

Python分布式爬虫打造搜索引擎
一、虚拟机linux下安装并运行pycharm:
- 下载pycharm软件包并解压,解压完成即算安装完成:
tar -zxvf pycharm-professional-5.0.4.tar.gz
注意:此次项目中用到的pycharm必须是professional版的
- 进入pycharm目录的下bin目录,执行:
./pycharm.sh # 启动pycharm
即可启动pycharm
-
将pycharm启动路径加到用户目录下的.bashrc文件中,打开.bashrc:
vim ~/.bashrc # .bashrc,是隐藏文件
设置pycharm.sh启动路径:
alias pycharm="bash /home/nan/Downloads/pycharm-2018.3.2/bin/pycharm.sh" # 此行代码添加到.bashrc文件中
注:.bashrc下做的配置,与win下的path目录作用一样,配置后,启动软件便不用跑到该目录的bin目录下执行可执行文件,而可以直接在当前目录下执行:pycharm.sh 启动软件
-
路径配置好之后,退出编辑模式,需执行:
source ~/.bashrc # 更新配置文件
此时,在用户目录下直接执行:pycharm ,便能打开pycharm编辑器了。
![]()
- 安装完专业版pycharm,在使用时是需要提供注册码的,我们可以选择用license server的方式进行注册。直接在网上搜索pycharm license server ,找到对应的(如:http://idea.lanyus.com),在pycharm中license server方式下,填上,点击确定就可以了。

附:pycharm默认部分快捷键:


Ctrl + Q # 快速查看文档 Ctrl + F1 # 显示错误描述或警告信息 Ctrl + Alt + T # 选中 Ctrl + / # 行注释 Ctrl + Shift + / # 块注释 Ctrl + W # 选中增加的代码块 Ctrl + Shift + W # 回到之前状态 Ctrl + Shift + ]/[ # 选中代码块结束、开始 Ctrl + Alt + L # 代码格式化 Ctrl + Alt + I # 自动缩进 Tab / Shift + Tab # 缩进、不缩进当前行 Ctrl + D # 复制选定的区域或行 Ctrl + Y # 删除选定的行 Ctrl + Shift + U # 将选中的区域进行大小写切换 Ctrl + Delete # 删除到字符结束 Ctrl + Backspace # 删除到字符开始 Ctrl + Numpad+/- # 展开折叠代码块 Ctrl + R # 替换 Ctrl + Shift + F # 全局查找 Ctrl + Shift + R # 全局替换 Shift + F10 # 运行 Shift + F9 # 调试 Ctrl + Shift + F10 # 运行编辑器配置 Ctrl + Alt + R # 运行manage.py任务 F8 # 调试跳过 F7 # 进入调试
二、虚拟环境virtualenv、virtualenvwrapper安装,python版本安装
参考:https://www.cnblogs.com/Eric15/articles/9517232.html
关于linux下python双版本(python2、python3),默认使用时2.7版本,通过设置,可以将默认环境改成python3.6版本:
sudo update-alternatives --install /usr/bin/python python /usr/bin/python2 100
sudo update-alternatives --install /usr/bin/python python /usr/bin/python3 150
改回python2版本:
sudo update-alternatives --config python
设置好Python默认版本为python3后,再使用Python默认就变成python3,但是这个时候,pip会出问题,可以重新装pip
sudo python3 -m pip uninstall pip && sudo apt install python3-pip --reinstall
- win/linux下都需要安装requests
- 安装scrapy
三、爬虫基础知识回顾
1、技术选型
Scrapy VS requests+beautifulsoup
- requests和bs都是库,Scrapy是框架。
- scrapy框架可以加入requests和bs。
- scrapy是基于twisted,性能(异步IO)是最大的优势。
- scrapy方便扩展,提供了很多内置的功能。
- scrapy内置的css和xpath selector非常方便,bs最大的缺点就是慢
2、爬虫能做什么?
- 搜索引擎----百度、google、垂直领域搜索引擎
- 推荐引擎----今日头条、一点资讯
- 机器学习的数据样本
- 数据分析(如金融数据分析)、舆情分析。
3、正则表达式
1)特殊符号:
^ # 开头 '^b.*'----以b开头的任意字符 $ # 结尾 '^b.*3$'----以b开头,3结尾的任意字符 * # 任意长度(次数),≥0 ? # 非贪婪模式,非贪婪模式尽可能少的匹配所搜索的字符串 '.*?(b.*?b).*'----从左至右第一个b和的二个b之间的内容(包含b) + # 一次或多次 {2} # 指定出现次数2次 {2,} # 出现次数≥2次 {2,5} # 出现次数2≤x≤5 | # 或 例如,“z|food”能匹配“z”或“food”(此处请谨慎)。“[z|f]ood”则匹配“zood”或“food”。 [] # 中括号中任意一个符合即可, '[abc]ooby123'----只要开头符合[]中任意一个即可 [^] # 取反,只要不在[]的即可(特殊符号在中括号中都没有特殊含义,比如说到的:^,在中括号中不再表示从头匹配,而只是表示取反,即没有了在正则中的特殊含义) [a-Z] # 从小a到大Z '1[48357][0-9]{9}'----电话号码 . # 匹配任意字符
\s # 匹配不可见字符 \n \t '你\s好'----可以匹配‘你 好’ \S # 匹配可见字符,即普通字符 \w # 匹配下划线在内的任何单词字符 \W # 和上一个相反 [\u4E00-\u9FA5] # 只能匹配汉字 () # 要取出的信息就用括号括起来 \d # 数字
2)匹配方式:
import re line = "hello world!" regex_str = "^h.*" match_obj = re.match(regex_str,line) # 从第一个字符开始匹配,成功则返回数据 search_obj = re.search(regex_str,line) # 从头匹配,只要过程中有匹配上,就算成功并返回数据,不会再继续匹配后面的数据 findall = re.findall(regex_str,line) # 从头匹配,匹配多个,成功的数据都返回,数据类型看下面 print(match_obj) # <_sre.SRE_Match object; span=(0, 12), match='hello world!'> print(search_obj) # <_sre.SRE_Match object; span=(0, 12), match='hello world!'> print(findall) # ['hello world!'] print(match_obj.group(0)) # hello world! print(search_obj.group(0)) #hello world! ,findall没有 group 方法 # group(0)返回匹配到的第一个数据 ,group(1)、group(2)等返回的是括号()中取出的数据
四、深度优先和广度优先
- 网站的树结构
- 深度优先算法和实现----递归
- 广度优先算法和实现----队列
1)深度优先demo:
def depth_tree(tree_node): if tree_node is not None: print (tree_node._data) if tree_node._left is not None: return depth_tree(tree_node.left) if tree_node._right is not None: return depth_tree(tree_node,_right)
2)广度优先demo:
def level_queue(root): #利用队列实现树的广度优先遍历 if root is None: return my_queue = [] node = root my_queue.append(node) while my_queue: node = my_queue.pop(0) print (node.elem) if node.lchild is not None: my_queue.append(node.lchild) if node.rchild is not None: my_queue.append(node.rchild)
五、爬虫去重策略

