
Django+xadmin 打造线上教育平台
一、关于静态文件配置
1)在一开始设计表类型结构时,有部分表字段定义的是文件或图片类型,会有一个上传路径,如:

上传路径upload_to:org/%Y/%m是个相对路径,意思是上传到后台的图片/文件,放到org文件夹/Y(年份)文件夹/m文件夹下 , 但绝对路径没给,不知道具体放的实际位置是哪,
这个时候需要在django中配置静态文件的处理方式,在setting中配置: 上传的文件会自动存放到到/media/org/Y/m中
#settings.py # 设置上传文件的路径 MEDIA_URL = '/media/' MEDIA_ROOT = os.path.join(BASE_DIR,'media') #指定根目录
2)关于文件/图片从xadmin上传到django项目中指定的文件夹的问题已经解决,接下来说在HTML模板中使用这些文件/图片,一般有两种方式
- 简单操作的:直接用绝对路径,如:/media/org/2018/8/***.png
- 需要作配置,但比较灵活的,如:
{{ MEDIA_URL }}{{ course_org.image }} ,MEDIA_URL:是setting中设置的上传文件路径 ,course_org.image
用第二种方式需要配置:
1)setting配置:上述已说明,配置上传文件路径
2)setting中TEMPLATES下的OPTIONS要加入这一句:用于识别前端模板MEDIA_URL路径,直接转换成:/media/ ,实现 {{ MEDIA_URL }}{{ course_org.image }} → /media/org/2018/8/***.png 的转换
TEMPLATES = [ { 'BACKEND': 'django.template.backends.django.DjangoTemplates', 'DIRS': [os.path.join(BASE_DIR, 'templates')] , 'APP_DIRS': True, 'OPTIONS': { 'context_processors': [ 'django.template.context_processors.debug', 'django.template.context_processors.request', 'django.contrib.auth.context_processors.auth', 'django.contrib.messages.context_processors.messages', 'django.template.context_processors.media', # 新增,用于media处理 ], }, }, ]
3)url.py的配置:配置静态文件,是因为前端根据(2)中转换成的 /media/org/2018/8/***.png 路径,到url中serve配置好的路径找对应MEDIA_ROOT(根路径)下的media文件夹,即找到media/org/2018/8/***.png,然后显示到页面
from django.urls import path,include,re_path from django.views.static import serve # 用于处理静态文件 from MxOnline.settings import MEDIA_ROOT # media路径 urlpatterns = [ # 处理静态文件,使用Django自带serve,传入setting中路径配置MEDIAROOT,让它根据路径找 re_path(r'^media/(?P<path>.*)', serve, {"document_root": MEDIA_ROOT }), ]
一般推荐第二种,方便维护
二、自定义分页功能
views.py:


from django.shortcuts import render,redirect from organization import models from django.core.paginator import Paginator,PageNotAnInteger,EmptyPage # Create your views here. def org_list(request): """课程机构列表""" # 所有课程机构 all_orgs = models.CourseOrg.objects.all() orgs_count = all_orgs.count() # 所有城市 all_citys = models.CityDict.objects.all() # 开始分页功能 paginator = Paginator(all_orgs, 5) page = request.GET.get('_page',1) try: orgs = paginator.page(page) # 当前页显示的5个数据 print(orgs) except PageNotAnInteger: # If page is not an integer, deliver first page. orgs = paginator.page(1) except EmptyPage: # If page is out of range (e.g. 9999), deliver last page of results. orgs = paginator.page(paginator.num_pages) # paginator.num_pages:总页数,即返回最后一页 return render(request,'organization/org-list.html',locals())
app内新建templatetags包,在里面新建online_tag.py文件,用于自定义标签,返给HTML模板渲染:
from django.template import Library from django.utils.safestring import mark_safe import datetime,time register = Library() @register.simple_tag def render_paginator(orgs): """ 分页功能 从views中拿到orgs paginator = Paginator(querysets, 2) :一页显示2行 orgs = paginator.page(page):当前页码 """ ele = ''' <nav aria-label="Page navigation"> <ul class="pagination"> <li> <a href="?_page=1" aria-label="shouye"> <span aria-hidden="true">首页</span> </a> </li> ''' if orgs.has_previous(): p_ele = ''' <li><a href="?_page=%s" aria-label="Previous" >prev</a></li> ''' % (orgs.previous_page_number()) ele += p_ele # querysets.paginator=paginator,page_range:页数范围 for i in orgs.paginator.page_range: # querysets.number:当前页码 if abs(orgs.number - i) < 3:# 只显示相邻页码,最多2页 active = '' # 当前页 if orgs.number ==i : active = 'active' p_ele = ''' <li class="%s"><a href="?_page=%s">%s</a></li> '''% (active,i,i) ele += p_ele #是否有下一页 if orgs.has_next(): p_ele = ''' <li><a href="?_page=%s" aria-label="Next">next</a></li> ''' % (orgs.next_page_number()) ele += p_ele #querysets.paginator.num_pages:总页数 p_ele = ''' <li> <a href="?_page=%s" aria-label="weiye"> <span aria-hidden="true">尾页</span> </a> </li> '''% (orgs.paginator.num_pages) ele += p_ele ele += "</ul></nav>" return mark_safe(ele)
HTML界面只需要一个导入跟一句代码便能实现分页功能:
{% load mxonline_tags %}
<div class="pageturn">
{# 分页#}
{% render_paginator orgs %}
</div>
三、django自带form.Form、form.ModelForm
1、form.Form:
1.1、创建Form类
from django.forms import Form from django.forms import widgets from django.forms import fields class FM(Form): user = fields.CharField( error_messages={'required':'用户名不能为空'} ) pwd = fields.CharField( max_length=18, min_length=9, error_messages={'required':'密码不能为空','max_length':'密码长度不能大于12','min_length':'密码长度不能小于6'}, widget=widgets.PasswordInput(attrs={'class':'c1','id':'i1'}) ) email = fields.EmailField( error_messages={'required': '邮箱不能为空.', 'invalid': "邮箱格式错误"} ) gender = fields.ChoiceField( choices=((1,'男'),(2,'女'),), initial = 2, #默认值 # widget=widgets.Select widget=widgets.RadioSelect ) city = fields.CharField( initial=2, widget=widgets.Select(choices=((1,'上海'),(2,'北京'),)) ) abc = fields.MultipleChoiceField( choices=((1,'a'),(2,'b'),(3,'c'),(4,'d')), initial=[1,2], widget = widgets.CheckboxSelectMultiple )

1.2、views.py函数处理:
def form(request): if request.method == 'GET': obj = FM() return render(request,'form.html',{'obj':obj}) elif request.method == 'POST': obj = FM(request.POST) if obj.is_valid(): values = obj.clean() print(values) else: errors = obj.errors print(errors) return render(request,'form.html',{'obj':obj})

1.3、HTML页面:
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> </head> <body> <form method="post" action="#"> {% csrf_token %} <p>{{ obj.user }}{{ obj.user.errors.0 }}</p> <p>{{ obj.pwd }}{{ obj.pwd.errors.0 }}</p> <p>{{ obj.email }}{{ obj.email.errors.0 }}</p> <p>{{ obj.city }}{{ obj.city.errors.0 }}</p> <p>{{ obj.gender }}{{ obj.gender.errors.0 }}</p> <p>{{ obj.abc }}{{ obj.abc.errors.0 }}</p> <input type="submit" value="提交"> </form> </body> </html>
