
一、课前准备
1、本地通过Xshell连接虚拟机Ubuntu终端
1)下载Xshell
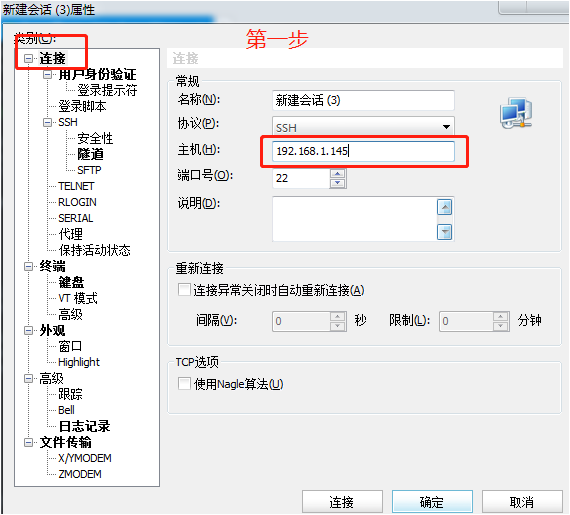
2)打开xshell,新建会话
3)连接:协议选 SSH , 主机号填虚拟机ip地址 192.168.1.145
4)身份验证

ps:如首次连接不成功,可能是服务端(linux)没开启或没安装ssh服务:
输入:#ps -e |grep ssh 如果服务已经启动,则可以同时看到“ssh-agent”和“sshd”,否则表示没有安装ssh服务,或没有开机启动
安装ssh服务,输入命令:#sudo apt-get install openssh-server
启动服务:#/etc/init.d/ssh start
本机测试是否能够成功登录:#ssh -l 用户名 本机ip
2、Ubuntu/Linux下软件安装后相关文件存放的位置
1)下载的软件存放位置:
/var/cache/apt/archives
2)安装后软件默认位置:
/usr/share
3)可执行文件位置:
/usr/bin
4)配置文件位置
/etc
5)lib文件位置
/usr/lib
3、通过本地RedisDesktopManager桌面管理,连接虚拟机Ubuntu中的redis-server端
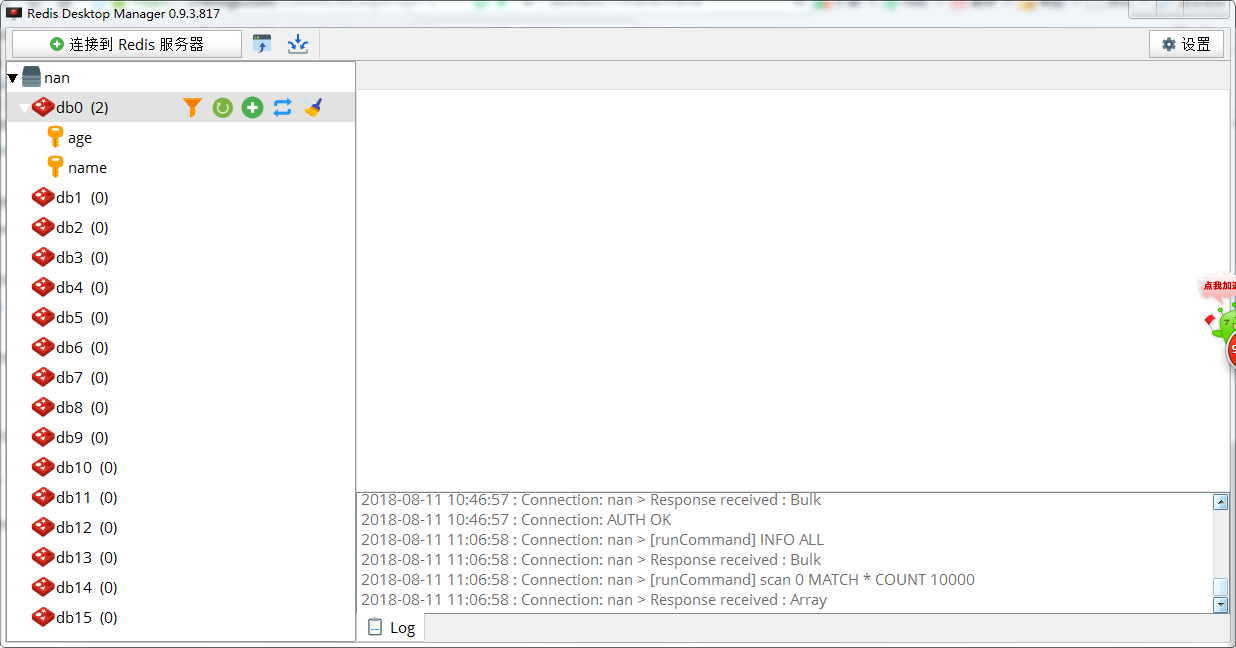
1)本地下载并安装RedisDesktopManager桌面管理工具
2)RedisDesktopManager连接redis-server需要提供密码验证,在Ubuntu Redis中的配置文件中修改下列数据:
文件地址:/etc/redis/redis.conf , 打开redis.conf文件:vim redis.conf
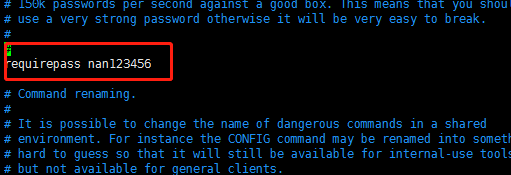
①、添加密码:找到密码位置,改成自定义密码 requirepass nan123456
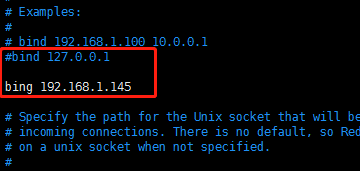
②、修改IP地址:将bing 127.0.0.1(本机地址)改成,bing 192.168.1.145(本机真实IP)
