

P3863 序列 题解
题目链接:序列
挺神仙的好题
关于时间维上的贡献处理,之前做过一些类似的题,这题是很不错的体现题。
对于一个数的查询来说,我们暴力地看看它的变化:

时间维有个很重要的特点,当前时间点的修改只会影响后续的所有时间点。对于某个时间点 \(i\),如果它的修改 \([l,r]+val\) 包括了 \(pos\) 当前讨论的点。那么翻译一下意思:
如图所示,每个时间点仅仅只会影响它的后续时间点,在后续时间点单点查询时,都会受到前面的修改影响。
引入一个好玩的东西
这里为了帮助你理解这类跟时间维上的贡献有关的题,我们引入一个新概念----时间数组,这个概念是我为了帮助读者理解这类知识点在本文中提出。
关于时间数组,个人给出定义:
类似常见的序列维作为轴即为常见的序列数组。数轴作为轴,即为所谓的权值数组,桶之类的称呼。这里我们以时间作为轴,即时间作为下标,那么它的值即为当前时间点处的值:
那么暴力的,对于每个数它的时间数组可以写成一个二维的表:
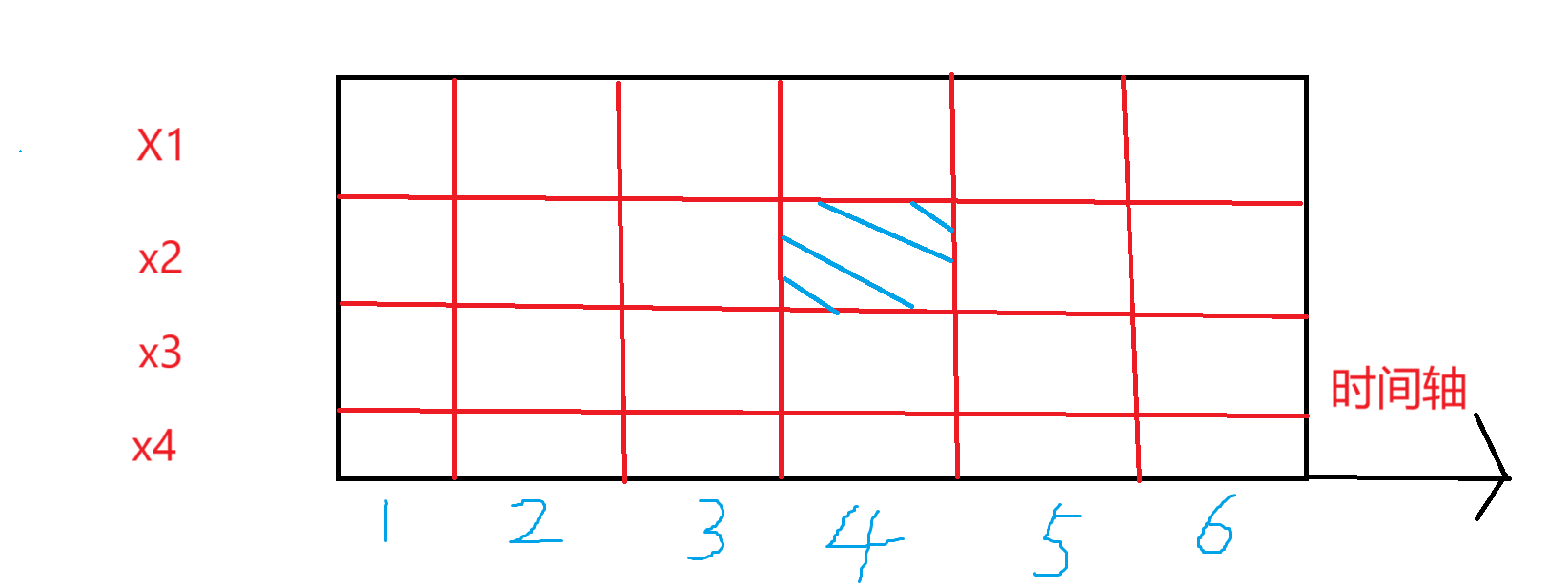
如图所示,每一行都表示一个元素的时间数组,比如蓝色块表示的含义即为:在 \(time=4\) 时刻时,\(x_2\) 的值。那么如果我们能维护这个时间表的变化,就能知道每个需要查的答案了。

我们将 \([x2,x3]\) 上的点在 \(i=4\) 这个时刻进行修改 \(+val\),如图所示,很显然,从 \(i=4\) 这个时刻到最后一个时刻都应该 \(+val\),这个显然是一个二维区域上的 \(+val\) 操作。查询,查什么?其实查什么咱都能查的。询问:
对于某个 \(x\),\(time<queryTime\ \&\&\ val\ge queryValue\) 的数量。
翻译成我们的时间数组:
查找 \(x\) 在时间表的所在行,即它所对应的时间数组下标小于 \(queryTime\),值大于等于 \(queryValue\) 的个数,这个是不是就很形象了。
先考虑直接暴力搞下怎么搞,二维树状数组/线段树维护区间加算法,查询外层对元素限制,内层对时间限制,然后再查权值,这岂不是:二维数据结构套权值树,一看就是三支 \(\log\) 空间也巨大。回忆下,这个问题本质是什么?权值计数类问题,也是经典可差性问题。
可差性问题普及
对于一类问题的答案我们是满足这样的式子:
这类问题我们称之为可差性问题。
回到题目
这玩意带修,而且这个修改不好拆分,但是这个修改仔细观察是一个怎样的问题:
直接做二维差分?当你看到 \(n=1e5,q=1e5\),就知道这个矩形大小为 \(1e10\),一定不怎么能直接二维去做,空间一定不够。这里安利一道题:P3960 [NOIP2017 提高组] 列队 题解。
这种二维问题,离线算法最经典,想想离线算法里面降维的神器:维度扫描线降维。
维度扫描线降维普及
给出一个简单的常见模型,\([l,r]\) 上查询 \(\le x\) 的个数,并且查询共 \(q\) 个,直接做显然树套树啊,由于不带修且可差性,主席树也可以的。这里讲讲怎么离线扫描线降维:
对于一个查询 \([l,r]\) 这是一个可差性问题:
这意味着一个询问我们可以拆成两个,且偏序限制从原来的三个变成了两个:
三个偏序分别为下标左右限制,值的限制,共三个限制。
两个偏序限制分别为下标的限制和值的限制,共两个限制。
所以一个常见的偏序条件限制,我们可以通过不断地可差性问题减少限制条件。两个偏序限制就是一个最纯粹的二维偏序问题,这类问题想必你一定不陌生,你在学习逆序对的时候有过这种类似写法。
对于 \(i \le idx\) 的这个限制是属于序列维度上的限制,对于 \(val \le x\),这个是属于值域维度上的限制,这是两个维度限制,比较暴力的做法就是直接二维数据结构做,讲讲离线扫描线怎么降维:
-
选择一个维度进行正确的行驶方向。
-
将另一个维度的查询挂载在这个维度的限制最大点上。
-
选择的维度开始更新,每次到一个点就进行挂载点的更新与询问回答。
实战:
方案1:
-
选择序列维作为我们的扫描线维,我们从下标 \(1\) 到 \(n\) 的方向走,因为询问的限制是 \(i \le idx\),所以我们应该从小往大更新。
-
