
Python分布式爬虫打造搜索引擎-scrapy爬取知名技术文章网站
一、项目基础环境
- python3.6.0
- pycharm2018.2
- mysql+navicat
二、scrapy爬取知名技术文章网站
1、使用虚拟环境 ,创建虚拟环境:
mkvirtualenv --python=C:\python3.6\python.exe articlespider #python3.6版本
2、进入articlespider目录,安装scrapy:
pip install -i https://pypi.douban.com/simple/ scrapy #豆瓣源安装速度快
安装时报错:


需要手动下载安装Twisted:https://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
放到 articlespider目录下 ,安装:
pip install Twisted-18.7.0-cp36-cp36m-win_amd64.whl
3、创建爬虫项目:
1)创建项目:
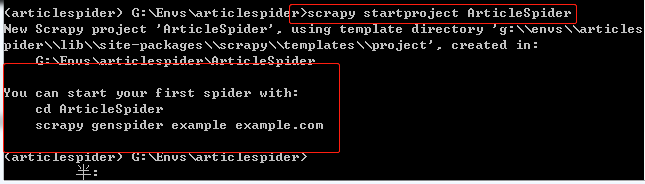
scrapy startproject ArticleSpider
创建成功:
2)项目中创建spider模块:
进入ArticleSpider ,创建spider:
#jobbole:spider名称 , blog.jobbole.com:要爬取数据的url scrapy genspider jobbole blog.jobbole.com
创建成功:

在pycharm中打开我们的ArticleSpider项目,可以看到spiders下多了一个py文件:jobbole.py
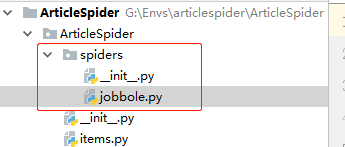
scrapy目录结构:
scrapy.cfg:配置文件setings.py:基本设置SPIDER_MODULES = ['ArticleSpider.spiders'] #存放spider的路径 NEWSPIDER_MODULE = 'ArticleSpider.spiders'
- pipelines.py:做跟数据存储相关的东西
- middilewares.py:自己定义的middlewares 定义方法,处理响应的IO操作
- init.py:项目的初始化文件
- items.py:定义我们所要爬取的信息的相关属性。Item对象是种类似于表单,用来保存获取到的数据
此时,pycharm下articlespiders项目还没完全配置好:
①、首先需要在pycharm的setting中的project interpreter下配置python:使用虚拟环境articlespider下的python3.6
②、接着,爬虫项目不像Django项目,没有自动配置好调试或运行相关,需要我们手动生成一个main.py文件,作为启动文件:
1)在articlespiders项目下新建main.py文件:
# ArticleSpiders/main from scrapy.cmdline import execute import sys,os sys.path.append(os.path.dirname(os.path.abspath(__file__))) # 父路径 execute(['scrapy','crawl','jobbole']) #执行指令:scrapy crawl jobbole ,执行后会跳到jobbole.py中执行JobboleSpider类
2)settings.py下设置不遵守reboots协议 :
ROBOTSTXT_OBEY 设为False
ROBOTSTXT_OBEY = False
执行main.py文件,报错:ModuleNotFoundError: No module named 'win32api',在虚拟环境下安装 pypiwin32 :
pip install -i https://pypi.douban.com/simple/ pypiwin32
再debug运行main.py文件,此时运行成功:

4、 xpath的使用
1)为什么要使用xpath?
- xpath使用路径表达式在xml和html中进行导航
- xpath包含有一个标准函数库
- xpath是一个w3c的标准
- xpath速度要远远超beautifulsoup
2)xpath节点关系
- 父节点
*上一层节点* - 子节点
- 兄弟节点
*同胞节点* - 先辈节点
*父节点,爷爷节点* - 后代节点
*儿子,孙子*
3)xpath语法:


