【数据采集】第五次实验
1. 实验一
1.1 题目
熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架爬取京东商城某类商品信息及图片。
候选网站:http://www.jd.com
1.2 思路
1.2.1 发送请求
- 引入驱动配置
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
self.driver = webdriver.Chrome(chrome_options=chrome_options)
- 启动驱动发起访问
url = "http://www.jd.com"
spider = MySpider()
while True:
print("1.爬取")
print("2.显示")
print("3.退出")
s = input("请选择(1,2,3):")
if s == "1":
spider.executeSpider(url, "手机")
continue
elif s == "2":
spider.showDB()
continue
elif s == "3":
break
1.2.2 获取页面信息
- 普通数据抓取
lis =self.driver.find_elements_by_xpath("//div[@id='J_goodsList']//li[@class='gl-item']")
for li in lis:
try:
src1 = li.find_element_by_xpath(".//div[@class='p-img']//a//img").get_attribute("src")
except:
src1 = ""
try:
src2 = li.find_element_by_xpath(".//div[@class='p-img']//a//img").get_attribute("data-lazy-img")
except:
src2 = ""
try:
price = li.find_element_by_xpath(".//div[@class='p-price']//i").text
except:
price = "0"
try:
note = li.find_element_by_xpath(".//div[@class='p-name p-name-type-2']//em").text
mark = note.split(" ")[0]
mark = mark.replace("爱心东东\n", "")
mark = mark.replace(",", "")
note = note.replace("爱心东东\n", "")
note = note.replace(",", "")
except:
note = ""
mark = ""
- 图片链接获取并保存
if src1:
src1 = urllib.request.urljoin(self.driver.current_url, src1)
p = src1.rfind(".")
mFile = no + src1[p:]
elif src2:
src2 = urllib.request.urljoin(self.driver.current_url, src2)
p = src2.rfind(".")
mFile = no + src2[p:]
if src1 or src2:
T = threading.Thread(target=self.download, args=(src1, src2, mFile))
T.setDaemon(False)
T.start()
self.threads.append(T)
else:
mFile = ""
1.2.3 保存数据
- 保存在数据库中
- 建表
try:
self.conn = sqlite3.connect("phones.db")
self.cursor = self.conn.cursor()
try:
# 如果有表就删除
self.cursor.execute("drop table phones")
except Exception as err:
print(err)
try:
# 建立新的表
sql = "create table phones (mNo varchar(32) primary key, mMark varchar(256),mPrice varchar(32),mNote varchar(1024),mFile varchar(256))"
self.cursor.execute(sql)
except:
pass
except Exception as err:
print(err)
- 插入数据
def insertDB(self, mNo, mMark, mPrice, mNote, mFile):
try:
sql = "insert into phones (mNo,mMark,mPrice,mNote,mFile) values (?,?,?,?,?)"
self.cursor.execute(sql, (mNo, mMark, mPrice, mNote, mFile))
except Exception as err:
print(err)
- 保存图片
- 创建文件夹
try:
if not os.path.exists(MySpider.imagePath):
os.mkdir(MySpider.imagePath)
images = os.listdir(MySpider.imagePath)
for img in images:
s = os.path.join(MySpider.imagePath, img)
os.remove(s)
except Exception as err:
print(err)
- 保存

