在这种情况下,DC在编译时,会复制每个例化的模块。每个模块对应一个拷贝,并且有一个独一无二的名字。这样DC可以根据每个模块本身特有的环境做优化和映射,如下图所示((模块名字唯一化)):
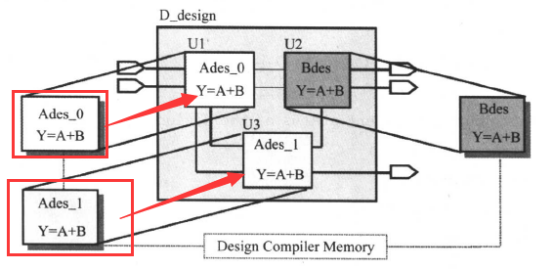
在DC里,我们可以用uniquify命令为设计中的每一个模块产生一个名字唯一的拷贝。DC在为设计做综合(compile)时,也会自动地为每一个模块产生一个唯一的有名字的拷贝。变量uniquify_naming_style可以用来控制多次例化子模块每个拷贝的命名方式。其详细的使用方法可以在DC'中用“man uniquify_naming_style”来查看。
2.时序优化及方法
DC综合之后,我们查看详细的报告,如果没有违规,设计既能满足时间和面积的要求又不违犯设计规则,那么综合完成。可以把门级网表和设计约束等交给后端(backend)工具做布局(placement )、时钟树综合(clock tree synthesis)和布线(route)等工作,产生GDSII文件。如果设计不能满足时间和面积的要求或违犯设计规则等,就要分析问题所在,判断问题的大小,然后采取适当的措施解决问题。问题往往是时序的问题,发生时序违规时可以采取相应的措施,如下图所示:
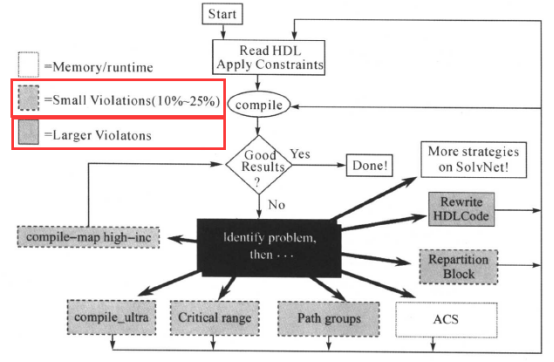
(1)当违规得比较严重时,也就是时序的违规(timing violation)在时钟周期的25%以上时,就需要重新修改RTL代码了。
(2)时序违规在25%以下,有下面的时序优化方法:
①使用compile_ultra命令(在拓扑模式下运行)
compile_ultra跟compile一样,是进行编译的命令。compile_ultra命令适用于时序要求比较严格,高性能的设计。使用该命令可以得到更好的延迟质量( delay QoR ),特别适用于高性能的算术电路优化。该命令非常容易使用,它自动设置所有所需的选项和变量。下面是这个命令的一些介绍:
compile_ultra命令包含了以时间为中心的优化算法,在编辑过程中使用的算法有:A以时间为驱动的高级优化(Timing driven high-level optimization);B为算术运算选择适当的宏单元结构;C从DesignWare库中选择最好的数据通路实现电路;D映射宽扇入(Wide-fanin)门以减少逻辑级数;E积极进取地使用逻辑复制进行负载隔离;F在关键路径自动取消层次划分(Auto-ungrouping of hierarchies)。
compile_ultra命令支持DFT流程,此外compile_ultra命令非常简单易用,它的开关选项有:
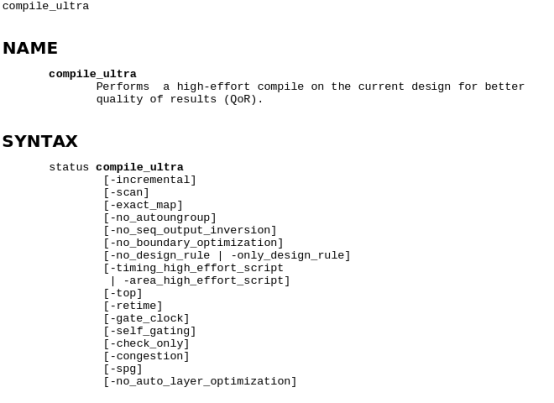
部分解释如下所示:
-scan :做可测试(DFT)编辑;
-no_autoungroup :关掉自动取消划分特性;
-no_boundary_optimization :不作边界优化;
-no_uniquify : 加速含多次例化模块的设计的运行时间
-area_high_effort_script : 面积优化
-timinq_high_effort_script : 时序优化
上面的开关部分说明如下所示:
·使用compile_ultra命令时,如使用下面变量的设置,所有的DesignWare层次自动地被取消:
