
Python分布式爬虫-elasticsearch搭建搜索引擎
一、elasticsearch使用
1、elasticsearch介绍
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便
我们希望建立一个网站或应用程序,并要添加搜索功能,但是想要完成搜索工作的创建是非常困难的:
我们希望搜索解决方案要运行速度快;
我们希望能有一个零配置和一个完全免费的搜索模式;
我们希望能够简单地使用JSON通过HTTP来索引数据;
我们希望我们的搜索服务器始终可用;
我们希望能够从一台开始并扩展到数百台;
我们要实时搜索,我们要简单的多租户;
我们希望建立一个云的解决方案。
因此我们利用Elasticsearch来解决所有这些问题及可能出现的更多其它问题
内部功能:
分词 搜索结果打分 解析搜索要求
全文搜索引擎:solr sphinx
很多大公司都用elasticsearch
elasticsearch对Lucene进行了封装,既能存储数据,又能分析数据,适合与做搜索引擎
2、elasticsearch安装与配置
1)elasticsearch依赖于java,需安装java SDK 依赖
2)elasticsearch的安装可以从官网下载,但不建议使用官网的版本,原因是该版本提供原始的插件不多。本项目使用的是elasticsearc-rtf,由国内的某大神组装整合,安装很多插件,比官方版好使用。GitHub(下载中文版):https://github.com/medcl/elasticsearch-rtf
3)运行elasticsearch的方法:在bin文件目录下进入终端,执行命令:elasticsearch.bat
成功运行:

浏览器输入:127.0.0.1:9200 ,经格式化处理,返回结果:
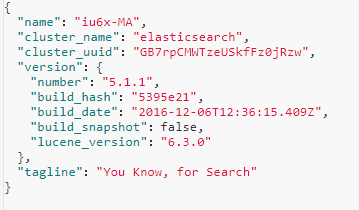
配置文件:conf/elasticsearch.yml
3、elasticsearch两个重要插件:head和kibana的安装
3.1、ealsticsearch-head安装
ealsticsearch只是后端提供各种api,要直观的使用它,就需要使用到elasticsearch-head,elasticsearch-head是一款专门针对于elasticsearch的客户端工具
elasticsearch-head配置包,下载地址:https://github.com/mobz/elasticsearch-head
elasticsearch-head是一个基于node.js的前端工程,使用它之前,我们需确定已安装node、npm,具体安装可参看:https://www.cnblogs.com/Eric15/articles/9517232.html
elasticsearch-head使用(这里针对的是elasticsearch 5.x以上的版本):
- 进入elasticsearch-head的文件夹,如:D:\xwj_github\elasticsearch-head
- 执行: npm install / cnpm install 。 npm install速度会很慢,建议使用cnpm淘宝镜像的方式安装:cnpm install(如没有cnpm命令,需安装:npm install -g cnpm --registry=https://registry.npm.taobao.org)
- 执行: npm run start / cnpm run start (以后进来可以直接运行这一行代码)
在浏览器访问http://localhost:9100,可看到如下界面,表示启动成功:

在浏览器打开127.0.0.1:9100 ,结果显示:

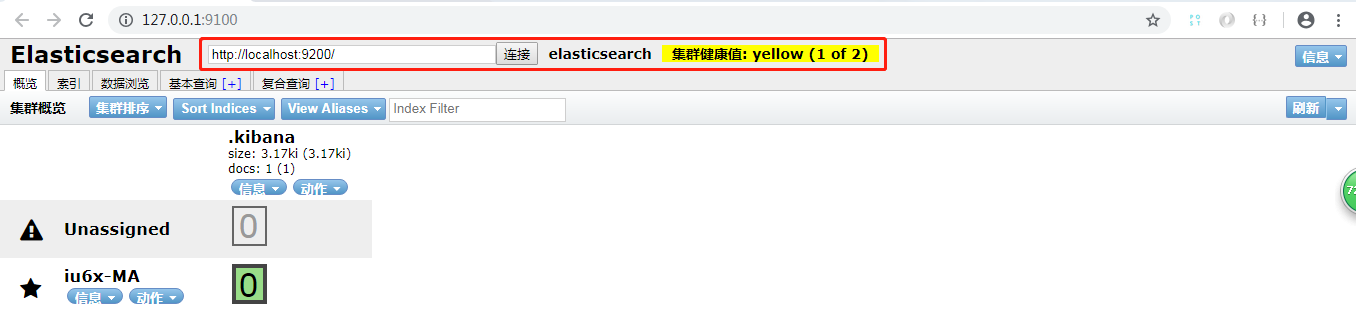
注意:为了让ealsticsearch-head前端页面连上ealsticsearch后台,即可以直接通过127.0.0.1:9100页面连接127.0.0.1:9200,需要对ealsticsearch的配置文件做些配置:ealsticsearch.yml
http.cors.enabled: true # 跨域配置 http.cors.allow-origin: "*" # 允许all连接 http.cors.allow-methods: OPTIONS, HEAD, GET, POST, PUT, DELETE # 请求方法 http.cors.allow-headers: "X-Requested-With, Content-Type. Content-Length, X-User" #user-agent
保存后,重新运行ealsticsearch.bat,在127.0.0.1:9100页面中重新连接127.0.0.1:9200 , 此时效果:
3.2、kibana使用
kibana安装很简单,直接在网上搜索就可以找到资源。
在安装成功后,进入bin目录 ,执行命令:kibana.bat
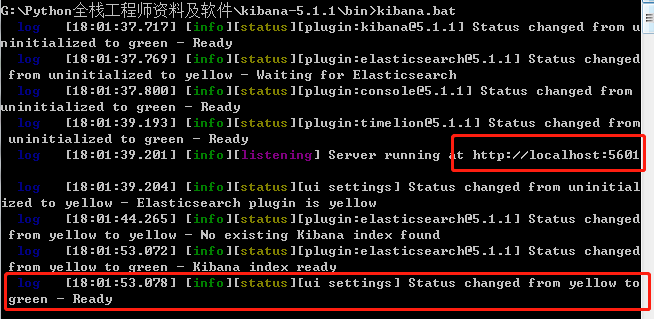
在浏览器中打开:127.0.0.1:5601 ,如显示如下页面,表示安装成功:
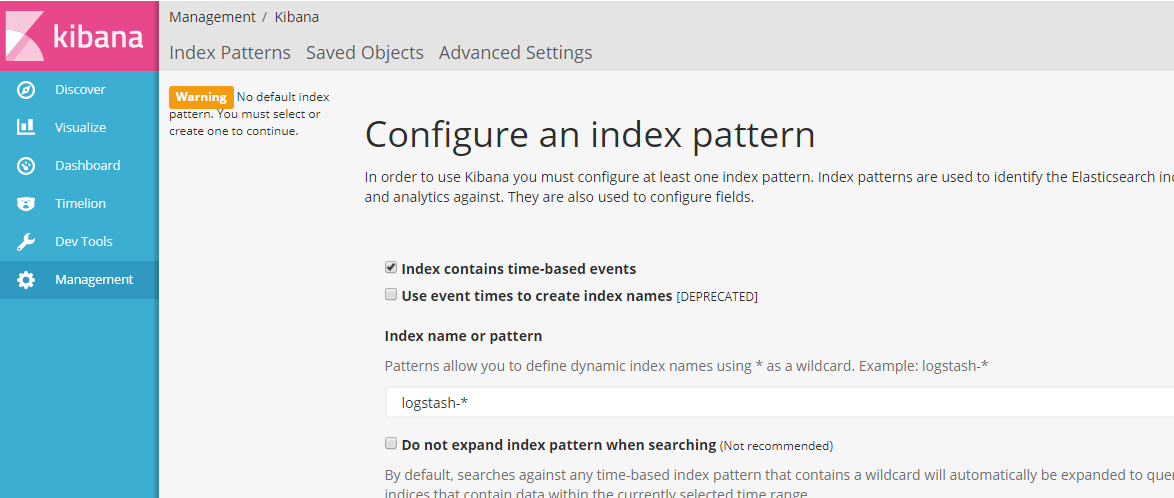
4、elasticsearch的基本概念
- 集群:一个或多个节点组织在一起
- 节点:一个集群中的一台服务器
- 分片:索引划分为多份的能力,允许水平分割,扩展容量,多个分片响应请求
- 副本:分片的一份或多分,一个节点失败,其他节点顶上
| index 类比→ | 数据库 |
| type 类比→ | 表 |
| document 类比→ | 行 |
| fields 类比→ | 列 |
http方法:
http1.0定义了三种请求方法:GET 、 POST 、 HEAD方法
http1.1后,新增五种方法:
OPTIONS 、 PUT 、 DELETE 、 TRACE 、 CONNECT
5、倒序索引