1.4、自定义验证:
1)clean_%s(self) #clean_ + 要审查的那个字段
这种是验证单个字段的:

2)c.clean(self) # 重写clean方法
这种可以验证多个字段:
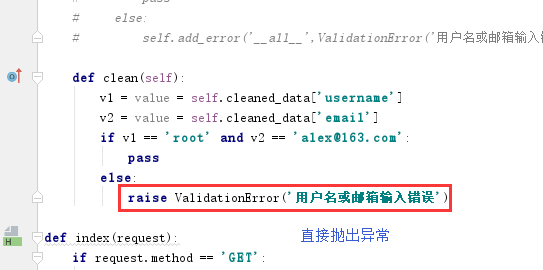
demo:
views.py from django.shortcuts import render,redirect,HttpResponse from cmdb import models from django import forms from django.forms import fields from django.core.exceptions import ValidationError class UserForm(forms.Form): username = fields.CharField(label='用户名') email = fields.EmailField(label='email') user_type = fields.ChoiceField(choices=models.UserType.objects.values_list('id', 'name')) def clean_username(self): # 自定义错误验证-->验证单个 value = self.cleaned_data['username'] if value == 'root': return value else: raise ValidationError('用户名输入错误') def _post_clean(self): # 自定义错误验证-->验证多个 v1 = value = self.cleaned_data['username'] v2 = value = self.cleaned_data['email'] if v1 == 'root' and v2 == 'alex@163.com': pass else: self.add_error('__all__',ValidationError('用户名或邮箱输入错误')) def clean(self): v1 = value = self.cleaned_data['username'] v2 = value = self.cleaned_data['email'] if v1 == 'root' and v2 == 'alex@163.com': pass else: raise ValidationError('用户名或邮箱输入错误') def index(request): if request.method == 'GET': obj = UserForm() return render(request,'index.html',{'obj':obj}) elif request.method == 'POST': obj = UserForm(request.POST) print(obj.is_valid()) # print(obj.clean()) print(obj.cleaned_data) print(obj.errors) return render(request, 'index.html', {'obj': obj}) index.html <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> </head> <body> <form action="/index/" method="post"> {% csrf_token %} {{ obj.as_p }} <input type="submit" value="提交" /> </form> </body> </html>
2、form.ModelForm
2.1、创建ModelForm类:
class UserAskForm(forms.ModelForm): class Meta: model = UserAsk fields = ['name', 'mobile', 'course_name']

ModelForm的自定义验证方法跟Form的自定义验证方法是一样的,内置字段名也基本一致,可以参考Form类的介绍,如:
数据以字典形式存于cleaned_data中,错误以字典形式存于errors中
ModelForm与Form的不同点:
ModelForm:字段不需要自己写,与model中定义的数据表相通、一致;验证数据通过后可以通过 .save() 直接保存
From:字段需要自己手动添加,只验证字段是否合法,数据保存之类需要手动保存
四、自定义404、500页面
django项目,自定义404、500页面时,需要项目setting中配置:
DEBUG=False ,
ALLOWED_HOSTS = ['*',](或ALLOWED_HOSTS = ['127.0.0.1','localhost','192.168.1.155']等),表示允许访问本项目的地址
配置完这两个,就可以自定义全局404 、500页面了
但,当DEBUG设置为False,此时setting中设置的静态文件路径,django均不会自动帮你配置,当HTML模板中需要用到setting中设置的静态文件路径时,一种是直接指定绝对路径:/static/image/xx.png ;另一种是手动配置静态文件
路径:
首先,setting中配置是:
STATIC_URL = '/static/' STATICFILES_DIRS = [ os.path.join(BASE_DIR,'static'), ] MEDIA_URL = '/media/' MEDIA_ROOT = os.path.join(BASE_DIR,'media')
然后需要在urls.py中配置:
DEBUG=True时,static路径在url下不需要配置
