

一、python数据分析与挖掘技术基础
1、相关模块简介

2、相关模块安装

安装建议:1.安装到python中 ; 2.在每个项目的虚拟环境中安装
1)numpy安装:
pip install -i https://pypi.douban.com/simple numpy
2)pandas安装:
pip install -i https://pypi.douban.com/simple pandas
3)Matplotlib安装:
pip install -i https://pypi.douban.com/simple matplotlib
4)scipy安装:
pip install -i https://pypi.douban.com/simple scipy
5)statsmodels安装:
pip install -i https://pypi.douban.com/simple statsmodels
6)gensim安装:
pip install -i https://pypi.douban.com/simple gensim
7)wordcloud安装:
pip install -i https://pypi.douban.com/simple wordcloud
8)jieba安装:
pip install -i https://pypi.douban.com/simple jieba
9)pyecharts安装:
pip install -i https://pypi.douban.com/simple pyecharts
pip install -i https://pypi.douban.com/simple pyecharts_snapshot
3、相关模块的基本使用
1)numpy模块


import numpy as np # 1、np 数组的生成 a = np.array([[1,3,5],[2,4,6],[3,6,9]]) # 生成3维数组 a1 = np.arange(15) # 生成一维数组,数值为0-14 a = np.zeros(10) # 一维数组,10个0 a = np.zeros(3,6) # 二维数组,3*6 个0 a = np.ones(10) # 一维数组,10个1 a.shape # 打印a的形状(一维或是二维数组等) # 2、数组的维度变化 a = np.arange(24).reshape((2,3,4)) # 将24个元素生成一个三维数组 a.reshape((3,8)) # 不改变数组a元素,新生成一个3*8的二维数组 a.resize((3,8)) # 不改变原数组a的元素,但会改变原数组a的形状,变为3*8的二维数组 a.flatten() # 对数组进行降维,返回折叠后的一维数组,原数组不变 # 3.数组的索引和切片 # 一维数组的索引与切片 a[2] # 获取数组第三个元素 a2 = a1[1:4:2] # 获取数组1-3的元素,切步长为2 # 多维数组的索引与切片 """ [[[ 0 1 2 3] [ 4 5 6 7] [ 8 9 10 11]] [[12 13 14 15] [16 17 18 19] [20 21 22 23]]] """ a[1][2][3] # 数值为:23 a[1,2,3] # 数组为:23 a[:,:,::2] # 第一维度的所有,第二维度的所有,第三维度的所有但步长为2 # NumPy的ndarray 数组和标量之间的运算 # 数组乘法/减法,对应元素相乘/相减。 arr = np.array([[1.0, 2.0, 3.0], [4., 5., 6.]]) print (arr * arr) # 不需要做循环,相当于对应元素进行平方处理 print (arr - arr) # 标量操作作用在数组的每个元素上 arr = np.array([[1.0, 2.0, 3.0], [4., 5., 6.]]) print (1 / arr) print (arr ** 0.5) # 开根号 # 数组运算 np.abs(a) # 绝对值 np.fabs(a) # 绝对值 np.sqrt(a) # 平方根 np.square(a) # 平方 np.log10(a) # 10底对数 np.maximum(a1,a2) # 两个元素对应对比最大值,返回一个新的数组 np.minimum(a1,a2) # 两个元素对应对比最小值 np.fmax(a1,a2) # 元素最大值,同上 np.fmin(a1,a2) # 最小值,同上 np.max(a) # 单个元素,最大值 np.min(a) # 最小值 # >< >= <= == != :算术比较,产生的是布尔型数组 # numpy 数据的存取 # 1、存储到CSV文件,只适合一维跟二维数组存取 np.savetxt('a.csv',a ,fmt='%d',delimiter=',')# 存储,fmt:写入文件的格式,delimiter:分隔字符串,默认为任何空格 np.loadtxt('a.csv',dtype=np.int,delimiter=',')# 读取文件 # 2、多维数组存取 a.tofile("b.bat",sep=",",format='%d') #存储 sep:数据分割字符串,如果为空串,写入文件的为二进制格式 np.fromfile("b.bat",dtype=np.int,sep=",") # 读取 # 3、np的便捷文件存取 np.save("a,npy",a) # 扩展名为.npy np.savez("a.npz",a) # 扩展名为.npz np.load("a,npy") # 读取,扩展名如上 # np的统计函数 np.sum(a) # 和 np.mean(a) # 期望值 np.average(a) # 加权平均值 np.std(a) # 标准差 np.var() # 方差
2)Matplotlib模块
参考博文:https://www.cnblogs.com/Eric15/p/10029909.html
3)pandas模块
参考博文:https://www.cnblogs.com/Eric15/p/10035870.html
4、python数据导入方式