注: 网上说应改成 bing 0.0.0.0 ,由于调试时调用start、restart (目录:/etc/init.d 下执行)等指令总报错:Fatal error, can't open config file 'start' ,故未验证此方法,备注留以后处理。
3)使用RedisDesktopManager桌面管理工具连接Ubuntu中的Redis-server(前提先开启Redis服务端,虚拟机终端执行命令:redis-server)
打开RedisDesktopManager
连接到redis服务器
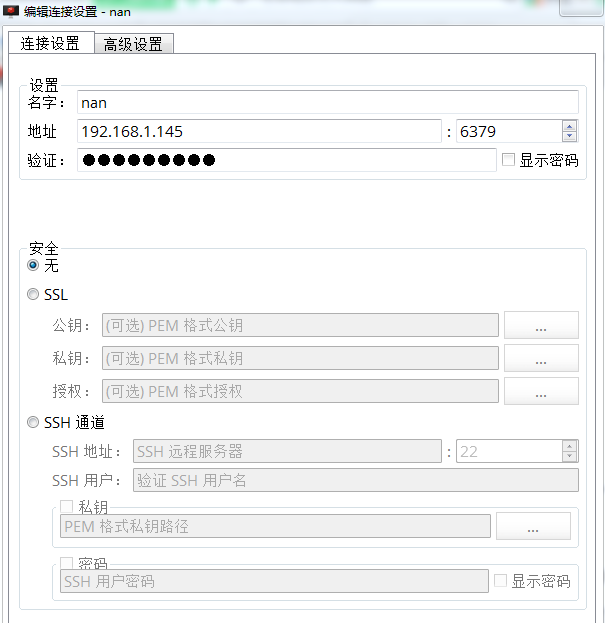
连接设置:填写名字、地址、端口、密码验证 (高级设置随喜好设置)
安全:因个人测试用,选无即可
4)此时,正常是已经连接到Ubuntu中的Redis服务器了,如连接不成功,可能是虚拟机防火墙搞鬼
测试:
打开window端的cmd调出终端,输入:telnet linux系统的ip 端口号,如 Telnet 192.168.1.145 6379,
如果提示telnet不是内部外部指令什么的,打开控制面板 → 程序和功能 → 打开或关闭Windows功能 → 启用Telnet客户端
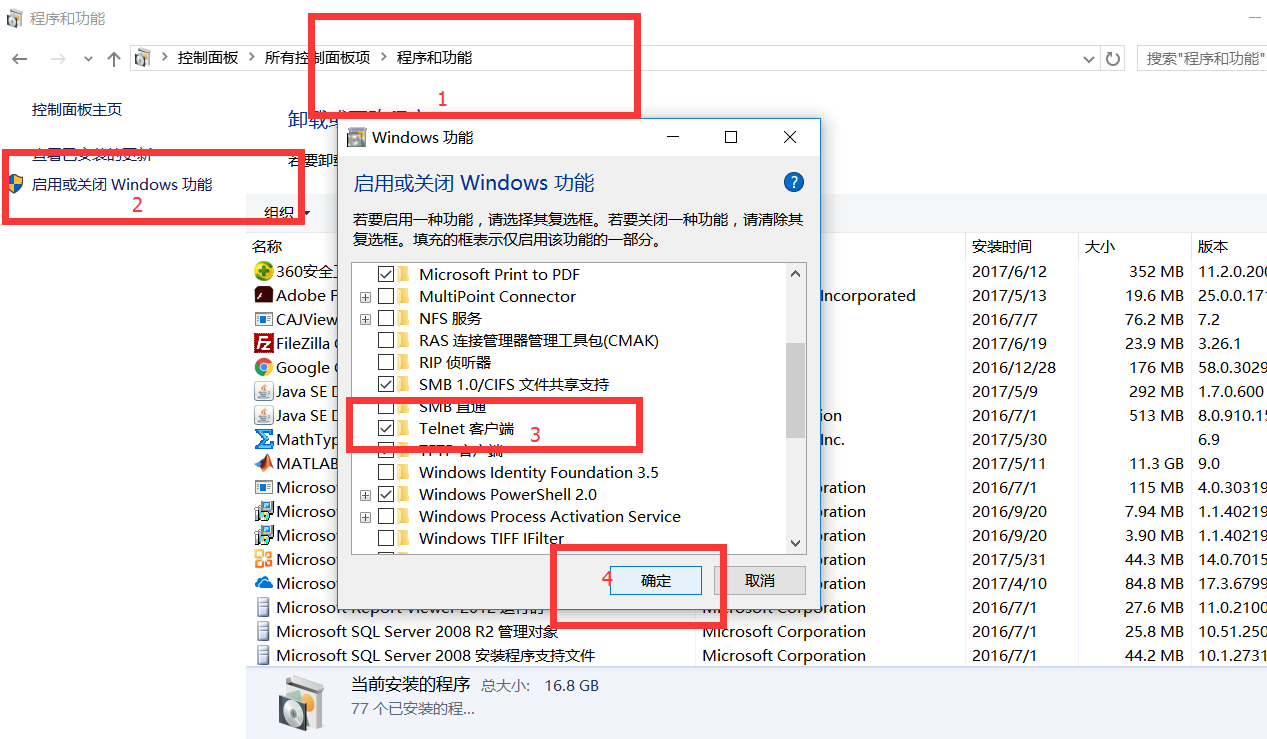
如果终端命令调试出现下述结果:

说明虚拟机防火墙搞鬼,未开发该端口,此时处理防火墙,开放该端口再测试就好了
如果终端命令调试,回车后出现一片漆黑,说明端口开放,不是虚拟机防火墙问题(此时可再试试RedisDesktopManager 连接Redis服务器)
Redis常用配置详解redis.conf:https://blog.csdn.net/yefenglala/article/details/71404234
二、缓存数据库介绍
NoSQL(NoSQL = Not Only SQL ),意即“不仅仅是SQL”,泛指非关系型的数据库,随着互联网web2.0网站的兴起,传统的关系数据库在应付web2.0网站,特别是超大规模和高并发的SNS类型的web2.0纯动态网站已经显得力不从心,暴露了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。NoSQL数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,尤其是大数据应用难题。