set compile_ultra_ungroup_dw true (默认值为true)
也就是说,你调用的一个加法器和一个乘法器,本来他们是以IP核的形式,或者说是以模块的形式进行综合的,但是设置了上面那么变量之后,综合后那个模块的界面就没有了,你不知道哪些门电路是加法器的,哪些是乘法器的。
使用compile_ultra命令时,使用下面的变量设置,如果设计中有一些模块的规模小于或等于变量的值,模块层次被自动取消:
set compile_auto_ungroup_delay_num_cells 100(默认值=500)
也就是说,假设你有一个模块A是一个小的乘法器,并且调用了模块B,一个模块B是一个小的加法器,使用没有设置这条命令的情况综合,那么我们可以看到模块A中乘法器对应的门电路是哪些,同样也可以看到模块B的加法器是由哪些门电路构成的,模块A和模块B之间有层次、有界限;当设置上面的那条命令之后,我们就看不到模块A或者模块B之间的层次关系了,也看不到乘法器是由哪些门电路构成,或者说你看到了某一个与门,但是你并不知道它是构成乘法器的还是构成加法器的。
为了使设计的结果最优化,我们建议将compile_ultra命令和DesignWare library一起使用。
·边界优化是指在编辑(又叫综合)时,Design Compiler会对传输常数、没有连接的引脚和补码(complement)信息进行优化,如下图所示:
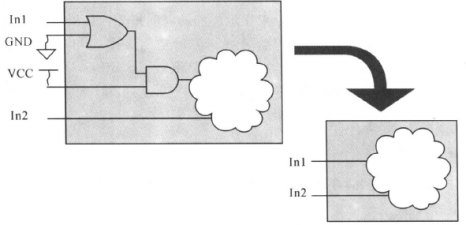
也就是说,边界优化会把边界引脚一些固定的电平、固定的逻辑进行优化。
此外,在DC Ultra(或者DC的拓扑模式下)中,我们可以用Behavioral ReTiming(简称BRT)技术,对门级网表的时序进行优化,也可以对寄存器的面积进行优化。BRT通过对门级网表进行管道传递(pipeline)(或者称之为流水线),使设计的传输量(throughput)更快。BRT有两个命令:
optimize_registers :适用于包含寄存器的门级网表(不是compile_ultra的开关选项)。
pipeline_design :适用于纯组合电路的门级网表。
对于寄存器的的优化,举例如下,对于下面的电路,既包含有组合逻辑电路又包含有寄存器:
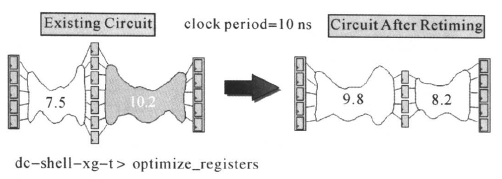
后级的寄存器与寄存器之间的时序路径延迟为10. 2 ns,而时钟周期为10 ns,因此,这条路径时序违规。但是前级的寄存器与寄存器之间的时序路径延迟为7. 5 ns,有时间的冗余。使用optimize_registers命令,可以将后级的部分组合逻辑移到前级,使所有的寄存器与寄存器之间的时序路径延迟都小于时钟周期,满足寄存器建立时间的要求。optimize_registers命令首先对时序做优化,然后对面积作优化。优化后,在模块的入/输出边界,电路的功能保持不变。该命令只对门级网表作优化。
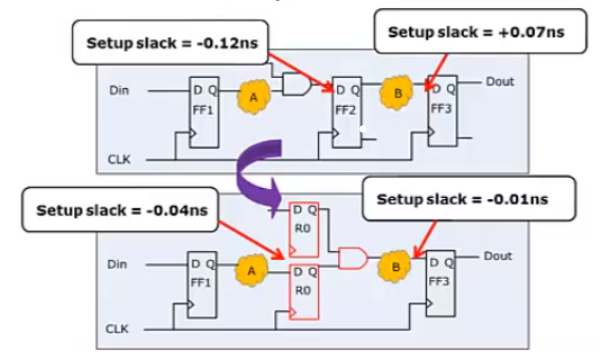
除了单独使用这个命令之外,还可以在编译的时候往往加上选项-retime(这个好像只有compile_ultra才有这个开关选项)。-retime选项的功能也就是:当有一个路径不满足,而相邻的路径满足要求时,DC会进行路径间的逻辑迁移,以同时满足两条路径的要求,这也叫adaptive retiming,如下图所示:



对于纯组合逻辑的流水线(管道)优化,举例如下,对于纯组合逻辑电路进行优化如下所示:
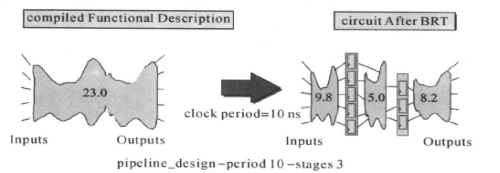
左边电路,是一个纯组合电路,它的路径延迟为23. 0 ns。对这个电路进行管道传递优化后,得到右边所示的电路。显然,电路的传输量(throughput)加快了。需要注意的是,在使用这个命令时,需要在RTL设计中把寄存器预置好,否则DC不知道这些寄存器是怎么来的。
②使用compile -scan -inc 命令
-inc 是使用增量编译。这条命令就是进行支持可测性设计的增量编译。使用增量编辑时,DC只作门级优化,这时,设计不会回到GTECH,如下图所示:


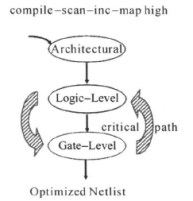
③使用自定义路径组合关键范围
在介绍这种优化方法之前,先来了解一下路径分组与延时。
·路径分组:
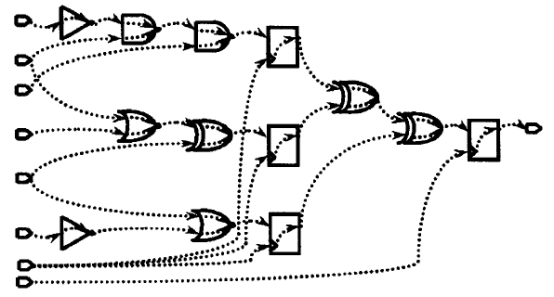
DC为了便于分析电路的时间,时序路径又被分组。路径按照控制它们终点的时钟进行分组。如果路径不被时钟控制,这些路径被归类于默认(Default)的路径组。我们可以用report_path_group命令来报告当前设计中的路径分组情况。例如,对于下面的电路,我们来看一下路径及分组情况:
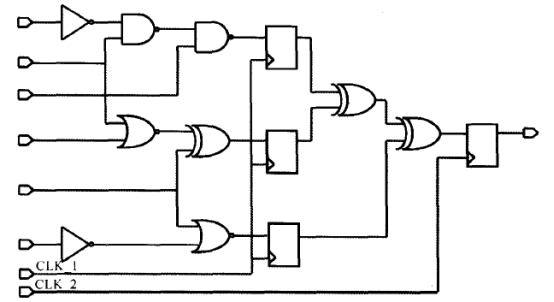
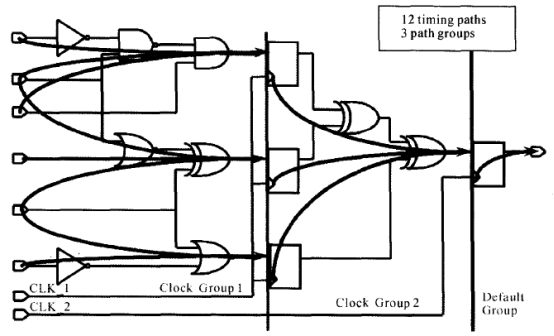
根据上图可以知道,图中共有5个终点(四个寄存器和一个输出)。时钟CLK1控制3个终点,在CLK1的控制下有8条路径。时钟CLK2控制一个终点,在CLK2的控制下有3条路径。输出端口为一终点,它不受任何时钟控制,其起点为第二级寄存器的时钟引脚,在它的控制下只有一条路径,这条路径被归类于默认的路径组。因此,本设计中共有12条路径和3个路径组。该3个路径组分别为CLKI,CLK2和默认(Default )路径组。
·路径的延时:
在计算路径的延迟时,Design Compiler把每一条路径分成时间弧((timine arcs),如下图所示:
DC就是通过时间弧来计算路径延时。因为时间弧描述单元或/和连线的时序特性。单元的时间弧由工艺库定义,包括单元的延迟和时序检查(如寄存器的setup/hold检查,clk->q的延迟等);连线的时间弧由网表定义。在上面电路中,时间弧有连线的延迟,单元的延迟和寄存器的clk -> q延迟。单元延迟常用非线性模型计算;连线延迟在版图前用线负载模型计算;RC寄生参数的分配用操作条件中的“Tree-type”属性决定;工作条件又决定制程、电压和温度对连线及单元延迟的影响。
此外,路径的延迟与起点的边沿有关,如下图所示:
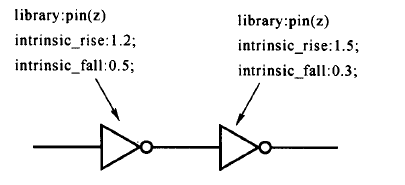
假设连线延迟为0,如果起点为上升沿,则该条路径的延迟等于1. 5 ns。如果起点为下降沿,则该条路径的延迟等于2. 0 ns。由此可见,单元的时间弧是边沿敏感的。Design Compiler说明了每一条路径延迟的边沿敏感性。还有需要强调的是Design Compiler默认的行为是假设寄存器之间的最大延迟约束为:TCLK - FF21ibSetup,即数据从发送边沿到接收边沿的最大延迟时间要小于一个时钟周期,如下图所示:
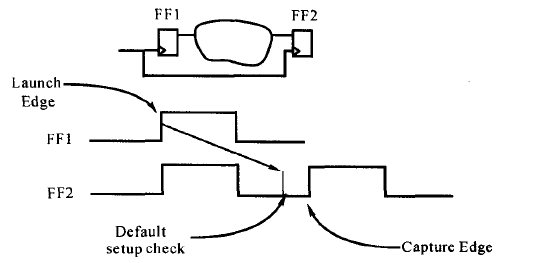
Design Compiler中,常用report_timing命令来报告设计的时序是否满足目标。执行report_timing命令时,DC做4个步骤:
·把设计分解成单独的时间组;
·每条路径计算两次延迟,一次起点为上升沿,另一次起点为下降沿;
·在每个路径组里找出关键路径(critical path),即延迟最大的路径;
·显示每个时间组的时间报告。
关于怎么阅读时序报告,我们后面进行介绍。
DC的默认行为是对关键路径作优化。当它不能为关键路径找到一个更好的优化解决方案时,综合过程就停止。DC不会对次关键路径(Sub-critical paths)作进一步的优化。因此,如果关键路径不能满足时序的要求,违反时间的约束,次关键路径也不会被优化,它们仅仅被映射到工艺库,如下图所示:

对于下面的电路,假设加设计约束后,所有的路径属于同样的时钟组,也就是只有一个路径组:
如果组合电路部分的优化不能满足时序要求,并且关键路径在组合电路里,根据DC的默认行为,组合电路中关键路径的优化将会阻碍了与它属于相同时钟组的寄存器和寄存器之间路径的优化。防止出现这种情况可用下面两种方法:自定义路径组和设置关键范围。
·自定义路径组(User-Defined Path Group):
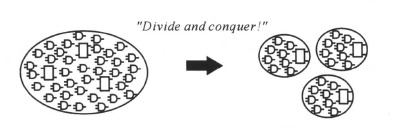
综合时,工具只对一个路径组的最差(延时最长)的路径作独立的优化,但并不阻碍另外自定义路径组的路径优化。产生自定义路径组也可以帮助综合器在做时序分析时采用各自击破(divide-and-conquer)的策略,因为report_timing命令分别报告每个时序路径组的时序路径。这样可以帮助我们对设计的某个区域进行孤立,对优化作更多的控制,并分析出问题所在,如下图所示的:

产生自定义路径组的命令如下所示:
#Avoid getting stuck on one path in the reg-reg group
group_path -name INPUTS -from [all_inputs]
group_path -name OUTPUTS -to [all_outputs]
group_path -name COMBO -from [all_inputs] -to [all_outputs]
上面的命令产生三个自定义的路径组,加上原有的路径组,即寄存器到寄存器的路径组(因为受CLK控制,默认的是CLK的路径组),现在有4个路径组。组合电路的路径,属于“COMBO”组,由于该路径组的起点是输入端,在执行“group_path -name INPUTS -from [all_inputs]”命令后,命令中用了选项“-from [all_inputs]",它们原先属于“INPUTS”组。在执行“group_path -name OUTPUTS -to [all_outputs]”命令后,组合电路的路径不会被移到“OUTPUTS”组,因为开关选项‘'-from”的优先级高于选项”-to”,因此组合电路的路径还是留在“INPUTS”路径组。但是由于“group_path -name COMBO -from [all_inputs] -to [all-outputs]”命令中同时使用了开关选项“-from”和“-to" ,组合电路路径的起点和终点同时满足要求,因此它们最终归属于“COMBO”组。DC以这种方式工作来防止由于命令次序的改变而使结果不同。我们可以用report_path_group命令来得到设计中时序路径组的情况。
产生自定义的路径组后,路径优化如下图所示,此时,寄存器和寄存器之间的路径可以得到优化:
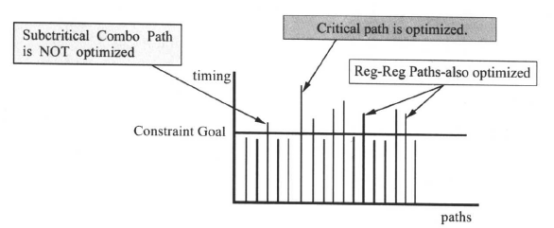
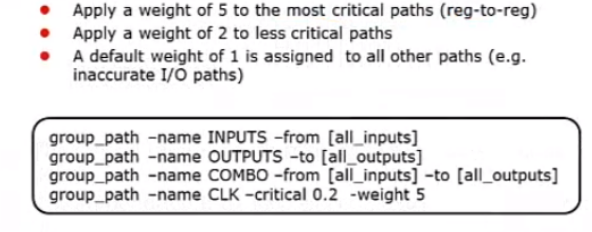
DC可以指定权重进行优化,当某些路径的时序比较差的时候,可以通过指定权重,着重优化该路径。权重最高5,其次是2,默认是1;因此最差的要设置5;如下图所示,下面的命令就是着重优化CLK这个路径组:
·关键范围(Critical Range):
DC默认只对一个路径组内的关键路径进行时序优化,但是我们可以设置DC在关键路径的延时下面某个延时值之内的路径进行优化,因此我们可以使用下面的命令设置关键范围:set_critical_range 2 [current_design]
使用上面的命令之后,DC会对在关键路径2ns的范围内的所有路径作优化,解决相关次关键路径的时序问题可能也可以帮助关键路径的优化。时序优化的示意图如下所示:
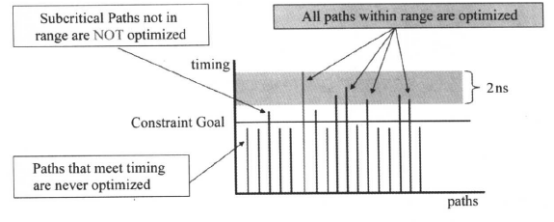
如果在执行set_critical_range命令后,优化时使关键路径时序变差,DC将不改进次关键路径的时序。我们建议关键范围的值不要超过关键路径总值的10%。
·自定义路径组+关键范围
这是将自定义路径组合关键范围结合起来,也就是在每一个路径组用指定的关键范围来设置设计的关键范围,命令如下所示:
group_path -name CLK1 -critical_range 0.3
group_path -name CLK2 -critical_range 0.1
group_path -name INPUTS -from [all_inputs] -critical_range 0
同时使用自定义时序路径组和关键范围,会使DC运行时间加长,并且需要使用计算机的很多内存。但这种方法值得一试,因为DC默认地只在每个路径组优化关键路径。如果在一条路径上关键路径不能满足时间,它不会尝试其他的方法对该时序路径组的其他路径做优化。如果能使DC对更多的路径做优化,它可能在对设计的其他部分做更好的优化。在数据通路的设计中,很多时序路径是相互关联的,对次关键路径的优化可能会改进关键路径的时序。设置关键范围后.即使DC不能减少设计中的最差负数冗余(Worst NegativeSlack,我也不知道这是什么东西),它也会减少设计中总的负数冗余(Total Negative Slack) 。
下面是自定义路径组和关键范围的主要区别:
自定义路径组: 用户自定义路径组后,如果设计的总性能有改善,DC允许以牺牲一个路径组的路径时序(时序变差)为代价,而使另一个路径组的路径时序有改善。在设计中加入一个路径组可能会使时序最差的路径时序变得更差。
关键范围: 关键范围不允许因为改进次关键路径的时序而使同一个路径组的关键路径时序变得更差。如果设计中有多个路径组,我们只对其中的一个路径组设置了关键范围,而不是对整个设计中的所有路径组都设置了关键范围,DC只会并行地对几条路径优化,运行时间不会增加很多。
④重新划分模块(Repartition Block)
模块的划分是在设计一开始就进行的,但是由于我们是注重DC这个工具的使用,因此放在这里讲解。
·层次结构与模块划分:
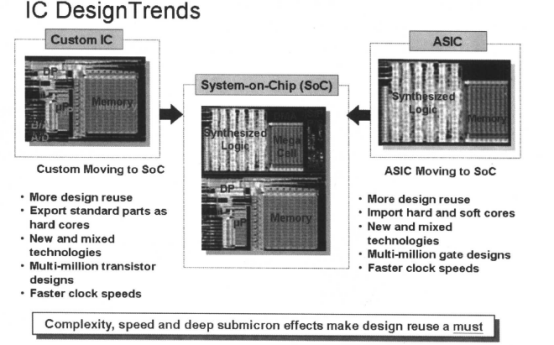
层次结构在IC设计中广泛使用。现代的IC设计中,几乎没有不用层次结构进行设计的。一些大的设计,其逻辑层次可能多达十几层。SoC设计中一般包括设计的再使用和知识产权IP核。SoC设计中包括了多个层次的电路。层次化的IC设计趋势如下所示:
SoC设计由一些模块组成,如下图所示:
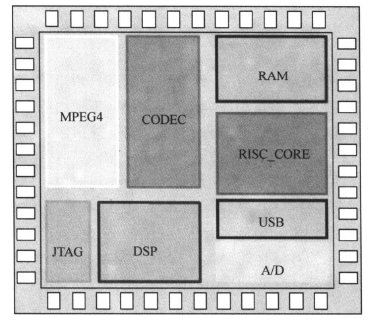
同样,图中已综合逻辑电路(例如RISC_CORE),一般也由一些子模块组成。对于设计复杂规模又大的电路,我们需要对它进行划分(Partitioning),然后对划分后比较简单规模又小的电路作处理(如综合)。这时,由于电路小,处理和分析比较方便简单。容易较快地达到要求。再把已处理好的小电路集成为原来的大电路,如下图所示:
理想情况下,所有的划分应该在写HDL代码前已经计划好。
·初始的划分由HDL定义好.
·初始的划分可以用Desige Compiler进行修改.
做划分的原因很多,下面是其中的几个原因:
·不同的功能块(如Memory,uP,ADC,Codec、控制器等等);
·设计大小和复杂度(模块处理时间适中,设计大小一般设为一个晚上的运行时间,白天进行人工处理和调试,晚上机器运行,第二天上午检查运行结果);
·方便设计的团队管理项目(每个设计工程师负责一个或几个模块);
·设计再使用(设计中使用IP);
·满足物理约束(如用FPGA先做工程样品—Engineering Sample;大的设计可能需要放入多个FPGA芯片才能实现)。
·等等。
划分模块关系到时序,时序不好的情况下,可以进行重新划分模块,因此就要求我们在划分模块的时候,对设计进行合适的划分。
可用例化(instantiation)定义设计的层次结构和模块(hierarchical structure and blocks)。 VHDL的entity和Verilog的module的陈述(statements)定义了新的层次模块,即例化一个entity或module产生一级新的层次结构。如果设计中,我们用符号(+,一,*,/,…)来标示算术运算电路,可能会产生一级新的层次结构。VHDL语言中的Process和Verilog语言中的Always陈述并不能产生一级新的层次。设计时,为了得到最优的电路,我们需要对整个电路作层次结构的设计,对整个设计进行划分,使每个模块以及整个电路的综合结果能满足我们的目标。
例如下面的设计中:

有3个模块:A,B和C。它们各自有输入和输出端口。由于DC在对整个电路做综合时,必须保留每个模块的端口。因此,逻辑综合不能穿越模块边界,相邻模块的组合逻辑也不能合并。从寄存器A到寄存器C的路径的延时较长,这部分的电路面积较大。 如果我们对设计的划分作出修改,相关的组合电路组合到一个模块,原来模块A,B和C中的组合电路没有了层次的分隔,综合工具中对组合电路优化的技术现在能得到充分的使用。这时,电路的面积比原来要小,从寄存器A到寄存器C的路径的延时也短了。修改如下图所示:

如果我们对设计的划分作另一种修改,如下所示,我们将得到最好的划分:
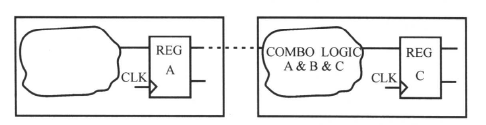
这里的修改将相关的组合电路组合到一个模块,原来模块A,B和C中的组合电路没有了层次的分隔,综合工具中对组合电路优化的技术能得到充分的使用。并且,由于组合电路和寄存器的数据输入端相连,综合工具在对时序电路进行优化时,可以选择一个更复杂的触发器((JK,T,Muxed和Clock-enabled等),把一部分组合电路吸收集成到触发器里。从而使电路的面积更小,从寄存器A到寄存器C的路径的延时更短。
对于一般的设计,好的模块划分如下图所示:
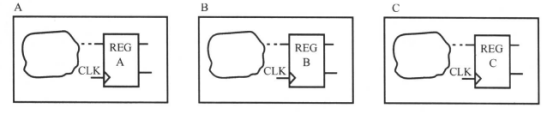
在这样的划分下,模块的输出边界是寄存器的输出端。由于组合电路之间没有边界,其输出连接到寄存器的数据输入端,我们可以充分利用综合工具对组合电路和时序电路的优化技术,得到最优的结果,同时也简化了设计的约束。图中每个模块除时钟端口外的所有输入端口延时是相同的,等于寄存器的时钟引脚CLK到输出引脚Q的延时。这使得时序约束更为方便,这一点在前面的时序路径约束中有说过。
上面是推荐的模块划分模式,下面就来说一下哪些是要避免的模块划分方式。
作模块划分时,应尽量避免使用胶合逻辑(Glue Logic),胶合逻辑如下图所示:
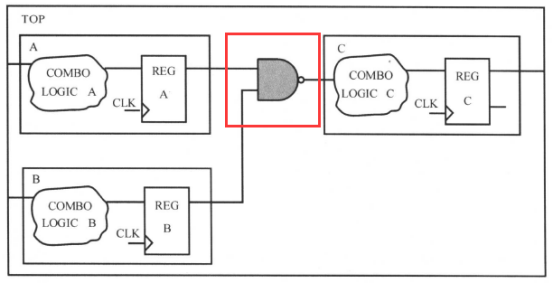
胶合逻辑是连接到模块的组合逻辑。图中,顶层的与非门(HAND gate)仅仅是个例化的单元,由于胶合逻辑不能被其他模块吸收,优化受到了限制。如果采用由底向上(bottom up)的策略,我们需要在顶层做额外的编译(compile)。避免使用胶合逻辑(Glue Logic)的划分如下所示:
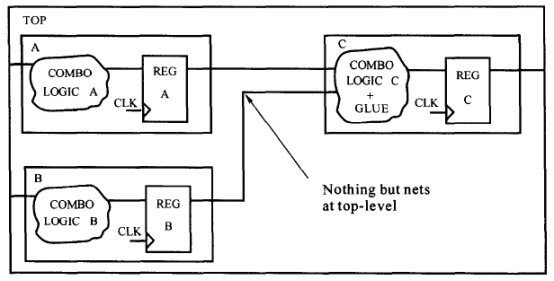
胶合逻辑可以和其他逻辑一起优化,顶层设计也只是结构化的网表。不需要再做编译。
·模块划分的修改
第一次的模块划分可能存在时序违规,可能需要重新划分模块,这里就来介绍一下模块划分的修改问题。我们知道,设计越大,计算机对设计作综合时所需要的资源越多,运行时间就越长。Design Compiler软件本身对设计的规模大小并没有限制。我们在对设计做编译时,需要考虑划分模块规模的大小应与现有的计算机中央处理器(CPU)和内存资源相匹配。尽量避免下面划分不当情况:
模块太小:由于人工划分的模块边界,使得优化受到限制,综合的结果可能不是最优的。
模块太大:做编辑所需的运行时间可能会太长,由于要求设计的周期短,我们不能等太久。
一般来说,根据现有的计算机资源和综合软件的运算速度,按我们所期望的周转时间(turnaround time),把模块划分的规模定为大约400 ~800K门。对设计作综合时,比较合理的运行时间为一个晚上。白天我们对电路进行设计和修改,写出编译的脚本。下班前,用脚本把设计输人到DC,对设计作综合优化,第二天早上回来检查结果。