from django.views.static import serve from MxOnline.settings import MEDIA_ROOT,STATICFILES_DIRS urlpatterns = [ # 处理静态文件,使用Django自带serve,传入setting中路径配置MEDIAROOT,让它根据路径找media下的文件 re_path(r'^media/(?P<path>.*)', serve, {"document_root": MEDIA_ROOT }), #需要手动static_dirs路径,然后使用serve根据路径帮忙找到static下的文件 re_path(r'^static/(?P<path>.*)', serve, {"document_root": STATICFILES_DIRS[0] }), ]
好了,准备工作完成了,开始全局404 、500页面操作
1、404页面:
views:
from django.shortcuts import render_to_response def pag_not_found(request): # 全局404处理函数 response = render_to_response('404.html') response.status_code = 404 return response
urls:
# 全局404页面配置 handler404 = 'MxOnline.views.pag_not_found'
HTML页面:
{% load staticfiles %}
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>404</title>
<link rel="stylesheet" type="text/css" href="{% static 'css/reset.css' %}">
<link rel="stylesheet" type="text/css" href="{% static 'css/animate.css' %}">
<link rel="stylesheet" type="text/css" href="{% static 'css/style.css' %}">
<script type="text/javascript" src="{% static 'js/jquery.min.js' %}"></script>
</head>
<body class="bg404 errorpage">
<section>
<div class="wp">
<div class="cont">
<img src="{% static 'images/pic404.png' %}"/>
<br/><br/><br/><br/>
<p>wow~这个页面被外星人抢走了~</p>
<br/>
<span>Wow~ this page was the alien took ~</span>
</div>
</div>
</section>
</body>
</html>
2、500页面:
views:
from django.shortcuts import render_to_response def page_error(request): # 全局500处理函数 from django.shortcuts import render_to_response response = render_to_response('500.html') response.status_code = 500 return response
urls:
# 全局500页面配置 handler500 = 'MxOnline.views.page_error'
HTML页面:
{% load staticfiles %}
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>500</title>
<link rel="stylesheet" type="text/css" href="{% static 'css/reset.css' %}">
<link rel="stylesheet" type="text/css" href="{% static 'css/animate.css' %}">
<link rel="stylesheet" type="text/css" href="{% static 'css/style.css' %}">
<script type="text/javascript" src="{% static 'js/jquery.min.js' %}"></script>
</head>
<body class="bg503 errorpage">
<section>
<div class="wp">
<div class="cont">
<div class="fl error_cut"><img src="{% static 'images/pic503.png' %}"/></div>
<div class="fr error_cut">
<img src="{% static 'images/word503.png' %}"/>
<br/><br/><br/><br/><br/><br/>
<p>服务器错误,请稍后重新刷新。</p>
</div>
</div>
</div>
</section>
</body>
</html>
注意:2.0版本,测试中发现:只要将debug设置为False,将自定义404 、 500(必须命名:404.html 、 500.html)页面导入到项目中的templates中,当url访问出错(404 、 500状态码)时,会自动调用404.html、500.html页面
五、常见web攻击及防范
1、sql注入攻击
sql注入的危害
- 非法读取、篡改、删除数据库中的数据
- 盗取用户的各类敏感信息,获取利益
- 通过修改数据库来修改网页上的内容
- 注入木马等
sql注入案例(使用原生sql语句):
<select id="query" parameterType="com.sky.model.User" resultType="com.sky.model.User"> select * from user where name = '${name}' </select>
当用户输入name值为 : ' or 1='1 时,上述select代码变成:
select * from user where name = '' or 1='1'
此时判断逻辑是符合要求的。类似这种就是sql注入。
2、xss攻击及防范