NoSQL数据库的四大分类
NoSQL数据库的四大分类表格分析
三、Redis
介绍
redis是业界主流的key-value nosql 数据库之一。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
Redis优点
-
异常快速 : Redis是非常快的,每秒可以执行大约110000设置操作,81000个/每秒的读取操作。
-
支持丰富的数据类型 : Redis支持最大多数开发人员已经知道如列表,集合,可排序集合,哈希等数据类型。
这使得在应用中很容易解决的各种问题,因为我们知道哪些问题处理使用哪种数据类型更好解决。 -
操作都是原子的 : 所有 Redis 的操作都是原子,从而确保当两个客户同时访问 Redis 服务器得到的是更新后的值(最新值)。
-
MultiUtility工具:Redis是一个多功能实用工具,可以在很多如:缓存,消息传递队列中使用(Redis原生支持发布/订阅),在应用程序中,如:Web应用程序会话,网站页面点击数等任何短暂的数据;
Ubuntu安装redis环境,终端输入指令:
$sudo apt-get update
$sudo apt-get install redis-server
启动redis服务:
$redis-server
客户端连接:
$redis-cli
redis 127.0.0.1:6379>
redis 127.0.0.1:6379> ping PONG
sudo service redis-server start #启动 sudo service redis-server restart #重启 sudo service redis-server stop #停止/关掉redis服务 #此时客户端连接redis服务端,不再是简单的:redis-cli,而是: redis-cli -h localhost -p port -a password #例: redis-cli -h 192.168.1.145 -p 6379 -a password