作划分时,要把核心逻辑(Core Logic) 、 I/0 Pads、时钟产生电路、异步电路和JTAG(Joint Test Action Group)电路分开,把它们放到不同的模块里。顶层设计至少划分为3层的层次结构:顶层(Top-level)、中间层(Mid-level)、核心功能(Functional Core),如下图所示:
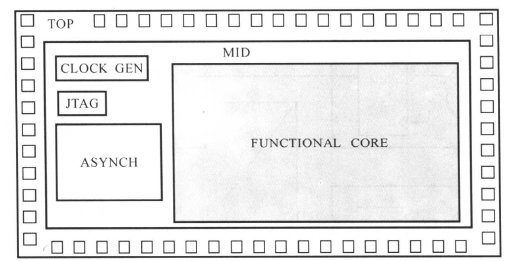
使用这种划分方式是因为:I/O pad单元与工艺相关、分频时钟产生电路是不可测试(Untestable)的、JTAG电路与工艺相关、异步电路的设计、约束和综合与同步电路不同,所以也放在与核心功能不同的模块里。
这里主要介绍同步电路的设计与综合。 为了使电路的综合结果最优化,综合的运行时间适中,我们需要对设计作合适的划分。如果现有的划分不能满足要求,我们要对划分进行修改。我们可以修改RTL原代码对划分作修改,也可以用DC的命令对划分作修改。下面介绍在DC里用命令修改划分。
DC以两种方法修改划分:自动修改划分和手动修改划分。
自动修改划分:
综合过程中DC需透明地修改划分。在DC中如使用命令:
compile -auto_ungroup area | delay (面积和延时之中选一个)
DC在综合时将自动取消(去掉)小的模块分区。取消模块分区由变量(前面也有提及到这些命令):
compile_auto_ungroup_delay_num_cells
compile_auto_ungroup_area_num_cells
来控制。两个变量的预设默认值分别为500和30。我们也可以用set命令把它们设置为我们希望的任何数值。我们可用report_auto_ungroup命令来报告编辑时取消了那些分区。如在DC中使用命令:
compile -ungroup_all
DC在综合时将自动取消所有的模块分区或层次结构。此时,设计将只有顶层一层的电路。该命令不能取消附加了dont_touch属性的模块分区。
手工修改划分:
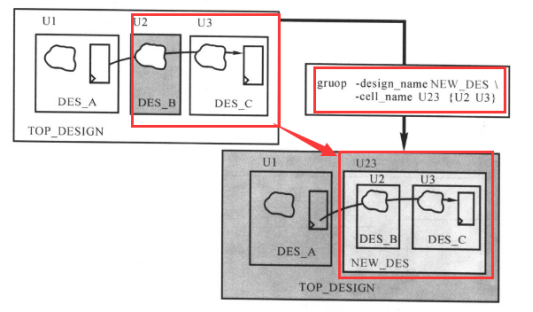
手动修改划分是指用户用命令指示所有的修改。使用“group”和“ungroup”命令修改设计里的划分,如下图所示:
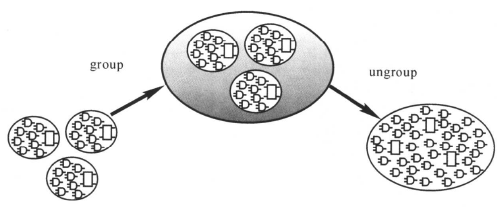
group命令产生新的层次模块,效果如下图所示:
ungroup命令取消一个或所有的模块分区,效果如下图所示:
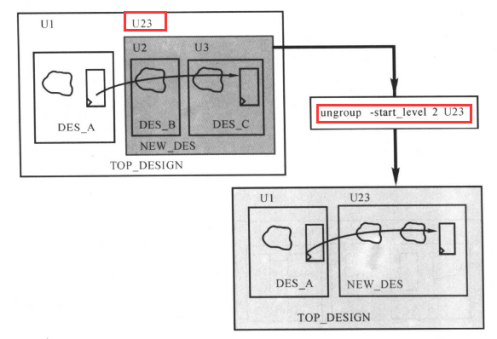
如要在当前设计中取消所有的层次结构,可以使用下面的命令:
ungroup -all -flatten
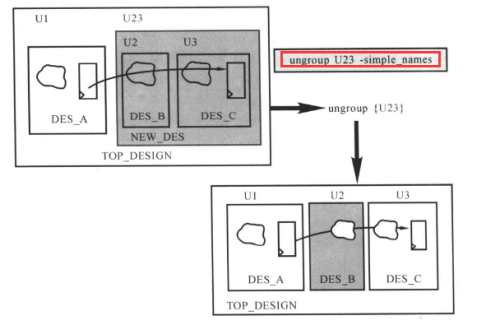
ungroup命令用选项“-simple_names”将得到原来的非层次的单元名U2 and U3
ungroup U23 -simple_names
得到的效果如下图所示:
最后,为了防止再次划分模块,这里总结一下模块划分的策略:
·不要通过层次边界分离组合电路。
·把寄存器的输出作为划分的边界。
·模块的规模大小适中,运行时间合理。
·把核心逻辑(Core Logic) ,Pads、时钟产生电路、异步电路和JTAG电路分开到不同的模块。
这样划分好处是:结果更好——设计小又快、简化综合过程——简化约束和脚本、编译速度更快一一更快周转时间(turnaround)。
下面是实战环节
3、实战
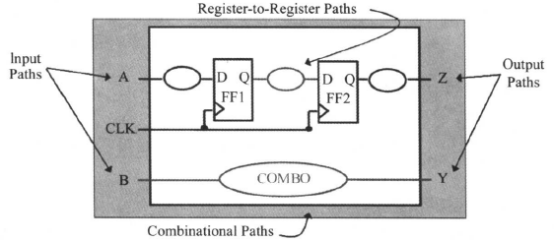
在本次实战里面,我们主要根据给出的原理图和综合规范,实践DC的综合优化技术,在拓扑模式下进行,因此还有可能涉及一些物理设计的内容,我们一步一步来进行吧。
设计原理图:

(顶层模块示意图:)
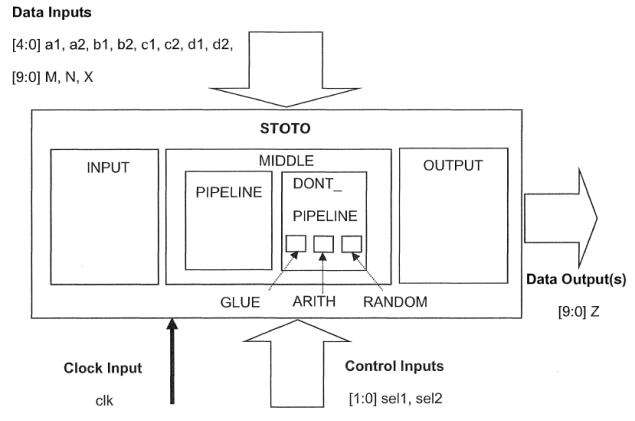
(子模块示意图一:)
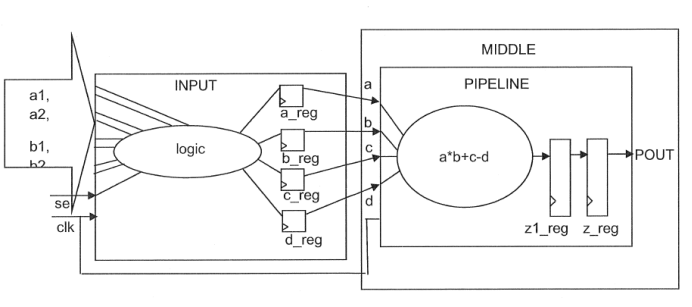
(子模块示意图二:)

(子模块示意图三:)
综合规范:
(可用资源说明:)

(设计和约束文件说明:)

(布局规划说明:)

(设计规范:)

首先我们来简单分析一下这个综合规范:
可用资源规范:也就是通过运行那个脚本来查看你的电脑有多少可用用来综合的核心,这里我们跳过,不用理他。
设计和约束文件说明:告诉我们设计的RTL文件和名字,以及告诉我们约束的位置和名字,RTL文件和名字以及时序环境等约束都我们不需要改。
布局规划说明:由于我们使用的是拓扑模式下的综合,这个布局规划提供给了我们物理的约束信息。
设计规范说明:其实这个是综合的规范说明,告诉你需要在综合过程中,要对哪些模块进行怎么样的处理,从而达到某种要求,这里面的10条规范我们后面在时间过程中都会介绍。
·设置.synopsys_dc.setup启动文件,配置DC的启动环境
(跟前面一样,不进行具体描述)
·进行编写设计约束文件,由于这里一方面没有给出时序和环境属性等方面设计规范,一方面给出了相关的设计约束文件,因此我们不需要进行撰写了,我来看一下吧:
时序和环境属性的约束:
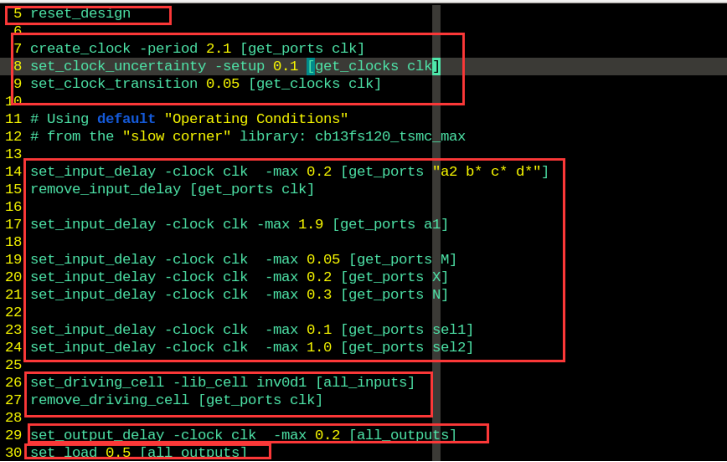
从上到下依次是:清除以前的约束、时钟的约束、输入端口延时的约束、输入端口环境属性的约束、输出端口延时约束、输出端口环境属性的约束。
布局规划中,包含的物理信息,对于了相应地物理约束,如下所示:

约束都给我们准备好了,我们就可以启动DC了
·启动DC,进行读入设计前的检查
(这里跟之前的章节一样,不再陈述)
·为formality创建文件,以便retiming转化可以捕捉到相应地文件,总之就是形式验证要用到,命令如下:
set_svf STOTO.svf
·读入设计和检查设计
(很前面的章节已经,这里不再陈述)
·执行时序约束,查看约束是否满足,同时执行非默认的物理约束:
source STOTO.con
check_timing
source STOTO.pcon
report_clock
·根据设计规范,应用不同的优化命令:
-->根据1和2,IO约束是保守值,能够更改,还有就是最终的设计要满足寄存器到寄存器之间的路径,因此,我们可以进行路径分组,并且更关注时钟那一组,也就是寄存器到寄存器那一组,优化的命令如下所示:
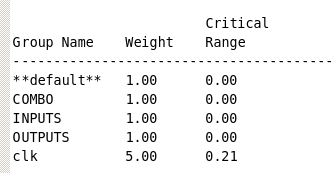
group_path -name clk -critical 0.21 -weight 5
group_path -name INPUTS -from [all_inputs]
group_path -name OUTPUTS -to [all_output]
group_path -name COMBO -from [all_inputs] -to [all_output]
然后我们可以查看时候进行了设置:
report_path_group,得到结果如下:
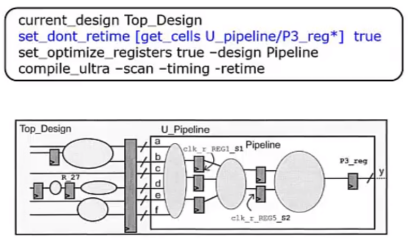
-->根据3,INPUT模块的结构需要保护;根据4,PIPELINE模块需要进行register_timing,也就是纯的流水线,因此也不能被打散,因此需要设置:
set_ungroup [get_designs "PIPELINE INPUT"] false
设置之后我们需要查看是否设置正确(设置正确会返回false )
get_attribute [get_designs "PIPELINE INPUT"] ungroup
如下图所示:

ungroup是取消层次的依次,设置为true就是要进行取消层次结构;因此我们要设置为false
-->根据6,I_DONT_PIPELINE模块的寄存器不能被流水线移动,根据前面的讲解,我们可以这样约束:
set_dont_retime [get_cells I_MIDDLE/I_DONT_PIPELINE] true
然后检查是不是约束成功,或者约束对了:
get_attribute [get_cells I_MIDDLE/I_DONT_PIPELINE] dont_retime
如下图所示,返回应为true:

-->根据要求4,需要进行pipelined,于是我们可以启用register_timing,约束如下所示:
set_optimize_registers true -design PIPELINE
-->根据要求5,虽然PIPELINE进行了pipelined,也就是进行了寄存器retiming,但是输出寄存器不能动,也就是保持原来的寄存器,因此需要约束:
set_dont_retime [get_cells I_MIDDLE/I_PIPELINE/z_reg*] true
然后检查一下是否正确:

-->保存在综合之前保存一下我们的设计:
write -f ddc -hier -out unmapped/STOTO.ddc
·进行综合:
根据要求8:设计是时序关键的,因此我们要在综合的时候加上-timing选项;根据要求10:要执行扫描插入,因此要加上-scan选项,看预加上扫描链综合后是否有违规;根据要求7、9以及前面的要求,我们可以加上-retiming选项优化进行寄存器、组合逻辑等的优化;综合使用的命令如下所示:
compile_ultra -scan -timing -retime
·综合后检查与处理:
-->综合完成之后,我们可以查查看我们用了哪些特性(这一步可以忽略):

(这些特性都是大把大把地烧钱啊)
-->查看哪些模块是否被打散,即验证与约束的是否一致:
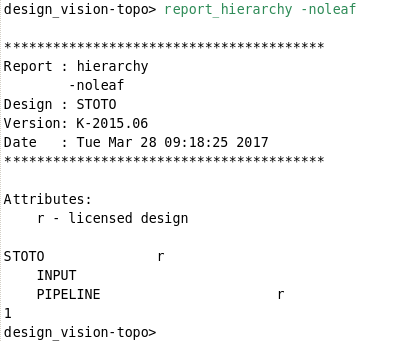
可以知道:MIDDLE, OUTPUT, DONT_PIPELINE, GLUE, ARITH and RANDOM这些模块都被打散了; 没有被打散的,也就是保存了模块结构的只有下面的这三个设计:STOTO, PIPELINE, INPUT
我们从GUI中也可以看到:
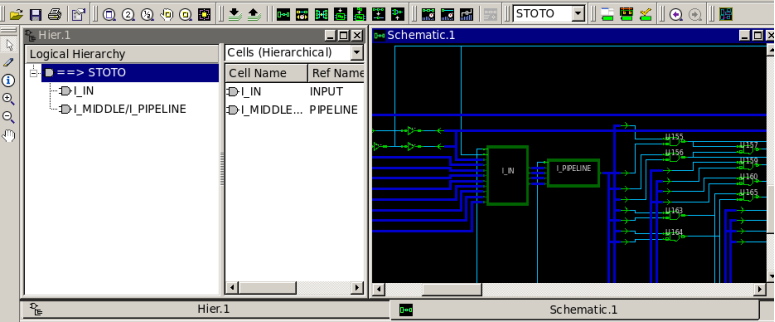
只有顶层设计STOTO和子模块PIPELINE, INPUT的边框被保存下来了,其他的都被打散了,也就是找不到模块的边界了。
-->查看是否有约束违规:
这里我们通过重定义的形式,把生成的时序报告保存到文件中:
redirect -tee -file rc_compile_ultra.rpt {report_constraint -all}
(本实验中,有时序违规)
-->查看时序报告:
redirect -tee -file rt_compile_ultra.rpt {report_timing}
下面我们就来看看这个这个时序报告的一部分吧:


从上面的报告我们可以知道,虽然一些模块被打散了,但是模块的例化明还在,我们可以通过例化名来找到原件所在的模块,方便我们查看延时不合理时提供定位;这也就是模块例化名字唯一化的一个好处。
-->保存设计:
write -f ddc -hier -out mapped/STOTO.ddc
综合完成了,此外我们为formality进行停止记录数据(总之就是形式验证要做得事):
set_svf -off
·查看寄存器是否被移动等操作,也就是查看优化技术的结果细节(有兴趣的可以仔细看下,深入了解)
前面我们进行了各种retiming、pipeline的优化,有一些寄存器被移动了,有些组合逻辑被分割了,我们现在就来看看那些被移动,一方面是纯粹的查看进行了解一些优化技术,另一方面是看看是否存在约束与预期不符合的情况。
-->查看在PIPELINE设计中被register retiming技术移动过的寄存器 :
get_cells -hier *r_REG*_S
通过返回值(即返回寄存器的名字)的路径,我们可以知道PIPELINE中的流水线寄存器被移动过了:

(retiming中被移动过的流水线寄存器的名字以 clkname_r_REG*_S*结束,*是通配符),再结合我们我们的原理图,我们可以知道,是z1_reg被移动了(一位后缀名是z1跟s1):

-->我们还可以查看例化的名字原来的模块名字,如下所示:
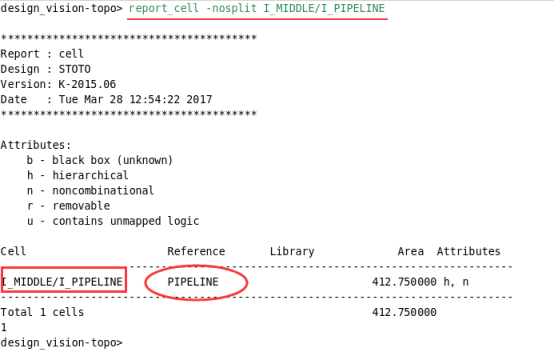
查看原来的I_IN模块:
report_cell -nosplit I_IN:

-->在第1点中我们说只是通过名字中的1来说移动的是z1_reg,这显然是不够充分,可以通过下面来验证z_reg是否被移动过:
get_cells -hier *z_reg*
有返回值,说明这个寄存器存在,没有被移动过(移动过之后就被换了例化名字):

然后我们来查看一下z1_reg,可以看到找不到对象,说明被移动了:

-->查看其它的被retiming移动都的触发器(retiming中,被移动过的却不是流水线中的寄存器的被命名为R_* ):

上面是INPUT模块中被retiming移动的寄存器,我们可以查看该模块是否有不被移动的寄存器:
get_cells I_IN/*_reg*
有返回值,说明是存在有不被移动的寄存器的。
-->通过下面的命令:
report_timing -from I_MIDDLE/I_PIPELINE/z_reg*/*
可以知道PIPELINE模块是寄存输出的(因为有返回报告值)
优化的实战部分都这里就结束了,最后,DC的优化命令有很多,不懂的可以通过man命令查看。最后感叹一下,总共码了一万两千多子,加上一堆图,这应该是本系列最长的一篇博文吧。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号