如果一个查询的限制为 \(i\le idx\),那么我们将这个询问挂载在 \(i=idx\) 的点上,这样当我们从小到大更新到 \(i=idx\) 时,这个时候所以的满足这个限制的点都已经进入我们的维护当中。
-
从下标 \(1\) 开始更新与查询,我们选择权值树状数组或者权值线段树维护当前情况,我们每访问一个数,我们就加入到权值数据结构中,对于一个挂载查询,我们发现:它的第一个限制一定满足,我们只需要关注第二个值域限制,并且所有满足权值限制的数已经进入权值 ds 中,正确查询即可。
代码描述
constexpr int N = 1e5 + 10;
typedef pair<int, int> pii; //(val<=v,queryId)
vector<pii> seg[N];
int n;
int a[N];
void add(int x); //权值ds加入一个数
int query(int x); //权值dds查询<=x的数的个数
int ans[N];
inline void solve()
{
forn(i, 1, n)
{
add(a[i]);
for (const auto [val,queryId] : seg[i])ans[queryId] += query(val);
}
}
这样一来我们就完成了所有查询,当然可以根据实际需求增加更多参数,比如需要 \(-\) 之类的。我们发现降维是降了我们选择的序列维,序列维的限制没了,只有值域限制了。当然我们还有一种写法,不需要挂载,直接记录所有查询,按照查询下标进行排序即可。
代码描述
constexpr int N = 1e5 + 10;
typedef tuple<int, int, int> tii; //(queryIdx,val<=v,queryId)
vector<tii> seg;
int n;
int a[N];
void add(int x); //权值ds加入一个数
int query(int x); //权值ds查询<=x的数的个数
int ans[N];
inline void solve()
{
sort(seg.begin(), seg.end()); //按照查找的下标排序
int curr = 1;
forn(i, 1, n)
{
add(a[i]);
while (curr < seg.size())
{
auto [queryIdx,val,id] = seg[curr];
if (queryIdx > i)break;
ans[id] += query(val);
curr++;
}
}
}
是不是感觉有双指针的味道了,这个降维大大降低了空间维护和时间复杂度。
方案2:
考虑权值维作为扫描线轴,我们采用刚刚说的第二种,按照值域把原数组带着下标排序,即当前数组元素 \(a[1]\) 表示值为最小的元素的下标,可以不用离散化。我们按照值域从小到大加入下标贡献,然后令一维按照值域双指针限制,进行下标限制查询,完全与上述一致。
代码描述
constexpr int N = 1e5 + 10;
typedef tuple<int, int, int> tii; //(val,queryId,queryId)
vector<tii> seg;
int n;
pii a[N]; //(值,下标)
void add(int x); //权值ds加入一个数
int query(int x); //权值dds查询<=x的数的个数
int ans[N];
inline void solve()
{
sort(a + 1, a + n + 1); //按照值排序
sort(seg.begin(), seg.end()); //按照查找的值排序
int curr = 1;
forn(i, 1, n)
{
const auto [v,idx] = a[i];
add(idx); //加入下标贡献
while (curr < seg.size())
{
auto [val,queryIdx,id] = seg[curr];
if (val > v)break;
ans[id] += query(queryIdx); //查找下标限制
curr++;
}
}
}
这就是离线扫描线的降维思想,通过思想,我们可以很轻松地降维。
回到本题