sudo pip install redis or sudo easy_install redis or 源码安装 详见:https://github.com/WoLpH/redis-py
在Ubuntu上安装Redis桌面管理器
要在Ubuntu 上安装 Redis桌面管理,可以从 http://redisdesktop.com/download 下载包并安装它。
Redis API使用
redis-py 的API的使用可以分类为:
- 连接方式
- 连接池
- 操作
- String 操作
- Hash 操作
- List 操作
- Set 操作
- Sort Set 操作
- 管道
- 发布订阅
** 计算网站UV实例
关于PV,UV,VV,IP,具体也可以参考博客:http://playkid.blog.163.com/blog/static/56287260201361951919690/
PV(page view)即页面浏览量或点击量,是衡量一个网站或网页用户访问量。具体的说,PV值就是所有访问者在24小时(0点到24点)内看了某个网站多少个页面或某个网页多少次。PV是指页面刷新的次数,每一次页面刷新,就算做一次PV流量。
UV(unique visitor)即独立访客数,指访问某个站点或点击某个网页的不同IP地址的人数。在同一天内,UV只记录第一次进入网站的具有独立IP的访问者,在同一天内再次访问该网站则不计数。
VV(Visit View),即访客的访问次数 记录所有访客1天内访问了多少次您的网站
IP可以理解为独立IP的访问用户,指1天内使用不同IP地址的用户访问网站的数量,同一IP无论访问了几个页面,独立IP数均为1。
** setbit巨流弊的应用场景
比如:当前第500位用户在线,则将第500个bit置为1(默认为0)。bitcount统计二级制位中1的个数,setbit和bitcount配合使用,轻松解决当前在线用户数的问题。1字节=8位,那么10m=8000万位,即一个亿的在线用户也就10m多的内存就可搞定,这优化不得了,可以省很多空间!