导入数据方式:
import pandas as pd # 1、导入csv文件 i = pd.read_csv("file_name.csv") i.describe() # 统计详细信息 i.sort_values(by = "colunm_name") # 将数据根据某列排列 # 2、导入.xls文件,需要安装xlrd模块 j = pd.read_excel("file_path.xls") # 3、导入mysql数据库的数据 ,首先→ 记得先安装mysqlclient import MySQLdb conn = MySQLdb.connect(host = "127.0.0.1",user = "root",passwd = "*******",db = "data_demo",charset = "utf8") # 连接数据库 sql = "select * from my_db_table" # 执行的语句 pd.read_sql(sql,conn) # 导入执行sql语句后的结果数据 # 4、导入html数据 ,可以直接从HTML网页中加载对应table表格中的数据,如果有中文,加上encoding='utf8' # 需要安装html5lib 、 beautifulsoup4 和 lxml模块 a = pd.read_html("file_path.html") a = pd.read_html(r"C:\Users\Administrator\Desktop\abc.html",encoding='utf8') # 读取本地HTML文件 a = pd.read_html("www.douban.com") # 读取网站线上HTML网页的table数据 # 5、导入文本数据 d = pd.read_table("file_path.text")
5、 可视化分析实现-->Matplotlib
博文参考:https://www.cnblogs.com/Eric15/p/10029909.html
1)折线图/散点图 -->plot
import matplotlib.pyplot as plt import numpy as np # 折线图/散点图:plot # a = np.arange(10).reshape(2,5) a = np.random.random_integers(1,20,10).reshape(2,5) # 随机生成10个数,介于1-20之间,再转成2*5的数组 plt.plot(a[0],a[1]) # plot(x轴数据,y轴数据,展现形式) 默认折线图 # plt.plot(a[0],a[1],'o') # 散点图 plt.title('你好',fontproperties='SimHei') # 标题 plt.xlabel('横轴',fontproperties='SimHei',fontsize=20) plt.ylabel('纵轴',fontproperties='SimHei',fontsize=20) plt.xlim(0,20) # 横轴的数值范围 plt.ylim(4,20) # 纵轴的数值范围 plt.show()
折线图: 散点图:
散点图: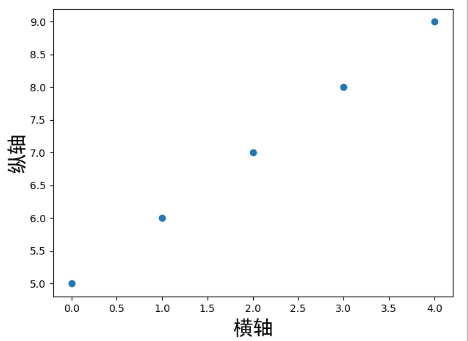
** 正态分布图:
s = np.random.normal(5.0,2.0,10) # 生成正态分布图 (均值,∑,个数) plt.plot(s)
plt.show()
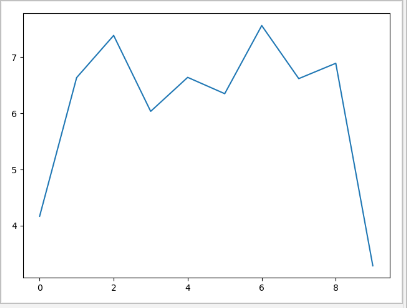
2)直方图
data = np.random.normal(10.0,1.0,200)
plt.hist(data) # hist(data,10) 10表示直方图数量
plt.show()
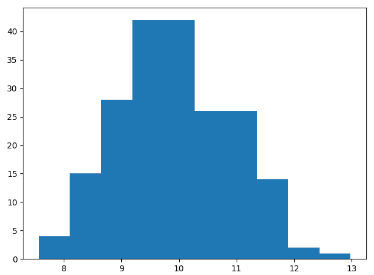
** 子区域
①、规则性子区域 subplot
plt.subplot(3,2,4) # plt.subplot(324) # 同上 plt.grid(True) # 网格 plt.show()
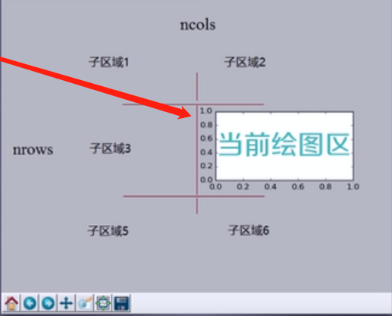
②、不规则性子区域 subplot2grid
plt.subplot2grid((3,3),(1,0),colspan=2) # 区域数:3 x 3,当前绘图区:(1,0)即第三个子区域,大小占两个格 plt.grid(True) # 网格 plt.show()
6、数据探索与数据清洗
1)概述

2)数据探索的核心

3)数据清洗

未来的你,会感谢现在努力的你!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号