查询几个维度?三个,对下标的限制,对时间的限制,对值域的限制。选哪个维?都差不多,我们选择最好写的序列维。序列维限制没了,剩个啥?时间维上的值域维查询。先写出原问题:
查询序列维 \(=idx\) 的时间维 \(<time\) 的值域维 \(\ge val\) 的数量。
降维后的问题,查询当前数据结构中,时间维 \(<time\),值域维 \(\ge val\) 的数量。
嚯,很简单吧。现在来处理最棘手的区间修改的影响。区间修改我们也翻译成:
对序列维在 \([l,r]\) 上且时间维为 \([time,lastTime]\) 的时间数组 \(+val\)。这咋做,这玩意可以差分,这是可差性问题,对于可差性问题的修改而言,我们常常考虑差分修改:
对 \(idx=l\) 做时间维的修改增加,对 \(idx=r+1\) 做时间维的修改减少:
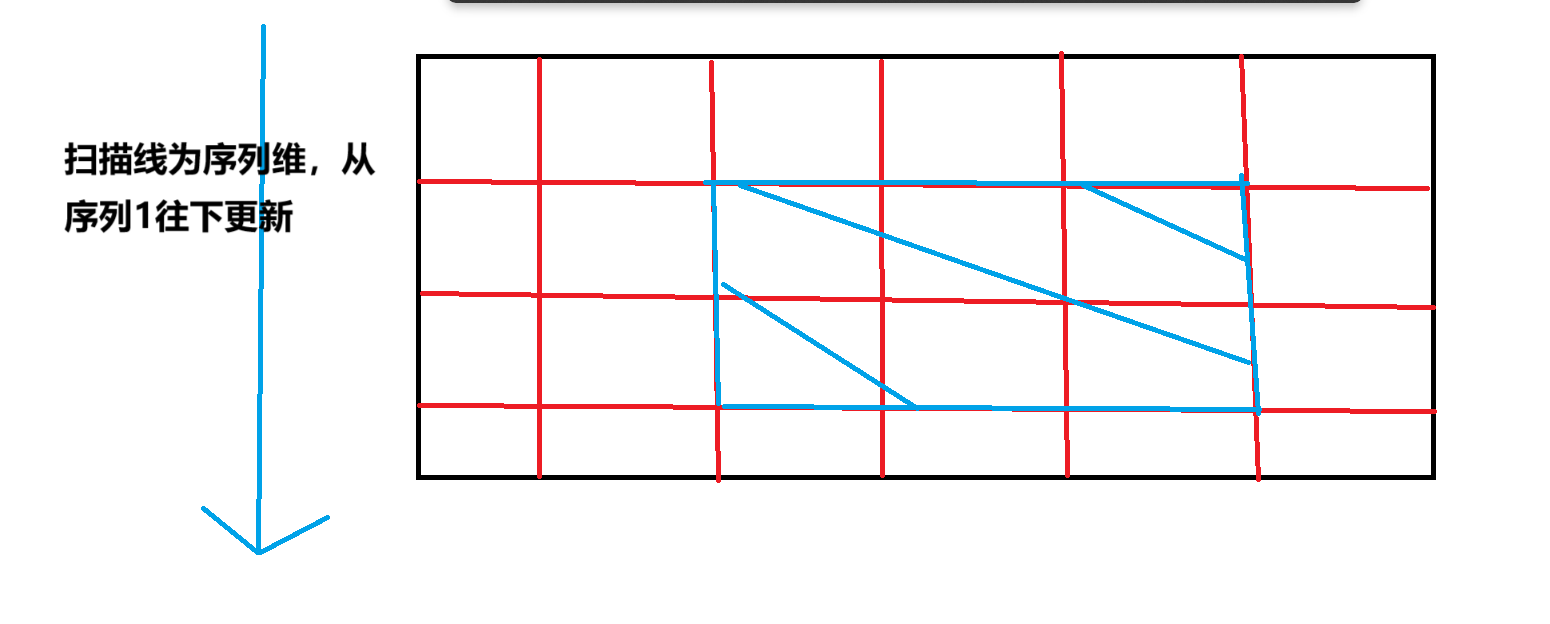
扫描线是序列维,我们从上往下更新,当前的数据结构即为 \(i=idx\) 这一时刻的时间数组信息,我们将原来的区改拆成了:两个序列时刻的变化,挂载在对应的序列点上就行。这样问题就变为了:
时间数组上的:
区间增加 \(+val\),区间查询 \([l,r]\) 上 \(\ge x\) 的数量。这个就是比较经典的分块入门题教主的魔法:每个块维护有序数组,然后逐块二分就行了,区改就维护一个标记永久化就行了。时间复杂度为。\(1e5\) 根号带 \(\log\) 跑满差不多 \(2e8\) 左右,\(2s\) 绰绰有余。
细节
查询是从 \(0\) 时刻开始,我们时间数组分块维护喜欢从 \(1\) 开始,可以整体时间点右移一位,减少查询常数的一些方式:
同时维护块的 \(max\) 和 \(min\) 来辅助查询跑不跑二分,减少重构常数可以使用布尔数组,当需要查询的时候再重构块。
参照代码
#include <bits/stdc++.h>
// #pragma GCC optimize(2)
// #pragma GCC optimize("Ofast,no-stack-protector,unroll-loops,fast-math")
// #pragma GCC target("sse,sse2,sse3,ssse3,sse4.1,sse4.2,avx,avx2,popcnt,tune=native")
#define isPbdsFile
#ifdef isPbdsFile
#include <bits/extc++.h>
#else
#include <ext/pb_ds/priority_queue.hpp>
#include <ext/pb_ds/hash_policy.hpp>
#include <ext/pb_ds/tree_policy.hpp>
#include <ext/pb_ds/trie_policy.hpp>
#include <ext/pb_ds/tag_and_trait.hpp>
#include <ext/pb_ds/hash_policy.hpp>
#include <ext/pb_ds/list_update_policy.hpp>
#include <ext/pb_ds/assoc_container.hpp>
#include <ext/pb_ds/exception.hpp>
#include <ext/rope>
#endif
using namespace std;
using namespace __gnu_cxx;
using namespace __gnu_pbds;
typedef long long ll;
typedef long double ld;
typedef pair<int, int> pii;
typedef pair<ll, ll> pll;
typedef tuple<int, int, int> tii;
typedef tuple<ll, ll, ll> tll;
typedef unsigned int ui;
typedef unsigned long long ull;
typedef __int128 i128;
#define hash1 unordered_map
#define hash2 gp_hash_table