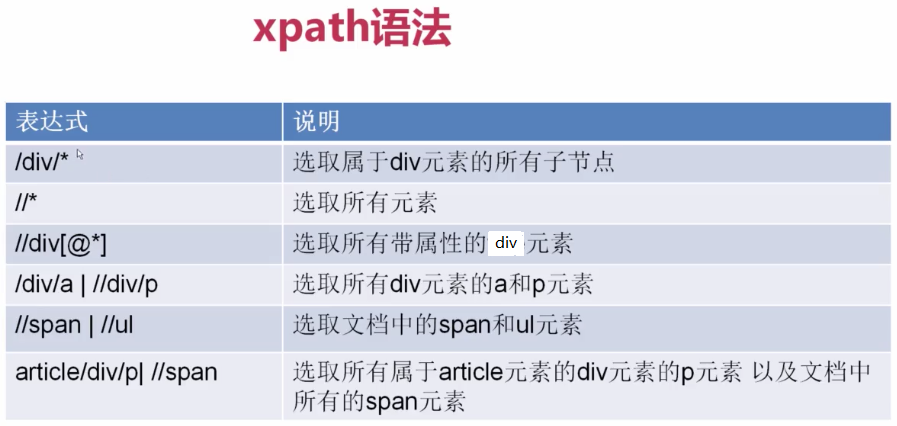
简单使用xpath基本语法爬取数据:
推荐使用class型,因为后期循环爬取可扩展通用性强
import scrapy class JobboleSpider(scrapy.Spider): name = 'jobbole' allowed_domains = ['blog.jobbole.com'] start_urls = ['http://blog.jobbole.com/'] def parse(self, response): re_selector = response.xpath("/html/body/div[1]/div[3]/div[1]/div[1]/h1/text()") # 不支持这种绝对路径,容易出错 re2_selector = response.xpath('//*[@id="post-110287"]/div[1]/h1/text()') re3_selector = response.xpath('//div[@class="entry-header"]/h1/text()')
完整的xpath提取伯乐在线字段代码:
import scrapy import re class JobboleSpider(scrapy.Spider): name = "jobbole" allowed_domains = ["blog.jobbole.com"] start_urls = ['http://blog.jobbole.com/110287/'] def parse(self, response): #提取文章的具体字段 title = response.xpath('//div[@class="entry-header"]/h1/text()').extract_first("") create_date = response.xpath("//p[@class='entry-meta-hide-on-mobile']/text()").extract()[0].strip().replace("·","").strip() praise_nums = response.xpath("//span[contains(@class, 'vote-post-up')]/h10/text()").extract()[0] fav_nums = response.xpath("//span[contains(@class, 'bookmark-btn')]/text()").extract()[0] match_re = re.match(".*?(\d+).*", fav_nums) if match_re: fav_nums = match_re.group(1) comment_nums = response.xpath("//a[@href='#article-comment']/span/text()").extract()[0] match_re = re.match(".*?(\d+).*", comment_nums) if match_re: comment_nums = match_re.group(1) content = response.xpath("//div[@class='entry']").extract()[0] tag_list = response.xpath("//p[@class='entry-meta-hide-on-mobile']/a/text()").extract() tag_list = [element for element in tag_list if not element.strip().endswith("评论")] tags = ",".join(tag_list)
小demo:
tag_list=['职场','2 评论','今昔']
[element for element in tag_list if not element.strip().endswith('评论')]
# 结果['职场', '今昔']
以上都是在pycharm中debug调试进行的,如觉麻烦可在终端开启调试模式:
scrapy shell http://blog.jobbole.com/110287/ # 开启控制台调试
5、CSS选择器
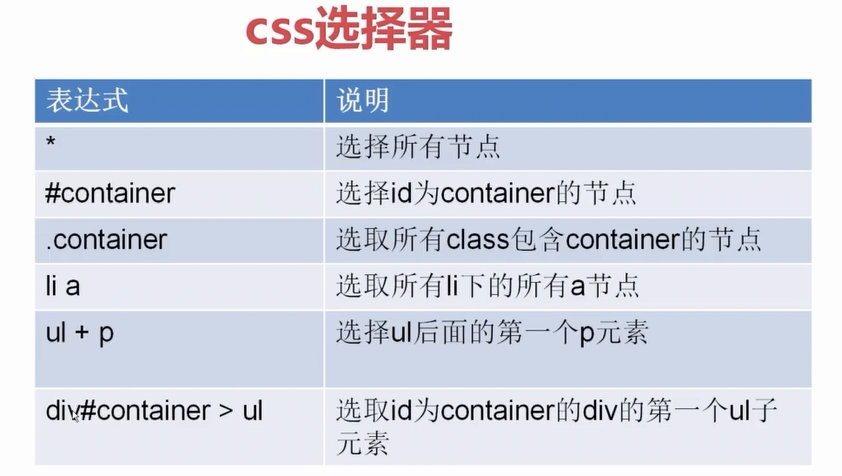
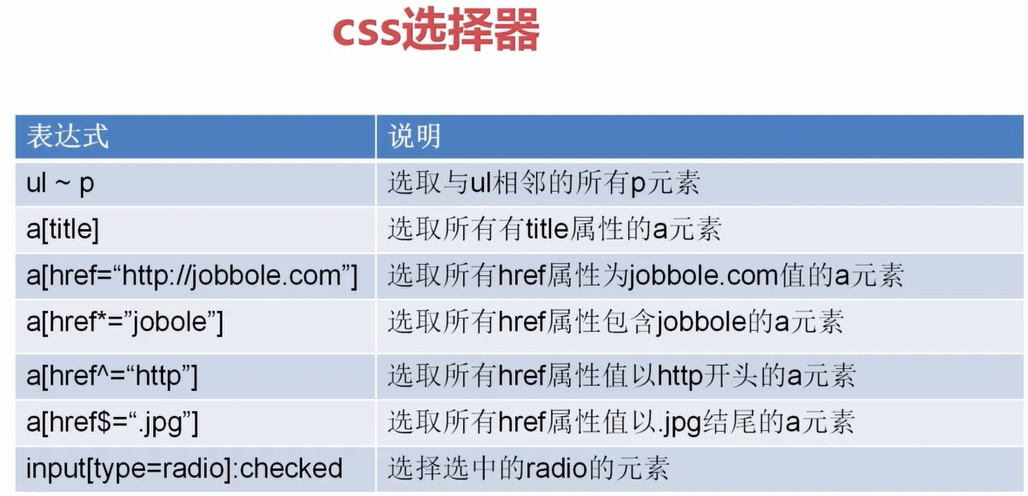

CSS选择器的使用:
# 通过css选择器提取字段 # front_image_url = response.meta.get("front_image_url", "") #文章封面图 title = response.css(".entry-header h1::text").extract_first() create_date = response.css("p.entry-meta-hide-on-mobile::text").extract()[0].strip().replace("·","").strip() praise_nums = response.css(".vote-post-up h10::text").extract()[0] fav_nums = response.css(".bookmark-btn::text").extract()[0] match_re = re.match(".*?(\d+).*", fav_nums) if match_re: fav_nums = int(match_re.group(1)) else: fav_nums = 0 comment_nums = response.css("a[href='#article-comment'] span::text").extract()[0] match_re = re.match(".*?(\d+).*", comment_nums) if match_re: comment_nums = int(match_re.group(1)) else: comment_nums = 0 content = response.css("div.entry").extract()[0] tag_list = response.css("p.entry-meta-hide-on-mobile a::text").extract() tag_list = [element for element in tag_list if not element.strip().endswith("评论")] tags = ",".join(tag_list)
爬取 http://blog.jobbole.com/all-posts/ 所有文章 :
yield关键字:
#yield Request:会将url交给scrapy引擎进行下载数据,,下载完成后会调用回调方法parse_detail()提取文章内容中的字段 yield Request(url=parse.urljoin(response.url,post_url),callback=self.parse_detail)
scrapy下的request下载网页,并执行回调函数:
from scrapy.http import Request Request(url=parse.urljoin(response.url,post_url),callback=self.parse_detail)
urllib模块下的parse.urljoin函数能拼接网址,原因是爬取到的网址可能是个相对路径,不是绝对路径,使用parse.urlkoin可以避免一些错误(具体看源码):
urljoin(参数1,参数2):如果没有参数1,url=参数二,反过来,url=参数1.如果参数1/2都存在,会提取出参数1域名,与参数2比较,再合并成一个完整url
from urllib import parse url=parse.urljoin(response.url,post_url) parse.urljoin("http://blog.jobbole.com/all-posts/","http://blog.jobbole.com/111535/") #结果为http://blog.jobbole.com/111535/
爬取所有文章完整代码:


import scrapy from scrapy.http import Request from urllib import parse class JobboleSpider(scrapy.Spider): name = 'jobbole' allowed_domains = ['blog.jobbole.com'] start_urls = ['http://blog.jobbole.com/all-posts/'] def parse(self, response): """ 1. 获取文章列表页中的文章url并交给scrapy下载后并进行解析 2. 获取下一页的url并交给scrapy进行下载, 下载完成后交给parse 流程:执行parse函数 → request下载,回调parse_detail函数 → 提取下一页交给scrapy进行下载,回调parse函数, 则又执行request下载,回调parse_detail函数,如此循环,直到获取不到下一页 """ # 解析列表页中的所有文章url并交给scrapy下载后并进行解析 post_urls = response.css("#archive .floated-thumb .post-thumb a::attr(href)").extract() for post_url in post_urls: #request下载完成之后,回调parse_detail进行文章详情页的解析 yield Request(url=parse.urljoin(response.url,post_url),callback=self.parse_detail) # 提取下一页并交给scrapy进行下载 next_url = response.css(".next.page-numbers::attr(href)").extract_first("") if next_url: yield Request(url=parse.urljoin(response.url, post_url), callback=self.parse) def parse_detail(self, response): #提取文章的具体字段 # title = response.xpath('//div[@class="entry-header"]/h1/text()').extract_first("") # create_date = response.xpath("//p[@class='entry-meta-hide-on-mobile']/text()").extract()[0].strip().replace("·","").strip() # praise_nums = response.xpath("//span[contains(@class, 'vote-post-up')]/h10/text()").extract()[0] # fav_nums = response.xpath("//span[contains(@class, 'bookmark-btn')]/text()").extract()[0] # match_re = re.match(".*?(\d+).*", fav_nums) # if match_re: # fav_nums = match_re.group(1) # # comment_nums = response.xpath("//a[@href='#article-comment']/span/text()").extract()[0] # match_re = re.match(".*?(\d+).*", comment_nums) # if match_re: # comment_nums = match_re.group(1) # # content = response.xpath("//div[@class='entry']").extract()[0] # # tag_list = response.xpath("//p[@class='entry-meta-hide-on-mobile']/a/text()").extract() # tag_list = [element for element in tag_list if not element.strip().endswith("评论")] # tags = ",".join(tag_list) #通过css选择器提取字段 front_image_url = response.meta.get("front_image_url", "") #文章封面图 title = response.css(".entry-header h1::text").extract()[0] create_date = response.css("p.entry-meta-hide-on-mobile::text").extract()[0].strip().replace("·","").strip() praise_nums = response.css(".vote-post-up h10::text").extract()[0] fav_nums = response.css(".bookmark-btn::text").extract()[0] match_re = re.match(".*?(\d+).*", fav_nums) if match_re: fav_nums = int(match_re.group(1)) else: fav_nums = 0 comment_nums = response.css("a[href='#article-comment'] span::text").extract()[0] match_re = re.match(".*?(\d+).*", comment_nums) if match_re: comment_nums = int(match_re.group(1)) else: comment_nums = 0 content = response.css("div.entry").extract()[0] tag_list = response.css("p.entry-meta-hide-on-mobile a::text").extract() tag_list = [element for element in tag_list if not element.strip().endswith("评论")] tags = ",".join(tag_list)
6、items设计
数据爬取的任务就是从非结构的数据中提取出结构性的数据。
items 可以让我们自定义自己的字段(类似于字典,但比字典的功能更齐全)
6.1、当我们爬取数据,获取数据后需要将数据传给下个函数调用,则可以利用scrapy request下的meta属性,meta接收的是字典类型,当使用request爬取数据时,将需要传递给下个函数的数据放到meta中,meta中的数据会传给下个函数的response中去,可以被下个函数使用
1)关于scrapy request的meta:
Request中meta参数的作用是传递信息给下一个函数,使用过程可以理解成: 把需要传递的信息赋值给这个叫meta的变量, 但meta只接受字典类型的赋值,因此 要把待传递的信息改成“字典”的形式,即: meta={'key1':value1,'key2':value2} 如果想在下一个函数中取出value1, 只需得到上一个函数的meta['key1']即可, 因为meta是随着Request产生时传递的, 下一个函数得到的Response对象中就会有meta, 即response.meta, meta是一个dict,主要是用解析函数之间传递值,一种常见的情况:在parse中给item某些字段提取了值,但是另外一些值需要在parse_item中提取,这时候需要将parse中的item传到parse_item方法中处理,显然无法直接给parse_item设置而外参数。 Request对象接受一个meta参数,一个字典对象,同时Response对象有一个meta属性可以取到相应request传过来的meta
2)关于urllib parse.urljoin(url1,url2)
parse.url:能将相对路径,自动补充域名补全路径,前提主域名response能获取域名路径
一般爬取网上数据时,存在网页某些url是相对路径形式展示的,通过js代码等操作补全,此时我们要爬取完整url路径,就需要用到parse.urljoin方法了
如果你是相对路径,没有补全域名,我就从response里取出来补全,如果你有域名我则不起作用
获取文章url及封面图url,爬取下载页面相应数据:

调用callback函数,meta里的数据可以传递到parse_detail函数中调用:

项目创建成功,在项目ArticleSpider/ArticleSpider目录下有个items.py文件,如上述所说,我们能将爬取到的数据通过自定义自己的字段(类似字典),保存起来,之后可以通过pipelines.py文件,将数据保存到数据库等地方去。
6.2、items.py创建类 JobBoleArticleItem ,继承于scrapy.Itme:
class JobBoleArticleItem(scrapy.Item): title = scrapy.Field() create_date = scrapy.Field() url = scrapy.Field() url_object_id = scrapy.Field() front_image_url = scrapy.Field() front_image_path = scrapy.Field() praise_nums = scrapy.Field() comment_nums = scrapy.Field() fav_nums = scrapy.Field() content = scrapy.Field() tags = scrapy.Field()
6.3、在jobbole.py parse_detail 中实例化 JobBoleArticleItem , 并将爬取到的数据放入 JobBoleArticleItem 对象中:
from ArticleSpider.items import JobBoleArticleItem
def parse_detail(self, response):
article_item = JobBoleArticleItem() # 实例化 article_item["title"] = title # 保存获取到的数据到Item 中 article_item["url"] = response.url article_item["create_date"] = create_date article_item["front_image_url"] = [front_image_url] article_item["praise_nums"] = praise_nums article_item["comment_nums"] = comment_nums article_item["fav_nums"] = fav_nums article_item["tags"] = tags article_item["content"] = content
接着在 parse_detail 中添加代码:
article_item数据会传到pipelines当中去
yield article_item
同时,setting中添加代码:
# setting.py ITEM_PIPELINES = { 'ArticleSpider.pipelines.ArticlespiderPipeline': 300, }
ITEM_PIPELINES:item的管道,配置好ArticlespiderPipeline路径,当执行代码 yield article_item 时,程序会转到pipelines.py文件中执行 ArticlespiderPipeline 类,
也就是通过 yield article_item 将article_item数据传给pipelines调用。并执行pipelines中的相关类,如: ArticlespiderPipeline ,在 ArticlespiderPipeline 类中,我们可以通过代码编写,将数据存到数据库中去
ArticlespiderPipeline 代码:
class ArticlespiderPipeline(object): def process_item(self, item, spider): return item
item中有个key:_value , _value中存放着我们爬取到的所有数据:

所以目前完整爬虫执行顺序是:创建main.py,执行main函数 → 跳到spiders目录下的jobbole.py 执行 JobboleSpider 类 ,类中有parse 、parse_detail等函数 → JobboleSpider类中获取到数据,实例化 JobBoleArticleItem ,将数据保存到Items 中 ,执行 yield article_item → 跳转到pipelines.py中执行ArticlespiderPipeline 类
6.4、图片下载保存
有时候我们爬取到图片或文件等,希望把它保存到本地或数据库中
首先进入setting中 ITEM_PIPELINES 配置图片下载pipeline:
ITEM_PIPELINES={ 'scrapy.pipelines.images.ImagesPipeline': 1, }

Scrapy中的pipelines提供了默认的文件、图片、媒体等下载保存方式,如上所述,将路径配置上去就会相应的执行scrapy/pipelines的相关函数 ,
另外,ITEM_PIPELINES是一个数据管道的登记表,每一项后面的具体数字代表它的优先级,数字越小,越早进入管道执行
接下来我们新建一个images文件夹用于保存图片,在setting中配置images文件夹的路径:
project_dir = os.path.abspath(os.path.dirname(__file__)) IMAGES_STORE = os.path.join(project_dir, 'images') # 图片文件路径
指定某字段(我们获取图片路径的字段)为我们的图片文件处理
IMAGES_URLS_FIELD = "front_image_url" # 指定爬取的某(图片)字段作为图片处理
此时执行会报错:

原因是因为图片保存等需要pillow库来操作,解决方法就是在虚拟环境中安装pillow:pip install pillow

重新执行又报错:

原因是'scrapy.pipelines.images.ImagesPipeline' 中对图片的要求是数组格式,而我们目前传递的图片类型(front_image_url)是字符串格式,因此我们需要将爬取的图片类型改成数组类型获取
解决方法:
article_item["front_image_url"] = front_image_url # ↓改成数组形式 article_item["front_image_url"] = [front_image_url]
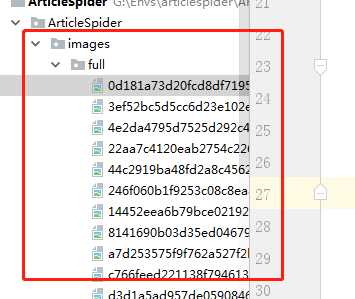
接着,重新运行项目,成功爬取到数据及下载图片成功保存:
额外知识:
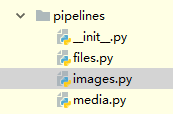
scrapy下的pipelines目录下有files.py、images.py、media.py ,用于处理文件、图片、用户上传下载媒体等数据
关于imager.py目前用到参数(常用参数可看源码):
IMAGES_URLS_FIELD = "front_image_url" # 指定该字段作为图片处理对象 IMAGES_STORE = os.path.join(project_dir, 'images') # 图片存放路径 IMAGES_MIN_HEIGHT = 100 # 图片最小高度 IMAGES_MIN_WIDTH = 100 # 图片最小宽度
使用scrapy自带的image.py处理图片,只需要按要求命名一致,以及在ITEM_PIPELINES 配置好所使用的类即可:ImagesPipeline ,
使用files.py、media.py也是一样的道理。
6.5、上面我们已经爬取到图片并保存到我们的本地中,现在我们想办法将保存到服务器或本地的图片重新绑定个路径,方便调用
1)在pipelines.py中新建自定义 ArticleImagePipeline 类,继承于ImagePipeline ,重载Scrapy下的image.py中的 item_completed方法,
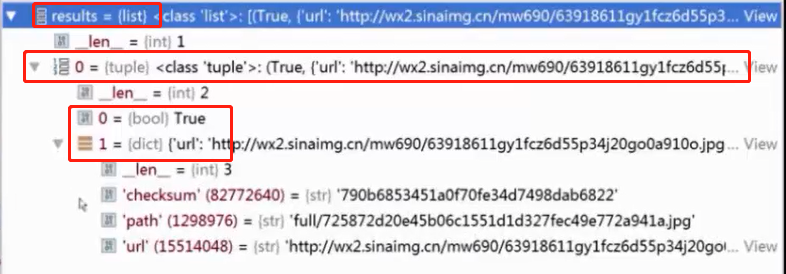
item_completed方法参数中有一个名为results的参数,该参数内部数据是个list,list内部是元组的类型,每个元组有两个子数据,第一个是状态,成功则返回True,另一个子数据是个字典类型,字典内部有个path参数,path参数存放的就是我们服务端图片保存的路径。如下:
result = {(True, {'url':'http://......'} ) }
# pipelines.py
from scrapy.pipelines.images import ImagesPipeline
class ArticleImagePipeline(ImagesPipeline): # 继承ImagePipeline def item_completed(self, results, item, info): if "front_image_url" in item: # for ok, value in results: # results[0] = ‘ok’ image_file_path = value["path"] item["front_image_path"] = image_file_path return item # 需返回item
2)items.py中JobBoleArticleItem 类,添加字段:
class JobBoleArticleItem(scrapy.Item): title = scrapy.Field() create_date = scrapy.Field() url = scrapy.Field() url_object_id = scrapy.Field() front_image_url = scrapy.Field() front_image_path = scrapy.Field() # 新增 praise_nums = scrapy.Field() comment_nums = scrapy.Field() fav_nums = scrapy.Field() content = scrapy.Field() tags = scrapy.Field()
3)在setting.py中配置我们自定义的pipelines类路径:
ITEM_PIPELINES = { 'ArticleSpider.pipelines.ArticlespiderPipeline': 300, 'scrapy.pipelines.images.ImagesPipeline': 1, # scrapy自带图片处理 'ArticleSpider.pipelines.ArticleImagePipeline': 2, #新增 , 自定义ArticleImagePipeline ,需配置好管道路径 }
通过上述三步操作,就已经把下载后的图片绝对路径保存到我们的item中去了
6.6、我们每爬取一个文章,或者说一个url,我们就应该给该url进行去重处理,这样可以避免我们在爬取数据时遇到同一个url时会重新爬一次数据。所有爬取成功的url都逐个存于response.url中,
我们现在要做的是将response中的url进行md5加密处理,之后存于数据库
1)首先,新建utils包,用于处理一些额外的函数等,在utils中新建common.py,编写get_md5函数:
关于md5加密:python3中数据默认都是Unicode类型,进行md5加密时,需要将数据转行成utf8才能进行加密,否则报错:

# utils/common.py import hashlib def get_md5(url): if isinstance(url, str): # python3中数据都是Unicode类型,需要转换成utf8才能被hash加密,否则会报错,py3中str即为Unicode url = url.encode("utf-8") # 如果是Unicode类型则encode成utf8 m = hashlib.md5() m.update(url) return m.hexdigest()
2)在jobbole.py中parse_detail函数中,将response.url 进行md5加密处理并保存到item中:
from ArticleSpider.utils.common import get_md5 def parse_detail(self, response): article_item["url_object_id"] = get_md5(response.url) # 新增 article_item["title"] = title article_item["url"] = response.url . . .
3)同时,在items.py下的 JobBoleArticleItem 中新增字段:
url_object_id = scrapy.Field()
6.7数据保存相关
1)保存到本地json文件中
方式一:
在pipelines.py文件中新建类:JsonWithEncodingPipeline
打开文件时不直接使用 open ,用python自带的codecs包,可以避免一些编码方面的问题出现
使用json.dumps时,不使用ensure_ascii=False ,默认输出中文是ASCII字符码,要想正确输出中文,需要指定ensure_ascii=False
pipelines.py/JsonWithEncodingPipelines:
import codecs class JsonWithEncodingPipeline(object): #自定义json文件的导出 def __init__(self): self.file = codecs.open('article.json', 'w', encoding="utf-8") def process_item(self, item, spider): #yield item后,跳到pipelines.py中执行对应类时,默认会执行此方法 #将item转换为dict,然后生成json对象,false避免中文出错 lines = json.dumps(dict(item), ensure_ascii=False) + "\n" self.file.write(lines) return item #scrapy.signals中的信号量状态,spider_closed:当spider关闭爬虫时调用 def spider_closed(self, spider): self.file.close()
接着在setting中的ITEM_PIPELINES 配置好:
ITEM_PIPELINES = { 'ArticleSpider.pipelines.JsonWithEncodingPipeline': 2, }
当爬虫爬取数据,保存到 Item 中,经过yield Item ,转到pipelines中执行里面的类
方式二:
使用scrapy中自带的类保存文件:
# scrapy/exporters ['BaseItemExporter',
'PprintItemExporter',
'PickleItemExporter',
'CsvItemExporter',
'XmlItemExporter',
'JsonLinesItemExporter',
'JsonItemExporter', # 保存json文件
'MarshalItemExporter']
from scrapy.exporters import JsonItemExporter class JsonExporterPipleline(object): #调用scrapy提供的json export导出json文件 def __init__(self): self.file = open('articleexport.json', 'wb') self.exporter = JsonItemExporter(self.file, encoding="utf-8", ensure_ascii=False) self.exporter.start_exporting() def close_spider(self, spider): self.exporter.finish_exporting() self.file.close() def process_item(self, item, spider): self.exporter.export_item(item) return item
接着在setting中配置 ITEM_PIPELINES:
'ArticleSpider.pipelines.JsonExporterPipleline ': 6
2)将 数据保存到mysql中
首先,在Navicat中新建数据库article_spider ,再新建表,之后填充数据类型:
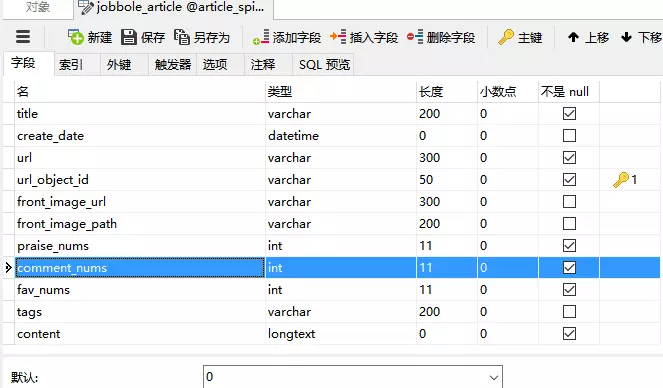
其中,
1、create_date ,在数据库中是datetime类型,我们在爬取数据时是以字符串形式保存,因此需要更改下item['create_date']类型:
import datetime try: create_date = datetime.datetime.strptime(create_date, "%Y/%m/%d").date() except Exception as e: create_date = datetime.datetime.now().date()
注:
datetime.datetime.strptime():将字符串转换成日期格式
datetime.datetime.strftime():将日期格式转换成字符串
datetime.datetime.strftime().date():日期
datetime.datetime.strftime().time():时间
datetime.datetime.now():当前日期时间
datetime.datetime.now().date():当前日期
2、需要设定一个主键,我们用url_object_id 来做主键