import redis #建立连接 pool = redis.ConnectionPool(host='192.168.1.145', port=6379,db=0,password='nan123456') r = redis.Redis(connection_pool=pool) r.setbit("uv_count1", 5,1) #每来一个客户(连接),将该位字节位设为1,例第5位访客 r.setbit("uv_count1", 8,1) r.setbit("uv_count1", 3,1) r.setbit("uv_count1", 3,1) # 重复的不计算 print("uv_count:", r.bitcount("uv_count1")) # 查看共有多少访客访问 #输出:uv_count: 3
1、连接方式
redis-py提供两个类Redis和StrictRedis用于实现Redis的命令,StrictRedis用于实现大部分官方的命令,并使用官方的语法和命令,Redis是StrictRedis的子类,用于向后兼容旧版本的redis-py。
import redis r = redis.Redis(host='192.168.1.145', port=6379, db=0 , password='nan123456') r.set('foo', 'Bar') print r.get('foo')
2、连接池
redis-py使用connection pool来管理对一个redis server的所有连接,避免每次建立、释放连接的开销。默认,每个Redis实例都会维护一个自己的连接池。可以直接建立一个连接池,然后作为参数Redis,这样就可以实现多个Redis实例共享一个连接池。
3、常用操作
1 # Redis终端操作redis数据,以空格区分,不需要加括号,例:删除多个数据 2 # python中:delete(name,age,sex) 3 # redis终端:delete name age sex 4 5 #例:设置名字 6 # python中:set('name', 'nan') 7 # redis终端:set name nan 8 9 10 11 12 delete(*names) # 根据删除redis中的任意数据类型 13 14 exists(name) # 检测redis的name是否存在 15 16 keys(pattern='*') # 根据模型获取redis的name 17 # 更多: 18 # KEYS * 匹配数据库中所有 key 。 19 # KEYS h?llo 匹配 hello , hallo 和 hxllo 等。 20 # KEYS h*llo 匹配 hllo 和 heeeeello 等。 21 # KEYS h[ae]llo 匹配 hello 和 hallo ,但不匹配 hillo 22 23 expire(name ,time) # 为某个redis的某个name设置超时时间 24 25 rename(src, dst) # 对redis的name重命名为 26 27 move(name, db)) # 将redis的某个值移动到指定的db下 28 29 select db # 切换redis数据库,总共16个,从0算起 30 31 randomkey() # 随机获取一个redis的name(不删除) 32 33 type(name) # 获取name对应值的类型 34 35 scan(cursor=0, match=None, count=None) 36 scan_iter(match=None, count=None) # 同字符串操作,用于增量迭代获取key
4、redis服务器命令
# quit:退出连接 # dbsize:返回当前数据库key总数 # info:获取服务器的信息 # config get:获取服务器配置信息 # flushdb:删除当前数据库中所有的key #flushall:删除所有数据库中所有的key
5、python中 redis 管道
redis-py默认在执行每次请求都会创建(连接池申请连接)和断开(归还连接池)一次连接操作,如果想要在一次请求中指定多个命令,则可以使用pipline实现一次请求指定多个命令,并且默认情况下一次pipline 是原子性操作。
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 4 import redis 5 6 pool = redis.ConnectionPool(host='192.168.1.145', port=6379,db=0,password='nan123456') 7 8 r = redis.Redis(connection_pool=pool) 9 10 # pipe = r.pipeline(transaction=False) 11 pipe = r.pipeline(transaction=True) # 类似事务,要么全成功,要么全失败 12 13 pipe.set('name', 'alex') 14 pipe.set('role', 'sb') 15 16 pipe.execute()
6、发布订阅

发布者:服务器
订阅者:Dashboad和数据处理
SUBSCRIBE 、 UNSUBSCRIBE 和 PUBLISH 三个命令实现了发布与订阅信息泛型(Publish/Subscribe messaging paradigm), 在这个实现中, 发送者(发送信息的客户端)不是将信息直接发送给特定的接收者(接收信息的客户端), 而是将信息发送给频道(channel), 然后由频道将信息转发给所有对这个频道感兴趣的订阅者。
发送者无须知道任何关于订阅者的信息, 而订阅者也无须知道是那个客户端给它发送信息, 它只要关注自己感兴趣的频道即可。
1)订阅频道