#define hash3 cc_hash_table
#define stdHeap std::priority_queue
#define pbdsHeap __gnu_pbds::priority_queue
#define sortArr(a, n) sort(a+1,a+n+1)
#define all(v) v.begin(),v.end()
#define yes cout<<"YES"
#define no cout<<"NO"
#define Spider ios_base::sync_with_stdio(false);cin.tie(nullptr);cout.tie(nullptr);
#define MyFile freopen("..\\input.txt", "r", stdin),freopen("..\\output.txt", "w", stdout);
#define forn(i, a, b) for(int i = a; i <= b; i++)
#define forv(i, a, b) for(int i=a;i>=b;i--)
#define ls(x) (x<<1)
#define rs(x) (x<<1|1)
#define endl '\n'
//用于Miller-Rabin
[[maybe_unused]] static int Prime_Number[13] = {0, 2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37};
template <typename T>
int disc(T* a, int n)
{
return unique(a + 1, a + n + 1) - (a + 1);
}
template <typename T>
T lowBit(T x)
{
return x & -x;
}
template <typename T>
T Rand(T l, T r)
{
static mt19937 Rand(time(nullptr));
uniform_int_distribution<T> dis(l, r);
return dis(Rand);
}
template <typename T1, typename T2>
T1 modt(T1 a, T2 b)
{
return (a % b + b) % b;
}
template <typename T1, typename T2, typename T3>
T1 qPow(T1 a, T2 b, T3 c)
{
a %= c;
T1 ans = 1;
for (; b; b >>= 1, (a *= a) %= c)if (b & 1)(ans *= a) %= c;
return modt(ans, c);
}
template <typename T>
void read(T& x)
{
x = 0;
T sign = 1;
char ch = getchar();
while (!isdigit(ch))
{
if (ch == '-')sign = -1;
ch = getchar();
}
while (isdigit(ch))
{
x = (x << 3) + (x << 1) + (ch ^ 48);
ch = getchar();
}
x *= sign;
}
template <typename T, typename... U>
void read(T& x, U&... y)
{
read(x);
read(y...);
}
template <typename T>
void write(T x)
{
if (typeid(x) == typeid(char))return;
if (x < 0)x = -x, putchar('-');
if (x > 9)write(x / 10);
putchar(x % 10 ^ 48);
}
template <typename C, typename T, typename... U>
void write(C c, T x, U... y)
{
write(x), putchar(c);
write(c, y...);