2. 实验二
2.1 题目
熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待
HTML元素等内容。
使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、教学
进度、课程状态,课程图片地址),同时存储图片到本地项目根目录下的imgs文件夹
中,图片的名称用课程名来存储
2.2 思路
2.2.1 驱动启动
- 引入驱动
chrome_path = r"D:\Download\Dirver\chromedriver_win32\chromedriver_win32\chromedriver.exe" # 驱动的路径
browser = webdriver.Chrome(executable_path=chrome_path)
- 发送请求
browser.get('https://www.icourse163.org/')
browser.implicitly_wait(5)
- 窗口最大化
browser.maximize_window()
- 扫码登录,也可以获取input框输入,但如果爬取次数太多的话,会有两次的验证码。
browser.find_element_by_xpath('//*[@id="j-topnav"]/div/a').click()
time.sleep(5)
2.2.2 获取信息
- 跳转个人中心页面
注意:一定要登录之后才能跳转,不然此时浏览器是没有用户信息的,就会没有你学了多久这个数据
browser.implicitly_wait(10)
browser.get('https://www.icourse163.org/home.htm?userId=1401537859#/home/course')
browser.implicitly_wait(10)
- 滑到底部
browser.execute_script("window.scrollTo(0, document.body.scrollHeight);")
- 节点获取
cCourse = browser.find_elements_by_xpath(
'//*[@id="j-coursewrap"]/div/div[1]/div/div[1]/a/div[2]/div[1]/div[1]/div/span[2]')
cCollege = browser.find_elements_by_xpath('//*[@id="j-coursewrap"]/div/div[1]/div/div[1]/a/div[2]/div[1]/div[2]/a')
cSchedule = browser.find_elements_by_xpath(
'//*[@id="j-coursewrap"]/div/div[1]/div/div[1]/a/div[2]/div[2]/div[1]/div[1]/div[1]/a/span')
cImgUrl = browser.find_elements_by_xpath(
'//*[@id="j-coursewrap"]/div/div[1]/div/div[1]/a/div[1]/img')
cCourseStatus = browser.find_elements_by_xpath(
'//*[@id="j-coursewrap"]/div/div[1]/div/div[1]/a/div[2]/div[2]/div[2]')
2.2.3 数据存储
- 下载图片函数
def download(name,img):
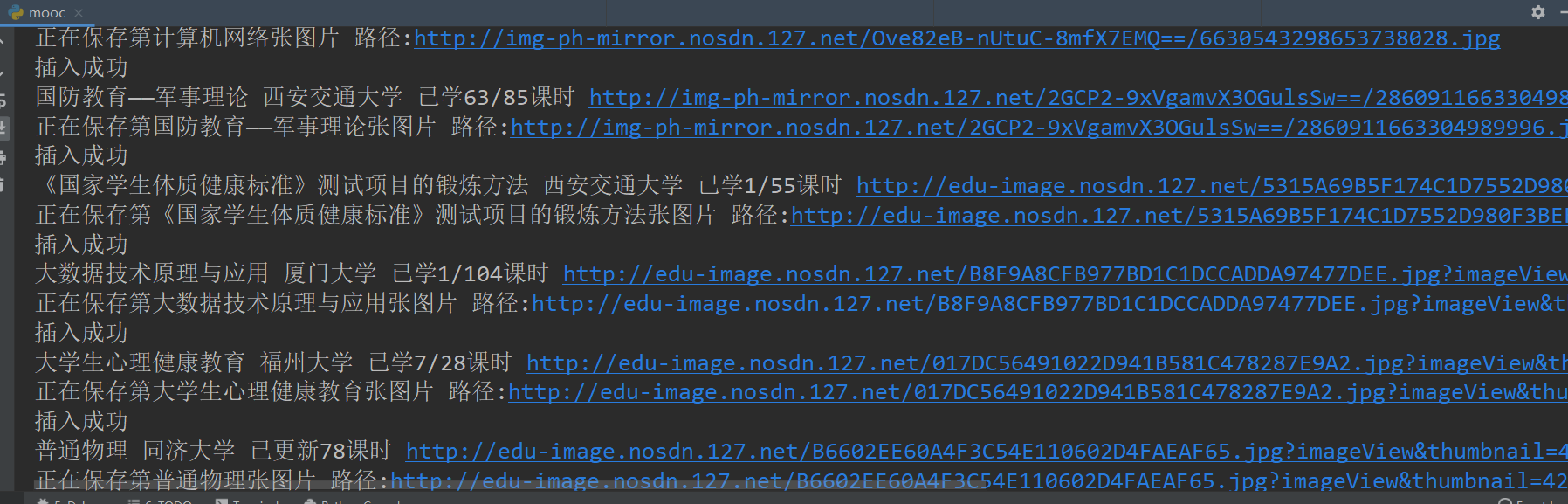
print(f"正在保存第{name}张图片 路径:{img}")
resp = requests.get(img)
with open(f'./imgs/{name}.jpg', 'wb') as f: # 保存到这个image路径下
f.write(resp.content)
- 数据库对象,包括链接数据库与插入数据
class database():
def __init__(self):
self.HOSTNAME = '127.0.0.1'
self.PORT = '3306'
self.DATABASE = 'scrapy_homeword'
self.USERNAME = 'root'
self.PASSWORD = 'root'
# 打开数据库连接
self.conn = pymysql.connect(host=self.HOSTNAME, user=self.USERNAME, password=self.PASSWORD,
database=self.DATABASE, charset='utf8')
# 使用 cursor() 方法创建一个游标对象 cursor
self.cursor = self.conn.cursor()
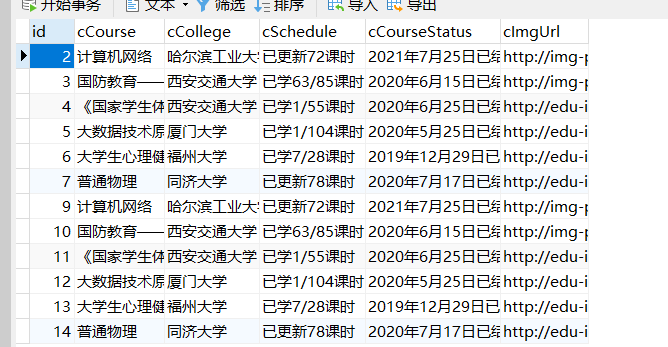
def insertData(self, lt):
sql = "INSERT INTO mooc(cCourse,cCollege , cSchedule , cCourseStatus ,cImgUrl) " \
"VALUES ( %s, %s, %s, %s,%s)"
try:
self.conn.commit()
self.cursor.execute(sql, lt)
print("插入成功")
except Exception as err:
print("插入失败", err)
- 控制台打印
for Course, College, Schedule, ImgUrl, CourseStatus in zip(cCourse, cCollege, cSchedule, cImgUrl, cCourseStatus):
print(Course.text, College.text, Schedule.text, ImgUrl.get_attribute("src"), CourseStatus.text)
download(Course.text,ImgUrl.get_attribute("src"))
db.insertData([Course.text, College.text, Schedule.text, CourseStatus.text, ImgUrl.get_attribute("src")])