# 发布频道 redis>PUBLISH second Hello #PUBLISH :发布;second :频道 ;Hello :内容 # 订阅频道 redis> SUBSCRIBE first second # 订阅first频道跟second频道 #订阅后会接收到下列消息(成功订阅first、second频道): 1) "subscribe" 2) "first" 3) (integer) 1 1) "subscribe" 2) "second" 3) (integer) 2 #取消订阅频道 redis> UNSUBSCRIBE # 取消订阅的所有频道 #此时会接收到取消订阅的消息: 1) "unsubscribe" 2) "second" 3) (integer) 1 1) "unsubscribe" 2) "first" 3) (integer) 0 #当发布方发布消息时,订阅该频道的会接收到消息: redis> PUBLISH second Hello # 发布 #订阅方接收到的消息: 1) "message" 2) "second" 3) "hello" # 注:消息格式:message:表示是发布方发的真正消息 ;second:信息来源频道 ;hello:消息内容
2)订阅模式
Redis 的发布与订阅实现支持模式匹配(pattern matching): 客户端可以订阅一个带 * 号的模式, 如果某个/某些频道的名字和这个模式匹配, 那么当有信息发送给这个/这些频道的时候, 客户端也会收到这个/这些频道的信息。
比如执行命令:
redis> PSUBSCRIBE news.*
相关客户端将收到来自 news.art.figurative 、 news.music.jazz 等频道的信息。 客户端订阅的模式里面可以包含多个 glob 风格的通配符, 比如 * 、 ? 和 [...] , 等等
执行命令:
redis> PUNSUBSCRIBE news.*
将退订 news.* 模式, 其他已订阅的模式不会被影响。
通过订阅模式接收到的信息, 和通过订阅频道接收到的信息, 这两者的格式不太一样:
- 通过订阅模式而接收到的信息的类型为
pmessage: 这代表有某个客户端通过 PUBLISH 向某个频道发送了信息, 而这个频道刚好匹配了当前客户端所订阅的某个模式。 信息的第二个元素记录了被匹配的模式, 第三个元素记录了被匹配的频道的名字, 最后一个元素则记录了信息的实际内容。
客户端处理 PSUBSCRIBE 和 PUNSUBSCRIBE 返回值的方式, 和客户端处理 SUBSCRIBE 和 UNSUBSCRIBE 的方式类似: 通过对信息的第一个元素进行分析, 客户端可以判断接收到的信息是一个真正的信息, 还是 PSUBSCRIBE 或 PUNSUBSCRIBE 命令的返回值。
Demo如下:
import redis class RedisHelper: def __init__(self): self.__conn = redis.Redis(host='192.168.1.145',port=6379,db=0,password='nan123456') self.chan_sub = 'fm104.5' # 订阅频道 self.chan_pub = 'fm104.5' # 发布频道 def public(self, msg): self.__conn.publish(self.chan_pub, msg) #发布消息 return True def subscribe(self): pub = self.__conn.pubsub() #生成订阅实例,类似打开收音机 pub.subscribe(self.chan_sub) #调节到相应频道 pub.parse_response() #准备收听,未阻塞,再次调用时阻塞 return pub
订阅者:
from redis_helper import RedisHelper obj=RedisHelper() redis_sub=obj.subscribe() #返回实例 while True: msg=redis_sub.parse_response() #听 print(msg) #有消息则打印,无消息则阻塞
发布者:
#!/usr/bin/env python # -*- coding:utf-8 -*- from monitor.RedisHelper import RedisHelper obj = RedisHelper() obj.public('hello')
7、操作
1)string操作
redis中的String在在内存中按照一个name对应一个value来存储。如图:
set(name, value, ex=None, px=None, nx=False, xx=False)
在Redis中设置值,默认,不存在则创建,存在则修改
参数:
ex,过期时间(秒)
px,过期时间(毫秒)
nx,如果设置为True,则只有name不存在时,当前set操作才执行
xx,如果设置为True,则只有name存在时,岗前set操作才执行
setnx(name, value)
设置值,只有name不存在时,执行设置操作(添加)
setex(name, value, time)
# 设置值 # 参数: # time,过期时间(数字秒 或 timedelta对象)
psetex(name, time_ms, value)
# 设置值 # 参数: # time_ms,过期时间(数字毫秒 或 timedelta对象)
mset(*args, **kwargs)
# 批量设置值 如: mset(k1='v1', k2='v2') 或 mget({'k1': 'v1', 'k2': 'v2'})
get(name) #获取值
mget(keys, *args)
# 批量获取 如: mget('ylr', 'wupeiqi') 或 r.mget(['ylr', 'wupeiqi'])
getset(name, value)
# 设置新值并获取原来的值
getrange(key, start, end)
# 获取子序列(根据字节获取,非字符) # 参数: # name,Redis 的 name # start,起始位置(字节) # end,结束位置(字节) # 如: "武沛齐" ,0-3表示 "武"
未完待续...