}
template <typename T11, typename T22, typename T33>
struct T3
{
T11 one;
T22 tow;
T33 three;
bool operator<(const T3 other) const
{
if (one == other.one)
{
if (tow == other.tow)return three < other.three;
return tow < other.tow;
}
return one < other.one;
}
T3() { one = tow = three = 0; }
T3(T11 one, T22 tow, T33 three) : one(one), tow(tow), three(three)
{
}
};
template <typename T1, typename T2>
void uMax(T1& x, T2 y)
{
if (x < y)x = y;
}
template <typename T1, typename T2>
void uMin(T1& x, T2 y)
{
if (x > y)x = y;
}
constexpr int N = 1e5 + 10;
//块下标,块开始,块结束
int pos[N], s[N], e[N];
int n, q;
//原数组,时间数组,时间数组分块后每个块整体加的数量,每个块的有序数组
ll a[N], tim[N], tag[N], ord[N];
bool vis[N]; //减少常数,该块是否发生变化,需要重构
//重构有序块
inline void rebuild(const int id)
{
if (!vis[id])return;
forn(i, s[id], e[id])ord[i] = tim[i];
sort(ord + s[id], ord + e[id] + 1);
vis[id] = false;
}
//[l,r]+val
inline void add(const int l, const int r, const int val)
{
const int L = pos[l], R = pos[r];
if (L == R)
{
forn(i, l, r)tim[i] += val;
vis[L] = true;
return;
}
forn(i, l, e[L])tim[i] += val;
forn(i, s[R], r)tim[i] += val;
forn(i, L+1, R-1)tag[i] += val;
vis[L] = vis[R] = true;
}
//二分有序块>=val的个数,记得tag表示整个块+了多少,需要去掉
inline int binarySize(const int id, const int val)
{
rebuild(id);
const ll v = val - tag[id];
if (v > ord[e[id]])return 0;
return e[id] - (ranges::lower_bound(ord + s[id], ord + e[id] + 1, v) - ord) + 1;
}
//[l,r]>=val的数量
inline int query(const int l, const int r, const ll val)
{
if (l > r)return 0;
const int L = pos[l], R = pos[r];
int ans = 0;
if (L == R)
{
forn(i, l, r)ans += tim[i] >= val - tag[L];
return ans;
}
forn(i, l, e[L])ans += tim[i] >= val - tag[L];
forn(i, s[R], r)ans += tim[i] >= val - tag[R];
forn(i, L+1, R-1)ans += binarySize(i, val);
return ans;
}
//修改和查询分别挂载在序列扫描线上
vector<pii> segUpdate[N];
vector<tii> segQuery[N];