scrapy去重使用的是第三种方法:分布式scrapy-redis主要讲解bloomfilter去重方法
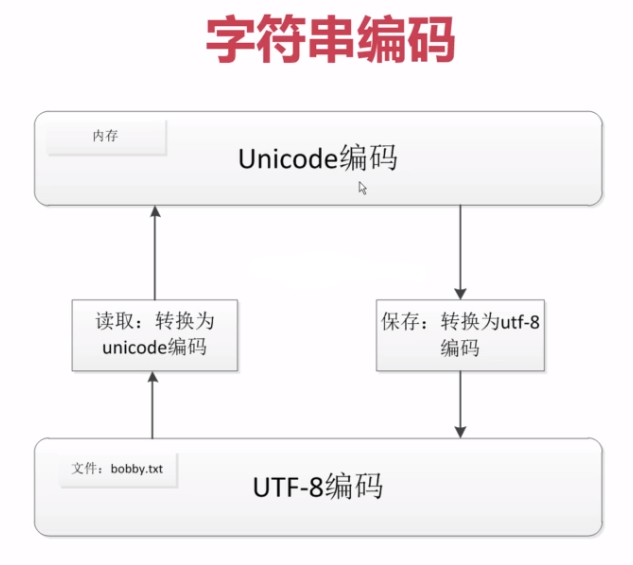
六、 字符串编码
ASCII和unicode编码:
(1)字母A用ASCII编码十进制65,二进制01000001
(2)汉字‘中’已超多ASCII编码的范围,用unicode编码是20013,二进制01001110 00101101
(3)A用unicode编码中只需要前面补0,二进制是 00000000 01000001
ASCII:一个字节 GB2312:两个字节表示一个汉字 unicode:两个字节 utf-8:可变长编码,英文1个字节,汉字三个字节
python2 默认编码格式为ASCII,Python3 默认编码为 utf-8,python2表示中文:u"中华"(Unicode编码)
不同编码之间的转换:
GB2312编码 →decode("GB2312")成Unicode编码 → encode("utf-8") 成utf-8编码 ,反过来也一样。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号