Redis 持久化
Redis 提供了多种不同级别的持久化方式:
- RDB 持久化可以在指定的时间间隔内生成数据集的时间点快照(point-in-time snapshot)。
- AOF 持久化记录服务器执行的所有写操作命令,并在服务器启动时,通过重新执行这些命令来还原数据集。 AOF 文件中的命令全部以 Redis 协议的格式来保存,新命令会被追加到文件的末尾。 Redis 还可以在后台对 AOF 文件进行重写(rewrite),使得 AOF 文件的体积不会超出保存数据集状态所需的实际大小。
- Redis 还可以同时使用 AOF 持久化和 RDB 持久化。 在这种情况下, 当 Redis 重启时, 它会优先使用 AOF 文件来还原数据集, 因为 AOF 文件保存的数据集通常比 RDB 文件所保存的数据集更完整。
- 你甚至可以关闭持久化功能,让数据只在服务器运行时存在。
相关资料:https://blog.csdn.net/qidong7/article/details/52201353
Redis事务
有时候为了同时处理多个结构,我们需要向Redis发送多个命令。尽管Redis有几个可以在两个键之间复制或者移动元素的命令,却没有可以在不同类型之间移动元素的命令。
Redis有5个命令可以让用户在不被打断的情况下对多个键进行操作:
WATCH、MULTI、EXEC、UNWATCH、DISCARD
1)事务、悲观锁、乐观锁
事务:简单的说,事务就是为了存取数据库中同一数据时不破坏操作的隔离性和原子性,从而保证数据的一致性。一般数据库,比如MySql是如何保证数据一致性的呢,主要是加锁,悲观锁。比如在访问数据库某条数据的时候,会用SELECT FOR UPDATE ,这MySql就会对这条数据进行加锁,直到事务被提交(COMMIT),或者回滚(ROLLBACK)
悲观锁:当数据正被操作(加锁),此时其他事务对被加锁的数据进行写入,那么此事务将会被阻塞,直到第一个事务完成为止。它的缺点在于:持有锁的事务运行越慢,等待解锁的事务阻塞时间就越长。并且容易产生死锁
乐观锁:当数据正被操作,此时其他事务对被加锁的数据进行写入会正常进行,在commit时如果数据与原始数据不一致(有别的客户同时在操作并提交更改了数据)则会报错返回给客户。即客户端永远都不会等待第一个取得锁的客户端完成操作,他们只需要在自己的事务执行,如果失败再进行重试就可以了。
2)事务实例
通过MULTI开启一个事务,通过EXEC提交此事务,比如:
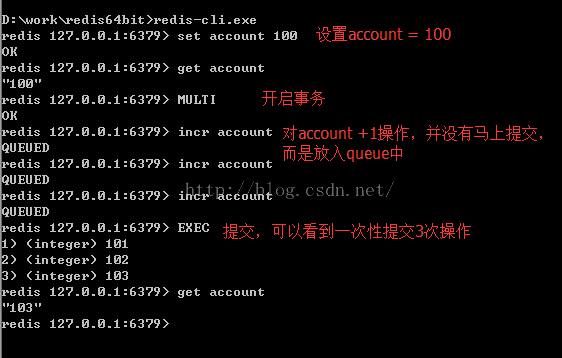
一次性提交的好处是,客户端与服务端不必要每条命令都交互(耗费传输时间);一次性提交可以节省资源,提高效率!