int ans[N];
int ansIdx;
inline void solve()
{
cin >> n >> q;
q++; //查询时间点右移从1开始
//时间数组分块
const int siz = sqrt(q);
const int cnt = (q + siz - 1) / siz;
forn(i, 1, n)cin >> a[i];
forn(i, 1, q)pos[i] = (i - 1) / siz + 1;
forn(i, 1, cnt)s[i] = (i - 1) * siz + 1, e[i] = i * siz;
e[cnt] = q;
//第一次修改时间点从2开始
forn(i, 2, q)
{
int op;
cin >> op;
if (op == 1)
{
int l, r, val;
cin >> l >> r >> val;
//差分挂载在序列扫描线上,[i,q]上时间数组修改
segUpdate[l].emplace_back(i, val);
segUpdate[r + 1].emplace_back(i, -val);
}
else
{
int pos, val;
cin >> pos >> val;
//查询挂载在序列扫描线上,<i <=> <=i-1,即查询[1,i-1]上<=val的数量
segQuery[pos].emplace_back(++ansIdx, i - 1, val);
}
}
forn(i, 1, n)
{
//当前数加入当前行所在时间数组
add(1, q, a[i]);
for (const auto [curr,val] : segUpdate[i])add(curr, q, val); //先修改
for (const auto [id,curr,val] : segQuery[i])ans[id] = query(1, curr, val); //再查询另外两个限制
add(1, q, -a[i]);
//当前数从当前行所在时间数组删除
}
forn(i, 1, ansIdx)cout << ans[i] << endl;
}
signed int main()
{
// MyFile
Spider
//------------------------------------------------------
// clock_t start = clock();
int test = 1;
// read(test);
// cin >> test;
forn(i, 1, test)solve();
// while (cin >> n, n)solve();
// while (cin >> test)solve();
// clock_t end = clock();
// cerr << "time = " << double(end - start) / CLOCKS_PER_SEC << "s" << endl;
}
最后的一个普及
常见的二维数点实用方法总结:
常见的模型:
求 \(x \le idx,l\le y \le r\) 的点的数量,其他模型都能通过可差性问题差分转变为这个模型。可差性问题:
\(ans(限制条件,l\le x \le r)=ans(限制条件,x \le r)-ans(限制条件,x\le l-1)\)
二维数点不带修,询问离线,将 \(x\) 序列扫描线转化 \(+\) 权值树状数组统计 \(y\) 贡献。
二维数点不带修,询问在线,主席树维护 \([0,x]\) 上关于 \(y\) 权值树。
二维数点带修,询问离线,将 \(time\) 作为第一序,\(x\) 作为第二序,cdq 分治算 \(y\) 的贡献。
二维数点带修,询问在线,树套树,对 \(x\) 为第一维,\(y\) 为第二维。
如果要带根号:
二维数点不带修,询问离线,序列扫描线转化 \(+\) 值域分块计数。
其他情况,序列分块套值域分块。当然也有 \(KD-Tree\)、多叉树、\(bitset\)、归并树等等的一些其他解法。
PS:离线扫描线还有诸多应用,它对可差性问题的离线是出奇的好用,比如著名的莫队二次离线算法,就是借助可差性问题的差分,将查询再次挂载在扫描线上去进行二次离线地更优查询。