实验三:
3.1 题目
完成Flume日志采集实验,包含以下步骤:
任务一:开通MapReduce服务
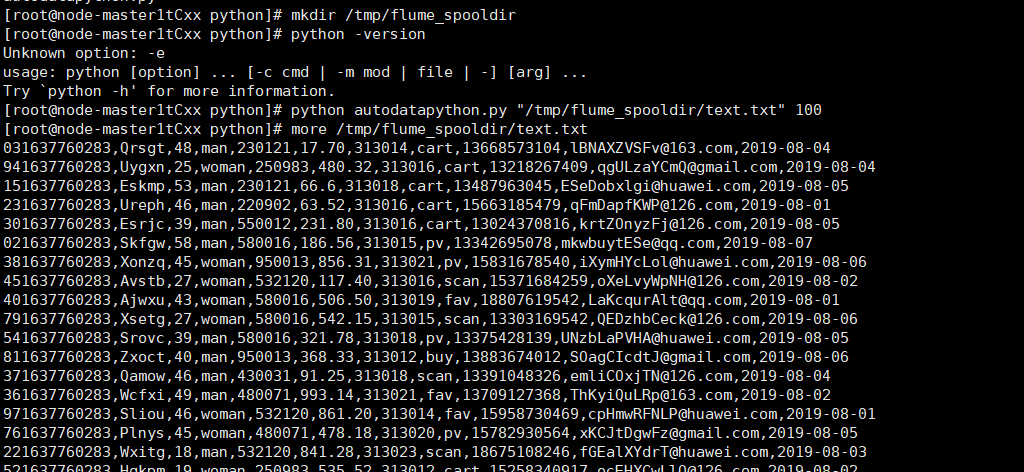
任务二:Python脚本生成测试数据
任务三:配置Kafka
任务四:安装Flume客户端
任务五:配置Flume采集数据
3.2 思路
- 执行Python命令,测试生成100条数据
- kafka 替换实际Zookeeper的IP


- 解压 MRS_Flume_ClientConfig.tar 文件

- 安装客户端运行环境到新的目录
/opt/Flumeenv。安装时自动生成目录。查看安装输出信息,如有Components client installation is complete表示客户端运行环境安装成功

- 安装Flume到新目录
/opt/FlumeClient,安装时自动生成目录,出现install flume client successfully表示成功了