所以客户端,比如python通过 conn.pipline() 开启一个通道,操作命令就像流水线一样,最后一次性完成提交,从而提高执行效率,节约资源,减少服务器压力。称之为流水线操作!
3)WATCH命令实现乐观锁
比如,通过WATCH监控,对一条数据开启事务操作时,先获取一个版本号,当事务提交的时候用此版本号与最新的版本号进行比对,如果版本号不一致,那么就返回给客户端,由客户端决定如何操作。(通过版本号实现乐观锁的原理)
当有一个事务在操作一条数据(资源)的时候,为了避免其他事务也来操作此数据,导致脏数据。在第一个事务中对此数据执行WATCH(监控),监控过程中能发现数据在操作过程中有没有别其他客户端修改,这样通过乐观锁来保证数据的一致性。
客户端1:

客户端2:
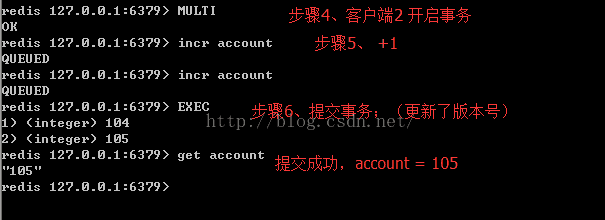
4)关于性能的注意事项
redis自带性能测试程序 redis-benchmark 命令。在不给定任何参数的情况下,redis-benchmark将使用50个客户端进行性能测试。
我们可以让程序在只使用一个客户端进行测试
redis-benchmark -c 1 -q
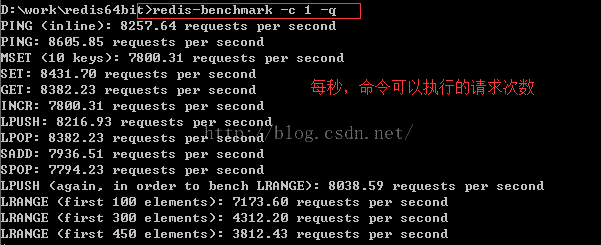
在一般情况下,对于只使用单个客户端的redis-benchmark来说,根据被调用命令的复杂度,一个不使用流水线的客户端的性能大概只有redis-benchmark所示性能的50%~60%;
所以,为了提高redis性能,客户端尽量通过连接池分配连接,并使用流水线事务进行操作;
(补)安装:
1、Ubuntu下安装:
1)安装:sudo apt-get install redis-server
2)卸载:sudo apt-get purge --auto-remove redis-server
3)启动:redis安装后,默认会自动启动。可通过ps查看redis对应进程:ps aux|grep redis
启动命令:sudo service redis-server start
4)停止:sudo service redis-server stop
2、Windows下安装:
1)redis官方是不支持Windows操作系统的,但是微软的开源部分将redis移植到了Windows。在GitHub中找到redis下载:https://github.com/MicrosoftArchive/redis/releases ,下载完成后再Windows下进行安装(运行后一步步点直接安装就可以了)

2)redis安装完成后,进入redis安装所在的路径,然后执行命令:redis-server.exe redis.windows.conf
意思是使用redis.windows.conf这配置文件的信息,启动redis服务
3)连接:redis连接和mysql连接时差不多的,都提供了一个客户端进行连接。输入命令redis-cli(前提先将redis执行路径添加到环境变量中),这样就可以连接上redis了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号