准备工作弄好,需要在虚拟环境下安装:mysqlclient
pip install mysqlclient
安装成功即可以开始我们的数据保存到mysql操作了
方式一: 利用pipelines保存数据到数据库(同步)
import MySQLdb class MysqlPipeline(object): #采用同步的机制写入mysql def __init__(self): self.conn = MySQLdb.connect('127.0.0.1', 'root', 'password', 'article_spider', charset="utf8", use_unicode=True) self.cursor = self.conn.cursor() def process_item(self, item, spider): insert_sql = """ insert into jobbole_article(title, url, create_date, fav_nums) VALUES (%s, %s, %s, %s) """ self.cursor.execute(insert_sql, (item["title"], item["url"], item["create_date"], item["fav_nums"])) self.conn.commit()
useUnicode=true&characterEncoding=UTF-8 作用:
添加的作用是:指定字符的编码、解码格式。 例如:mysql数据库用的是gbk编码,而项目数据库用的是utf-8编码。这时候如果添加了useUnicode=true&characterEncoding=UTF-8 ,那么作用有如下两个方面: 1. 存数据时: 数据库在存放项目数据的时候会先用UTF-8格式将数据解码成字节码,然后再将解码后的字节码重新使用GBK编码存放到数据库中。 2.取数据时: 在从数据库中取数据的时候,数据库会先将数据库中的数据按GBK格式解码成字节码,然后再将解码后的字节码重新按UTF-8格式编码数据,最后再将数据返回给客户端
接着,在setting中的 ITEM_PIPELINES 配置:
'ArticleSpider.pipelines.MysqlPipeline ': 7
方式二:利用pipelines保存数据到数据库(twisted异步)
因为我们的爬取速度可能大于数据库存储的速度,最好是异步操作(异步化操作mysql)
首先,我们将数据库连接的相关配置参数转到setting.py中配置:
MYSQL_HOST = "127.0.0.1" MYSQL_DBNAME = "article_spider" MYSQL_USER = "root" MYSQL_PASSWORD = "123456"
接着在pipelines.py中新建类:MysqlTwistedPipline ,编写代码如下:
执行顺序:from_settings → init → pross_item
import MySQLdb import MySQLdb.cursors from twisted.enterprise import adbapi class MysqlTwistedPipeline(object): def __init__(self,dbpool): self.dbpool = dbpool @classmethod def from_settings(cls,settings): # 读取配置文件信息,在类初始化(实例)时调用 dbparm = dict( host = settings["MYSQL_HOST"], db = settings["MYSQL_DBNAME"], user = settings["MYSQL_USER"], passwd = settings["MYSQL_PASSWORD"], charset = 'utf8', cursorclass = MySQLdb.cursors.DictCursor, # 字典类型,还有一种json类型 use_unicode = True, ) dbpool = adbapi.ConnectionPool("MySQLdb",**dbparm) #tadbapi.ConnectionPool:wisted提供的一个用于异步化操作的连接处(容器)。将数据库模块,及连接数据库的参数等传入即可连接mysql return cls(dbpool) # 实例化 MysqlTwistedPipeline def process_item(self,item,spider): # 操作数据时调用 query = self.dbpool.runInteraction(self.sql_insert,item) #在连接池执行mysql语句相应操作 ,异步操作 query.addErrback(self.handle_error,item,spider) # 异常处理 def handle_error(self,failure,item,spider): # 处理异常 print("异常:",failure) def sql_insert(self,cursor,item): # 数据插入操作 insert_sql = """ insert into article_spider(title, url, create_date, fav_nums,url_object_id) VALUES (%s, %s, %s, %s,%s) """ cursor.execute(insert_sql,(item["title"],item["url"],item["create_date"],item["fav_nums"],item["url_object_id"]))
最后,切记一定要在setting中的ITEM_PIPELINES 配置好路径:
ITEM_PIPELINES = { 'ArticleSpider.pipelines.MysqlTwistedPipeline': 3, }
关于mysql数据增删改查,也可以使用django ORM模式,需下载相关依赖包,具体参考:
https://github.com/scrapy-plugins/scrapy-djangoitem
7、scrapy item loader机制
使用scrapy的itemloader来维护提取代码,
itemloadr提供了一个容器,让我们配置某一个字段该使用哪种规则
from scrapy.loader import ItemLoader # 三种方法 add_css add_value # 与其他两种不同,这种是直接获取value。如获取request爬取的url:add_value(“url”,response.url) add_xpath
使用scrapy itemloader的方法,获取到的数据都是列表类型,如果我们要拿的是具体value数据,就需要做进一步处理。
item.py中定义的类中的字段可以带两个参数,我们可以通过scrapy自带的MapCompose来处理函数,再把结果以参数形式传给item下类的各字段:
MapCompose:用来处理函数
scrapy.Field:可接收两个参数(也可不填,按默认):
input_processor:预处理,当数据传进来时可以将数据进一步处理
output_processor:输出,经预处理后的数据再输出
from scrapy.loader.processors import MapCompose def add_mtianyan(value): #自定义函数,用于MapCompose调用。被调用时参数value即为调用方传入的value,如下面函数中调用,参数value即为title中的数据,接着对value进一步处理后再将处理好数据返回给title return value+"-mtianyan" class JobBoleArticleItem(scrapy.Item): title = scrapy.Field( input_processor=MapCompose(lambda x:x+"mtianyan",add_mtianyan), # 使用MapCompose处理函数,每个数据传入时都会调用一次MapCompose,再经过MapCompose调用设定的函数,有几个函数就调用几个函数 output_processor=TakeFirst() # 该字段返回列表类型,此行代码表示:取第一个数据
) )
itemloader使用
1)在item.py中自定义 ArticleItemLoader 类,继承于 ItemLoader :
class ArticleItemLoader(ItemLoader): #自定义itemloader中output_processor默认方法,实现默认提取第一个数据 default_output_processor = TakeFirst()
2)在jobbole.py中的parse_detail 方法中,实例化ArticleItemLoader ,并使用ItemLoader自带方法爬取数据,并放置到item中:
#from scrapy.loader import ItemLoader from pipelines import ArticleItemLoader # 通过item loader加载item front_image_url = response.meta.get("front_image_url", "") # 文章封面图 # item_loader = ItemLoader(item=JobBoleArticleItem(), response=response) item_loader = ArticleItemLoader(item=JobBoleArticleItem(), response=response) # 使用自定义ItemLoader实例化JobBoleArticleItem item_loader.add_css("title", ".entry-header h1::text") item_loader.add_value("url", response.url) item_loader.add_value("url_object_id", get_md5(response.url)) item_loader.add_css("create_date", "p.entry-meta-hide-on-mobile::text") item_loader.add_value("front_image_url", [front_image_url]) item_loader.add_css("praise_nums", ".vote-post-up h10::text") item_loader.add_css("comment_nums", "a[href='#article-comment'] span::text") item_loader.add_css("fav_nums", ".bookmark-btn::text") item_loader.add_css("tags", "p.entry-meta-hide-on-mobile a::text") item_loader.add_css("content", "div.entry") #最后,一定要调用这个方法来对规则进行解析生成item对象 article_item = item_loader.load_item()
yield article_item
自定义ArticleItemLoader的好处:
爬虫爬取数据时,使用ItemLoader机制获取到的数据都是列表类型,如果每个字段都加output_processor参数,显得冗余,通过自定义ArticleItemLoader类,实现默认output_processor方法,之后每个字段的output_processor都会默认使用ArticleItemLoader的默认output方法
scrapy.Field自带的两个参数,除了output_processor外,另外一个参数input_processor可以对字段进行一些另外的处理,再将数据返回给字段。比如说,要将爬取到的图片路径(字符串格式)转换成日期格式:
def get_date(value):# value为爬取到的url(字符串格式) try: create_date = datetime.datetime.strptime(value,'%Y/%m/%d').date() # 将字符串格式的url转换成日期格式,再传回给该字段 except Exception as e: create_date = datetime.date.now().date() return create_date
接着,在item.py下的 JobBoleArticleItem类中处理:
scrapy 自带的MapCompose模块,可以处理函数相关
from scrapy.loader.processors import MapCompose class JobBoleArticleItem(scrapy.Item): create_date = scrapy.Field( input_processor=MapCompose(get_date), # 此时获取到的数据即为日期格式 )
这样就可以注释掉一堆爬虫爬取数据的冗余代码了:

爬取伯乐技术网站所有文章完整代码
1、setting.py:
import os BOT_NAME = 'ArticleSpider' SPIDER_MODULES = ['ArticleSpider.spiders'] NEWSPIDER_MODULE = 'ArticleSpider.spiders' ROBOTSTXT_OBEY = False ITEM_PIPELINES = { 'ArticleSpider.pipelines.ArticlespiderPipeline': 300, 'ArticleSpider.pipelines.ArticleImagePipeline': 2, # 用于图片下载时调用 # 'ArticleSpider.pipelines.JsonWithEncodingPipeline': 3, # 方式一:用于保存item 数据 ,在图片下载之后再调用 'ArticleSpider.pipelines.MysqlTwistedPipeline': 4, # 方式三:异步数据库保存item数据 # 'ArticleSpider.pipelines.JsonExporterPipleline': 3, # 方式二:使用scrapy提供的JsonItemExporter保存json文件,用于保存item 数据 # 'scrapy.pipelines.images.ImagesPipeline':1 # scrapy中的pipelines自带的ImagesPipeline,用于图片下载,另外还有图片、媒体下载 } BASE_DIR = os.path.dirname(os.path.abspath(__file__)) IMAGES_STORE = os.path.join(BASE_DIR,'images') # 名称是固定写法,文件保存路径 IMAGES_URLS_FIELD = "acticle_image_url" # 名称是固定写法。设定acticle_image_url字段为图片url,下载图片时找此字段对应的数据 ITEM_DATA_DIR = os.path.join(BASE_DIR,"item_data") # item数据保存到当地item_data文件夹 # mysql配置 MYSQL_HOST = "127.0.0.1" MYSQL_DBNAME = "article_spider" MYSQL_USER = "root" MYSQL_PASSWORD = "******"
2、jobbole.py:
import scrapy from scrapy.http import Request from urllib import parse from ArticleSpider.items import JobBoleActicleItem,ArticleItemLoader from ArticleSpider.util.common import get_md5 class JobboleSpider(scrapy.Spider): name = 'jobbole' allowed_domains = ['blog.jobbole.com'] # start_urls = ['http://blog.jobbole.com/'] start_urls = ['http://blog.jobbole.com/all-posts/'] def parse(self, response): # 爬取伯乐网所有的文章目标信息 # 1、获取文章列表页的所有url,并交由scrapy进行逐个下载,通过回调函数:parse_detail解析并获取目标数据 post_nodes = response.css('#archive .floated-thumb .post-thumb a') # 获取到的是个list,包含urls、imgs for post_node in post_nodes: post_url = post_node.css('::attr(href)').extract_first('') post_img = post_node.css('img::attr(src)').extract_first('') # 通过request内部meta,将img_url传给下个函数调用 yield Request(url=parse.urljoin(response.url,post_url),meta={"acticle_image_url":post_img},callback=self.parse_detail) # 2、每下载并获取完一页的文章后,接着获取下一页的url,让parse方法接着处理下一页所有文章的目标数据 next_url = response.css('.nex.page-numbers::attr(href)').extract_first('') print("nexturl",next_url) if next_url: yield Request(url=parse.urljoin(response.url,next_url),callback=parse) def parse_detail(self,response): acticle_image_url = response.meta.get("acticle_image_url", "") # 文章封面图 item_loader = ArticleItemLoader(item=JobBoleActicleItem(), response=response) # ArticleItemLoader:自定义item loader 。JobBoleActicleItem:实例化item对象 item_loader.add_css("title", "div.entry-header h1::text") item_loader.add_value("url", response.url) item_loader.add_value("url_object_id", get_md5(response.url)) item_loader.add_css("create_date", ".entry-meta-hide-on-mobile::text") item_loader.add_value("acticle_image_url", [acticle_image_url]) item_loader.add_css("praise_nums", ".vote-post-up h10::text") item_loader.add_css("comment_nums", ".btn-bluet-bigger.href-style.hide-on-480::text") item_loader.add_css("fav_nums", "span.btn-bluet-bigger.href-style.bookmark-btn.register-user-only::text") item_loader.add_css("tags", ".entry-meta-hide-on-mobile a::text") item_loader.add_css("content", ".category-it-tech") # 最后,一定要调用这个方法来对规则进行解析生成item对象 article_item = item_loader.load_item() yield article_item
3、items.py:
from scrapy.loader import ItemLoader from scrapy.loader.processors import MapCompose, TakeFirst, Join import scrapy import datetime import re class ArticleItemLoader(ItemLoader): #自定义itemloader default_output_processor = TakeFirst() def return_value(value): return value def date_convert(value): # 将str 转date格式 try: create_date = datetime.datetime.strptime(value, "%Y/%m/%d").date() except Exception as e: create_date = datetime.datetime.now().date() return create_date def get_nums(value): # 匹配评论/点赞/收藏数 match_re = re.match(".*?(\d+).*", value) if match_re: nums = int(match_re.group(1)) else: nums = 0 return nums class JobBoleActicleItem(scrapy.Item): title = scrapy.Field() # 标题 create_date = scrapy.Field( # 日期,date类型 input_processor=MapCompose(date_convert), ) url = scrapy.Field() # 爬取的url url_object_id = scrapy.Field() # 已经md5加密的爬取过的url acticle_image_url = scrapy.Field( #封面图路径,下载时需确定为list output_processor=MapCompose(return_value) # 直接返回value(列表类型),不做任何处理(默认获取第一个值) ) praise_nums = scrapy.Field( # 点赞数 input_processor=MapCompose(get_nums) ) comment_nums = scrapy.Field( # 评论数 input_processor=MapCompose(get_nums) ) fav_nums = scrapy.Field( # 收藏数 input_processor=MapCompose(get_nums) ) tags = scrapy.Field( # 标签,list类型 output_processor=MapCompose(return_value) ) content = scrapy.Field() # 内容 article_image_path = scrapy.Field() # 图片保存在服务端的地址