xss跨站脚本攻击(Cross Site Scripting)的危害
- 盗取各类用户账号,如用户网银账号、各类管理员账号
- 盗窃企业重要的具有商业价值的资料
- 非法转账
- 控制受害者机器向其他网站发起攻击、注入木马等等
xss攻击流程:
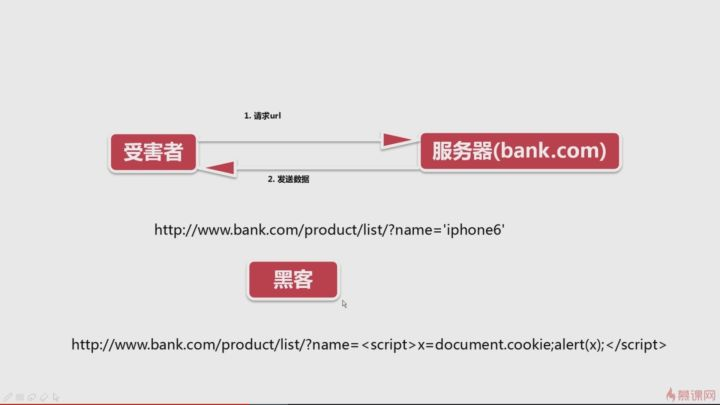
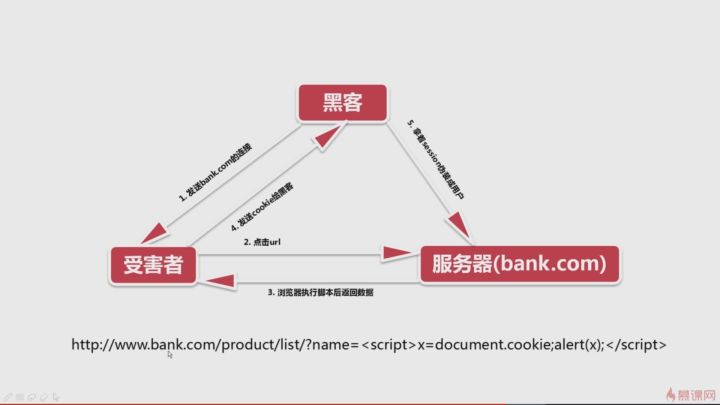
xss攻击防护
- 首先代码里对用户输入的地方和变量都需要仔细检查长度和对<>;'等字符做过滤
- 避免直接在cookie中泄漏用户隐私,例如email、密码等
- 通过使cookie和系统ip绑定来降低cookie泄漏后的危险
- 尽量采用POST而非GET提交表单
xss-对于文本/富文本漏洞导致的xss攻击的防护:
普通文本xxs攻击防护:
后端展示数据到前端时,第一种方式是在前面模板中不要使用 safe过滤器,如展示评论:{% for comment in all_comment|safe %} ,加了safe过滤器,会导致Django模板开启的自动转义被关闭,此时如果用户提交了一些js脚本等,展示到前端时就会被渲染成标签,进入执行js指定危害操作。
第二种是在Django后台导入 escape 过滤器(from django.template.defaultfilters import escape) ,然后将前端用户提交上来的数据进行转义(假如包含js等脚本代码)再存入数据库中,这样js脚本等也都会被转义,再从数据库中取出,然后到前端展示,即使使用了safe过滤器也不会被渲染为js脚本执行。
富文本xxs攻击防护:
对于富文本提交的数据,肯定会包含一些html标签操作(如:字体颜色、字体样式等),这种要返回前端渲染展示时,就需要我们使用safe过滤器来将其标记为安全的,这样才能显示出富文本样式。这种情况就存在着xss脚本攻击的危险。但我们可以在后端对数据进行一些额为处理,比如:将需要的标签保留下来,把不需要的标签进行转义或移除掉。在python中,有一个库可以专门用来处理这个事情,具体解决方法如下:
1)首先安装bleach库:pip install bleach
bleach 库是用来清理包含 HTML 格式字符串的库。他可以指定哪些标签需要保留,哪些标签是需要过滤掉的,也可以指定标签上哪些属性是可以保留,哪些属性是不需要的。demo:
import bleach from bleach.sanitizer import ALLOWED_TAGS,ALLOWED_ATTRIBUTES @require_http_methods(['POST']) def add_comment(request): # 前端提交的数据,指定img标签及其下的src属性可以保留使用 content = request.POST.get('content') # 评论 # content = escape(content) tags = ALLOWED_TAGS + ['img'] # 在默认允许的标签中添加img标签 attributes = {**ALLOWED_ATTRIBUTES,'img':['src']} # 在默认允许的属性中添加src属性 cleaned_data = bleach.clean(content,tags=tags,attributes=attributes) # 对提交的数据进行过滤 Comment.objects.create(content=cleaned_data) # 保存到数据库 return redirect(reverse('index'))
ALLOWED_TAGS中,默认允许的标签:a 、abbr、acronym、b、blockquote、code、em、i、li、ol、ul、strong
ALLOWEND_ATTRIBUTES中,默认允许的属性:a标签允许:href、title ;abbr标签允许:title ; acronym标签允许:title
demo中方法介绍:
tag:表示允许哪些标签
attributes:表示标签中允许哪些属性
ALLOWED_TAGS:这个变量默认定义l一些允许的标签
ALLOWEND_ATTRIBUTES中:这个变量默认定义了一些允许的属性
bleach.clean方法:对提交的数据进行过滤
3、csrf攻击及防范
csrf跨站请求伪造(Cross-site request forgery)的危害
- 以你的名义发送邮件
- 盗取你的账号
- 购买商品
- 虚拟货币转账
CSRF攻击流程:

CSRF攻击防范:
在form里面加上 {% csrf_token %}
4、clickjacking攻击
clickjacking 攻击又称点击劫持攻击,是一种在网页中将恶意代码等隐藏在看似无害的内容(如按钮)之下,并诱惑用户点击的手段。
攻击场景:
1、给用户发邮件,诱惑用户点开,当用户点开的时候其实链入的是一购物网站等等
2、用户进入到一个网页中,里面包含一个非常有诱惑力的按钮A,但是这个按钮上面浮了一个透明的iframe标签,这个iframe标签加载的是另外一个网页,并且这个网页的某个按钮和原网页中的按钮重合。所以你在点击按钮A的时候,实际上点击的是通过iframe加载的另外一个网页的按钮。
clickjacking防护:
场景1的情形是无法避免的。而像场景2是可以避免的,只要设置该网站不允许使用iframe被加载到其他网页中就可以了。我们可以通过在响应头设置X-Framen-Option 来设置这种操作。X-Frame-Option 可以设置以下三个值:
DENY:不让任何网页使用iframe加载我这个页面
SAMEORIGIN:只允许在相同域名下使用iframe 加载我的页面
ALLOW-FROM origin:允许任何网页通过iframe 加载我这个网页
在Django 中,使用中间件 django.middleware.clickjacking.XFrameOptionsMiddleware 可以帮我们堵上这个漏洞,这个中间件设置了 X-Frame-Option 为 SAMEORIGIN ,也就是只有在自己的网站下才可以使用iframe 加载这个网页,这样就可以避免其他别有心机的网页去通过iframe加载我们的网页了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号