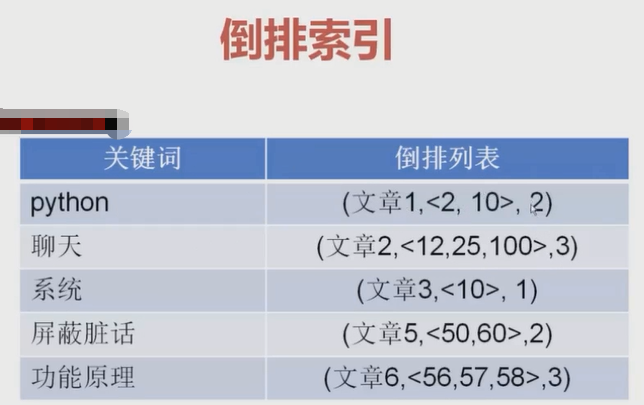

上述问题elasticsearch已经解决,只需了解。
6、 elasticsearch 基本的索引和文档CRUD操作
elasticsearch在kibana的基本操作
1)索引操作/index
PUT lagou # 更新/新增操作,增加lagou索引 { "settings":{ "index":{ "number_of_shards":5, # 5个切片。一旦生成不能更改 "number_of_replicas":1 # 1个副本,可以更改 } } }
# GET方法 GET lagou/_settings # 获取lagou索引下的settings数据 GET _all/settings # 获取所有索引下的settings数据 GET .kibana,lagou/_settings # 获取kibana、lagou索引下的settings数据
2)保存文档/type
PUT lagou/job/1 # 修改/新增lagou索引下job的第1个文档数据(第1行数据),如果job后面的数字1不提供,则会自动生成一个随机uuid当作文档id { "title":"python分布式爬虫开发", "salary_min":15000, "city":"北京", "company":{ "name":"百度", "company_addr":"北京市软件园", }, "publish_date":"2018-11-11", "comments":15 }
# GET GET lagou/job/1 # 获取id为1的数据文档 GET lagou/job/1?_source=title # 获取id为1的数据文档的title GET lagou/job/1?_source=title,city # 获取id为1的数据文档的title、ciity GET lagou/job/1?_source # 获取id为1的数据文档下source的所有数据
# POST 修改数据 ,需注意的是PUT修改单个数据是完全覆盖,POST修改数据是以更新的形式,不会破坏其他未修改数据 POST lagou/job/1/_update { "doc":{ "comments":20 # 如果使用PUt方法,则其他未指明的数据均会被覆盖清除,只保留comments数据 } }
# DELETE 删除 DELETE lagou/job/1 # 删除id为1的文档数据 # DELETE lagou/job # kibana中已经取消了这种删除方式 DELETE lagou # 删除lagou索引
3)elasticsearch的mget和bulk批量操作
3.1)mget批量操作
在HTTP请求连接时,都会经历三次握手的过程,如果每查询一个数据都需要经过这过程,浪费时间也浪费开销,于是一次性批量查询数据的方法就出现了。
假设 testdb(index )索引下的job1、job2(type ),两张表下分别有id为1(第一行数据)、id为2(第2行数据)的文档数据,即:testdb/job1/1 、 testdb/job2/2
问题:查询index为testdb下的job1表的id为1和job2表的id为2的数据。 --使用mget方法
# 情景1 GET _mget { "docs":[ { "_index":"testdb", "_type":"job1", "_id":1 }, { "_index":"testdb", "_type":"job2", "_id":2 } ] } # 情景2,指定index(testdb)相同,在doc中就不用指定 GET testdb/_mget{ "docs":[ { "_type":"job1", "_id":1 }, { "_type":"job2", "_id":2 } ] } # 情景三,指定index(testdb)、job1相同,在doc中便不用指定 GET testdb/job1/_megt { "docs":[ { "_id":1 }, { "_id":2 } ] } # 情景三 简写 GET testdb/job1/_megt { "ids":[1,2] }
3.2)bulk批量处理
bulk批量处理:可以合并多个操作,比如多个index,delete,update,create等等,包括从一个索引到另一个索引:
- action_and_meta_data\n
- option_source\n
- …
- action_and_meta_data\n
- option_source\n
- ...
- action_and_meta_data\n
- option_source\n
每个操作都是由两行构成,除了delete除外,由元信息行和数据行组成
注意数据不能美化,即只能是两行的形式,而不能是经过解析的标准的json排列形式,否则会报错
注意:delete操作时,只有一行,即元信息行,这点需要注意:

两行的形式,无论数据行多少数据都必须放成一行的形式,不能多行放置或用json美化的排列形式:

POST _bulk # 请求类型,及操作类型需指明 {"index":...} # 元信息行, {"field":...} # 数据操作行
7、elasticsearch的mapping映射管理
elasticserach的mapping映射:创建索引时,可以预先定义字段的类型以及相关属性,每个字段定义一种类型,属性比mysql里面丰富,前面没有传入,因为elasticsearch会根据json源数据来猜测是什么基础类型。M挨批评就是我们自己定义的字段的数据类型,同时告诉elasticsearch如何索引数据以及是否可以被搜索。
作用:会让索引建立的更加细致和完善,对于大多数是不需要我们自己定义
内置类型:
- String类型: 两种text keyword。text会对内部的内容进行分析,索引,进行倒排索引等,为设置为keyword则会当成字符串,不会被分析,只能完全匹配才能找到String。 在es5已经被废弃了
- 日期类型:date 以及datetime等
- 数据类型:integer long double等等
- bool类型
- binary类型
- 复杂类型:object nested
- geo类型:geo-point地理位置
- 专业类型:ip competition
- object :json里面内置的还有下层{}的对象
- nested:数组形式的数据

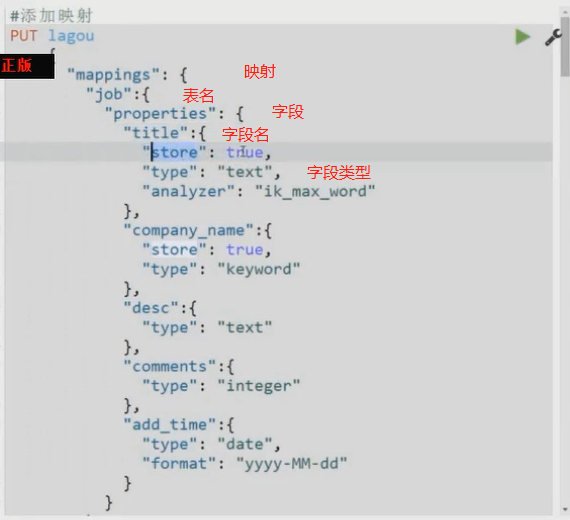

关于映射管理,类似于数据库中对于字段类型的设置。通过生成表的形式,给每个字段设定字段类型,再通过插入相应数据等。具体用法可百度
8、 elasticsearch的简单查询
大概分为三类:
- 基本查询:
- 组合查询:
- 过滤:查询同时,通过filter条件在不影响打分的情况下筛选数据
1)match查询:
match后面为关键词,如下面demo->关于python的都会被提取出来。match查询会对内容进行分词,并且会自动对传入的关键词进行大小写转换,内置ik分词器会进行切分,如python网站,只要搜到存在的任何一部分,
都会返回该相关数据
GET lagou/job/_search { "query":{ "match":{ "title":"python" } } }
2)term查询
区别,对传入的值不会做任何处理,就像keyword,只能查询完全匹配的类型,一部分匹配是不成功的
3)terms查询
term的批量查询操作,可以传入多个值。只要有任一个词完全匹配,就会返回结果
注:控制查询的返回数量,如:一页n个数据,翻到下一页再返回n个数据,即分页显示数据:
GET lagou/_serach { "query":{ "match":{ # match查询 "title":"python" # 匹配关键词:python } }, "form":1, # 从第一个数据开始显示,也可以从第0个数据开始显示 "size":2 # 一页两个数据 }
4)match_all
匹配所有数据,返回所有数据
GET lagou/_search # 返回lagou索引下的所有数据 { "query":{ "match_all":{} } }
。。。
9、将爬取的数据保存至elasticsearch
1)从GitHub上下载 elasticsearch-dsl-py,并安装:pip install elasticsearch-dsl-py
2)新建py文件:es_types.py
elasticsearch的字段类型定义,及数据保存,与django中的ORM相似,可以往models方面理解