4、pipelines.py:
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html from scrapy.pipelines.images import ImagesPipeline from ArticleSpider.settings import ITEM_DATA_DIR from scrapy.exporters import JsonItemExporter import codecs import os import json class ArticlespiderPipeline(object): def process_item(self, item, spider): return item class ArticleImagePipeline(ImagesPipeline): # 继承ImagesPipeline,用于下载图片时进行一些处理 def item_completed(self, results, item, info): # 重载ImagesPipeline中的item_completed,下载完成时调用 if "acticle_image_url" in item: # 如果存在,表示item中有这个字段 for complete_status,value in results: # results是一个list,里面是元组类型,每个元组有两个数据,一个是状态true or false,另一个数据是个字典 image_file_path = value["path"] # value取出元组中的第二个数据(字典),该数据内的path保存中图片下载到服务器后的路径 item["article_image_path"] = image_file_path # 将图片存放路径存到item中 return item # --------------- item 数据保存 ----------------- # # class JsonWithEncodingPipeline(object): # #方式一:使用json文件的方式,保存item数据 # def __init__(self): # item_article_jsonfile = os.path.join(ITEM_DATA_DIR,'item_article.json') # self.file = codecs.open(item_article_jsonfile, 'w', encoding="utf-8") # 使用python自带的codecs打开文件,可以避免一些编码错误 # def process_item(self, item, spider): #yield item后,跳到pipelines.py中执行对应类时,默认会执行此方法 # #item是JobBoleActicleItem类型,将item转换为dict,然后生成json对象,ensure_ascii=false避免中文出错 # lines = json.dumps(dict(item), ensure_ascii=False) + "\n" # self.file.write(lines) # return item # #scrapy.signals中的信号量状态,spider_closed:当spider关闭爬虫时调用 # def spider_closed(self, spider): # self.file.close() # # item 数据保存,方式二:使用scrapy提供的JsonItemExporter保存json文件 # class JsonExporterPipleline(object): # #调用scrapy提供的json export导出json文件 # def __init__(self): # item_article_jsonfile = os.path.join(ITEM_DATA_DIR, 'item_article_export.json') # self.file = open(item_article_jsonfile, 'wb') # self.exporter = JsonItemExporter(self.file, encoding="utf-8", ensure_ascii=False) # self.exporter.start_exporting() # # def close_spider(self, spider): # self.exporter.finish_exporting() # self.file.close() # # def process_item(self, item, spider): # self.exporter.export_item(item) # 写入数据 # return item # item 数据保存,方式三:以异步方式写入数据库 import MySQLdb import MySQLdb.cursors from twisted.enterprise import adbapi class MysqlTwistedPipeline(object): def __init__(self,dbpool): self.dbpool = dbpool @classmethod def from_settings(cls,settings): # 用于读取配置文件信息,先于process_item调用 dbparm = dict( host=settings["MYSQL_HOST"], db=settings["MYSQL_DBNAME"], user=settings["MYSQL_USER"], passwd=settings["MYSQL_PASSWORD"], charset='utf8', cursorclass=MySQLdb.cursors.DictCursor, # 字典类型,还有一种json类型 use_unicode=True, ) dbpool = adbapi.ConnectionPool("MySQLdb",**dbparm) # tadbapi.ConnectionPool:wisted提供的一个用于异步化操作的连接处(容器)。将数据库模块,及连接数据库的参数等传入即可连接mysql return cls(dbpool) # 实例化 MysqlTwistedPipeline def process_item(self, item, spider): # 操作数据时调用 query = self.dbpool.runInteraction(self.sql_insert, item) # 执行mysql语句相应操作 ,异步操作 query.addErrback(self.handle_error, item, spider) # 异常处理 def handle_error(self, failure, item, spider): # 处理异常 print("异常:", failure) def sql_insert(self, cursor, item): # 数据插入操作 insert_sql = """ insert into article_spider(title, url, create_date, fav_nums,url_object_id) VALUES (%s, %s, %s, %s,%s) """ cursor.execute(insert_sql, (item["title"], item["url"], item["create_date"], item["fav_nums"], item["url_object_id"]))
5、main.py:运行主程序
from scrapy.cmdline import execute import os,sys sys.path.append(os.path.dirname(os.path.abspath(__file__))) # 将父路径添加至sys path中 execute(['scrapy','crawl','jobbole',]) # 执行:scrapy crawl jobbole 。 其中'jobbole'是jobbole.py中JobboleSpider类的name字段数据 # execute(['scrapy','crawl','jobbole','--nolog']) # --nolog:表示不打印日志

 浙公网安备 33010602011771号
浙公网安备 33010602011771号