
*解析网页数据的仓库
用Beatifulsoup基于lxml包lxml包基于html和xml的标记语言的解析包。可以去解析网页的内容,把我们想要的提取出来。
第一步、导入两个包,项目中必须包含beautifulsoup4和lxml
第二步、先去获取网页的数据
第二步、先去获取网页的数据
def get_html():
url="http://www.scetc.net"
response=request.get(url)
response.encoding="UTF-8"
return response.text
第三步、导入Beautifulsoup对象
from bs4 import BeautifulSoup
from bs4 import BeautifulSoup
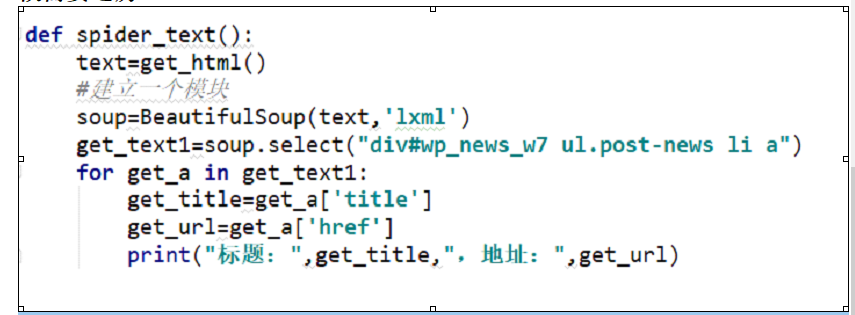
第四步、解析网页内容
解析的方式文本格式就是 :
标记#id或者.class,如果有层次标记则空格 在后面加标记就可以了。
请注意一点就是select方法返回的肯定是列表,所以获取数据的时候需要遍历
解析的方式文本格式就是 :
标记#id或者.class,如果有层次标记则空格 在后面加标记就可以了。
请注意一点就是select方法返回的肯定是列表,所以获取数据的时候需要遍历
*下载网上的其他资源
案例就是下载图片资源:res = requests.get(url+stu_id+".jpg", stream=True)
file=open(stu_id+".jpg",'wb')
for chunk in res.iter_content(chunk_size=32):
file.write(chunk)
file.close()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号