from datetime import datetime from elasticsearch_dsl import DocType, Date, Nested, Boolean, \ analyzer, InnerObjectWrapper, Completion, Keyword, Text, Integer from elasticsearch_dsl.analysis import CustomAnalyzer as _CustomAnalyzer from elasticsearch_dsl.connections import connections connections.create_connection(hosts=["localhost"]) # 连接es class ArticleType(DocType): #伯乐在线文章类型 suggest = Completion(analyzer=ik_analyzer) # title = Text(analyzer="ik_max_word") create_date = Date() url = Keyword() url_object_id = Keyword() front_image_url = Keyword() front_image_path = Keyword() praise_nums = Integer() comment_nums = Integer() fav_nums = Integer() tags = Text(analyzer="ik_max_word") content = Text(analyzer="ik_max_word") class Meta: index = "jobbole" # es中的index索引 doc_type = "article" # es中的type -表
3)在item中,将爬取到的数据赋值到es字段中
from w3lib.html import remove_tags from models.es_types import ArticleType def save_to_es(self): article = ArticleType() article.title = self['title'] article.create_date = self["create_date"] article.content = remove_tags(self["content"]) article.front_image_url = self["front_image_url"] if "front_image_path" in self: article.front_image_path = self["front_image_path"] article.praise_nums = self["praise_nums"] article.fav_nums = self["fav_nums"] article.comment_nums = self["comment_nums"] article.url = self["url"] article.tags = self["tags"] article.meta.id = self["url_object_id"] article.suggest = gen_suggests(ArticleType._doc_type.index, ((article.title,10),(article.tags, 7))) # article.save() redis_cli.incr("jobbole_count") # return
4)在pipelines.py中,执行save_to_es函数:
class ElasticsearchPipeline(object): #将数据写入到es中 def process_item(self, item, spider): #将item转换为es的数据 item.save_to_es() return item
5)settings.py中设置:item_pipelines
ITEM_PIPELINES = { # 'ArticleSpider.pipelines.JsonExporterPipleline': 2, 'ArticleSpider.pipelines.ElasticsearchPipeline': 1 }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号