- 重启Flume服务

安装结束!
- 修改Flume配置文件

其中client.sinks.sh1.kafka.topic的值为kafka中创建的topic的值;client.sinks.sh1.kafka.bootstrap.servers的值为Kafka实例Broker的IP和端口。
改完配置文件要用source命令使其生效!
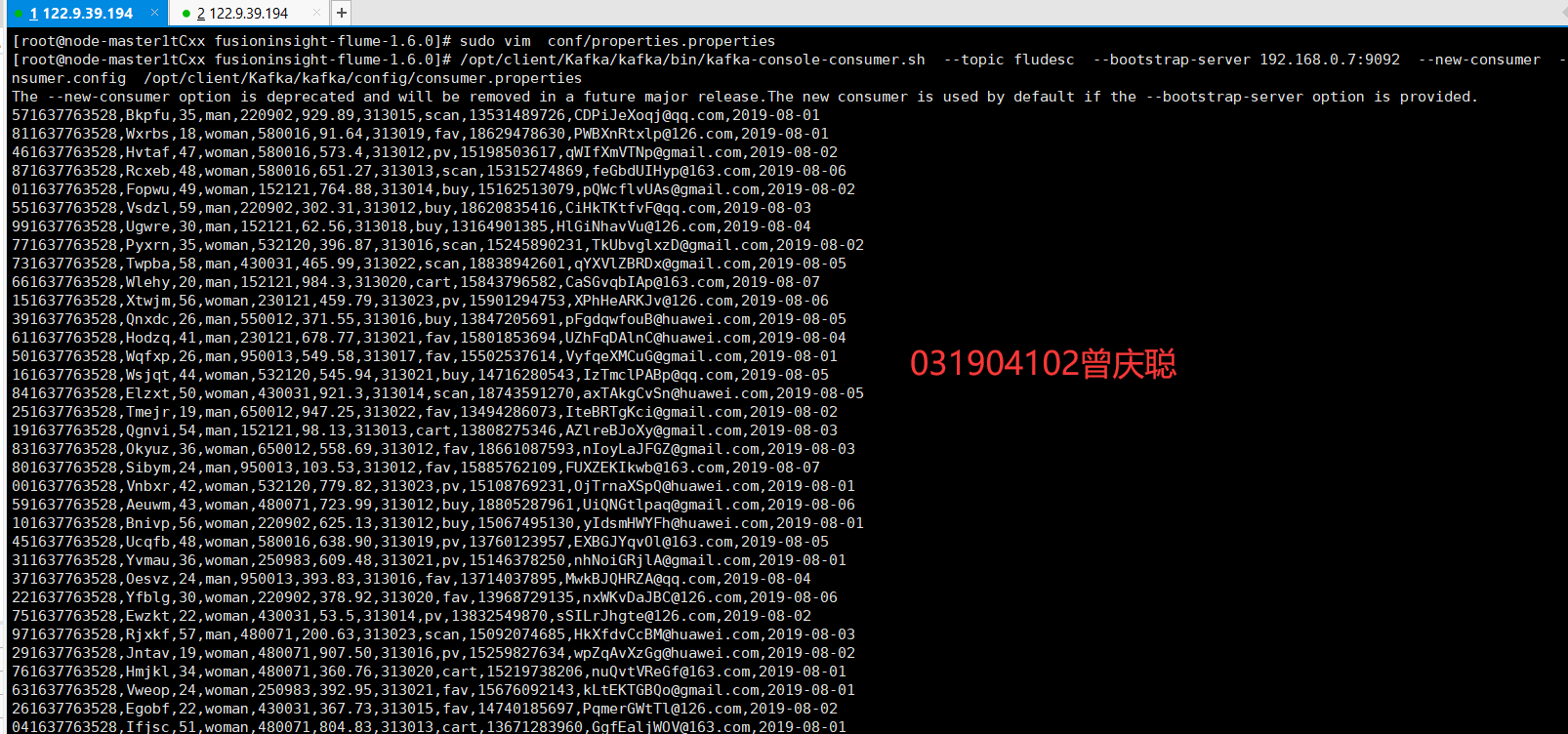
- Python脚本命令,再生成一份数据,查看Kafka中是否有数据产生
可以看到,已经消费出数据了
代码地址
https://gitee.com/cocainecong/spider-experiment/tree/master/实验5
心得
- 熟悉了selenium的命令操作,包括浏览器用户登录
- 熟悉xpath语法
- 学习了Flume进行数据采集的操作流程

 浙公网安备 33010602011771号
浙公网安备 33010602011771号