numpy与panda基础(持续更新)
In [ ]:
import numpy as np2.1.1 数组的创建¶
数组(ndarray)由实际数据和描述这些数据的元素组成,可以使用.shape查看数组的形状,使用.dim查看数组的维数。而向量(vector)即一维数组,也是最常用的数组之一。通过NumPy的函数创建一维向量与二维数组常用的方法如表2-1-1所示。数组可由列表构造,也可以通过*.tolist方法转换列表。
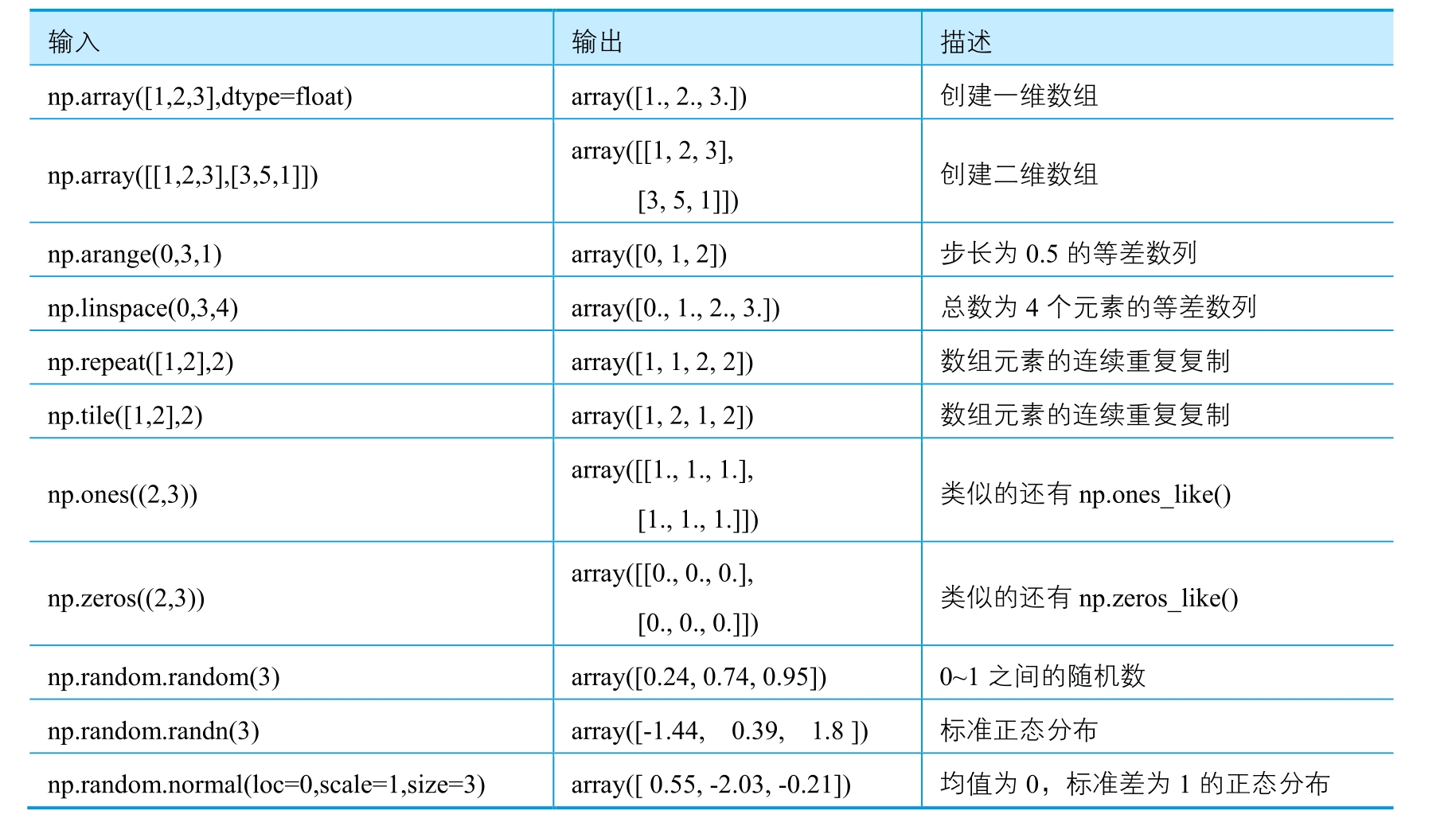
In [ ]:
# 创建一维数组
np.array([1,2,3],dtype=float)
# 创建二维数组
np.array([[1,2,3],[3,5,1]])
# 步长为0.5的等差数列
np.arange(0,3,1)
# 总数为4个元素的等差数列
np.linspace(0,3,4)
# 数组元素的连续重复复制
np.repeat([1,2],3)
# 数组元素的连续重复复制
np.tile([1,2],3)
np.ones((2,3))
np.zeros((2,3))
# 0~1之间的随机数
np.random.random(3)
# 标准正态分布
np.random.randn(3)
# 均值为0,标准差为1的正态分布
np.random.normal(loc=0,scale=1,size=3)Out[ ]:
array([-0.51657382, 0.42518206, -0.37705454])2.1.2 数组的索引与变换¶
In [ ]:
# ython数组的索引与切片使用中括号“[]”选定下标来实现,同时采用“:”分割起始位置与间隔,用“,”表示不同维度,用“…”表示遍历剩下的维度(见表2-1-2)。使用reshape()函数可以构造一个3行2列的二维数组:
a = np.arange(6).reshape(3,2)
print(a)
# 选取某一列
a[:,1]
# 选取多列
a[:,[0,1]]
# 选取某一行
a[1,:]
# 选取多行
a[[0,1],:]
# 选取某个元素
a[1,1]
# 单条件过滤 选择所有第二列大于2的行
a[a[:,1]>2,]
# 多条件过滤 选择所有第二列大于2且小于4的行
a[(a[:,1]>2)&(a[:,1]<4),]
# 数组维度改变
a.reshape(2,3)
# 数组的转置
a.T
np.transpose(a)
# 数组的平迭展开
a.flatten()
# 数组的平迭展开
a.ravel()[[0 1]
[2 3]
[4 5]]Out[ ]:
array([0, 1, 2, 3, 4, 5])数组的索引与变换 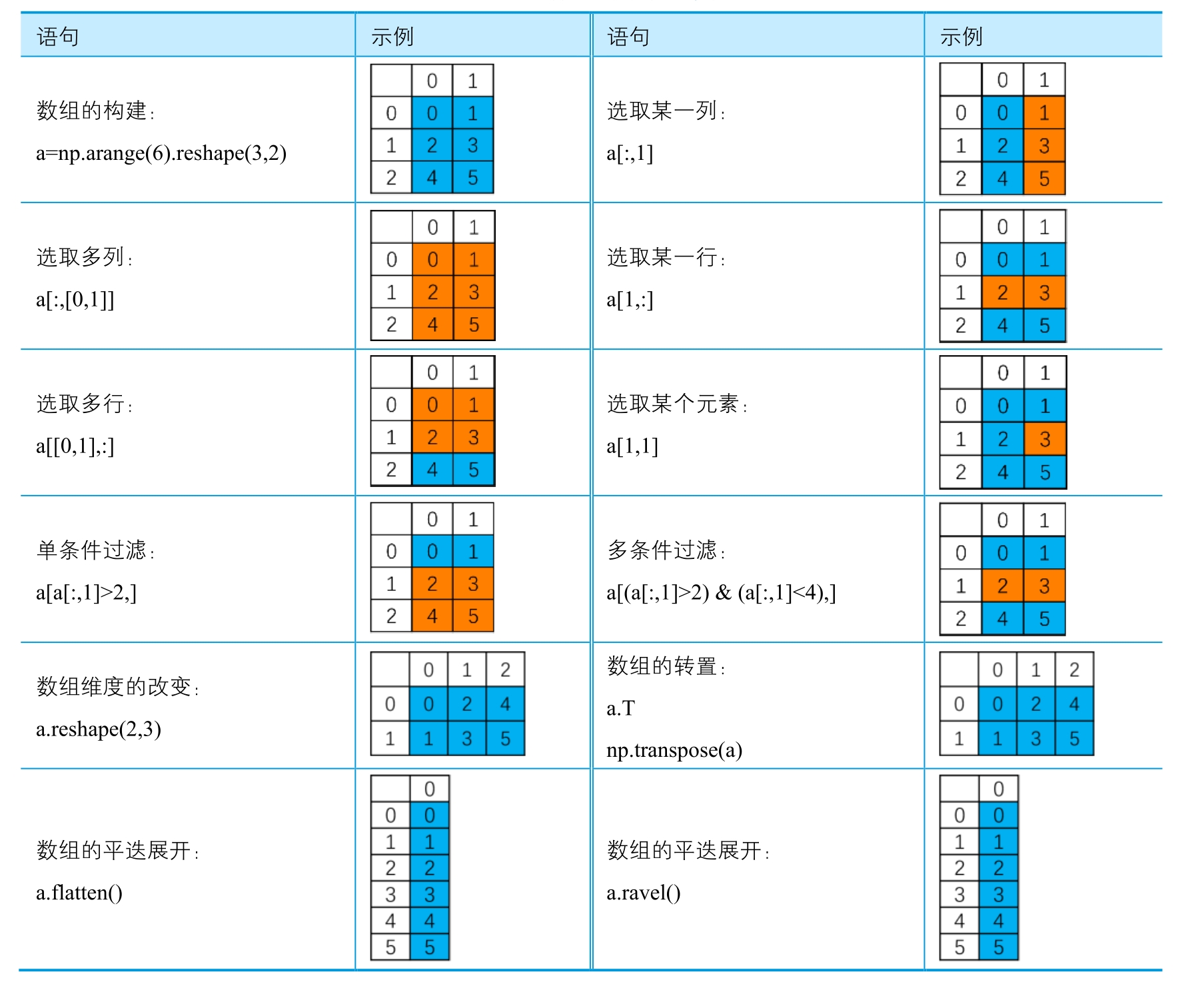 NumPy的ravel()和flatten()函数所要实现的功能是一致的,都是将多维数组降为一维数组。两者的区别在于返回拷贝(copy)还是返回视图(view),numpy.flatten()返回一份拷贝,对拷贝所做的修改不会影响原始矩阵,而numpy.ravel()返回的是视图,会影响原始矩阵。
NumPy的ravel()和flatten()函数所要实现的功能是一致的,都是将多维数组降为一维数组。两者的区别在于返回拷贝(copy)还是返回视图(view),numpy.flatten()返回一份拷贝,对拷贝所做的修改不会影响原始矩阵,而numpy.ravel()返回的是视图,会影响原始矩阵。
数组的排序也尤为重要。NumPy提供了多种排序函数,比如sort(直接返回排序后的数组)、argsot (返回数组排序后的下标)、lexsort(根据键值的字典序排序)、msort(沿着第一个轴排序)、sort_complex (对复数按照先实后虚的顺序排序)等。
In [ ]:
# 一维数组
a = np.array([3,2,5,4])
# 二维数组
b = np.array([[1,4,3],
[4,5,1],
[2,3,2]])
# 数组的排序
np.sort(a)
# a.sort()
# 数组排序后的下标
np.argsort(a)
# 数组的降序
np.sort(np.argsort(-a))
# axis=0表示按列排序 axis=1表示按行排序
b.sort(axis=1)
bOut[ ]:
array([[1, 3, 4],
[1, 4, 5],
[2, 2, 3]])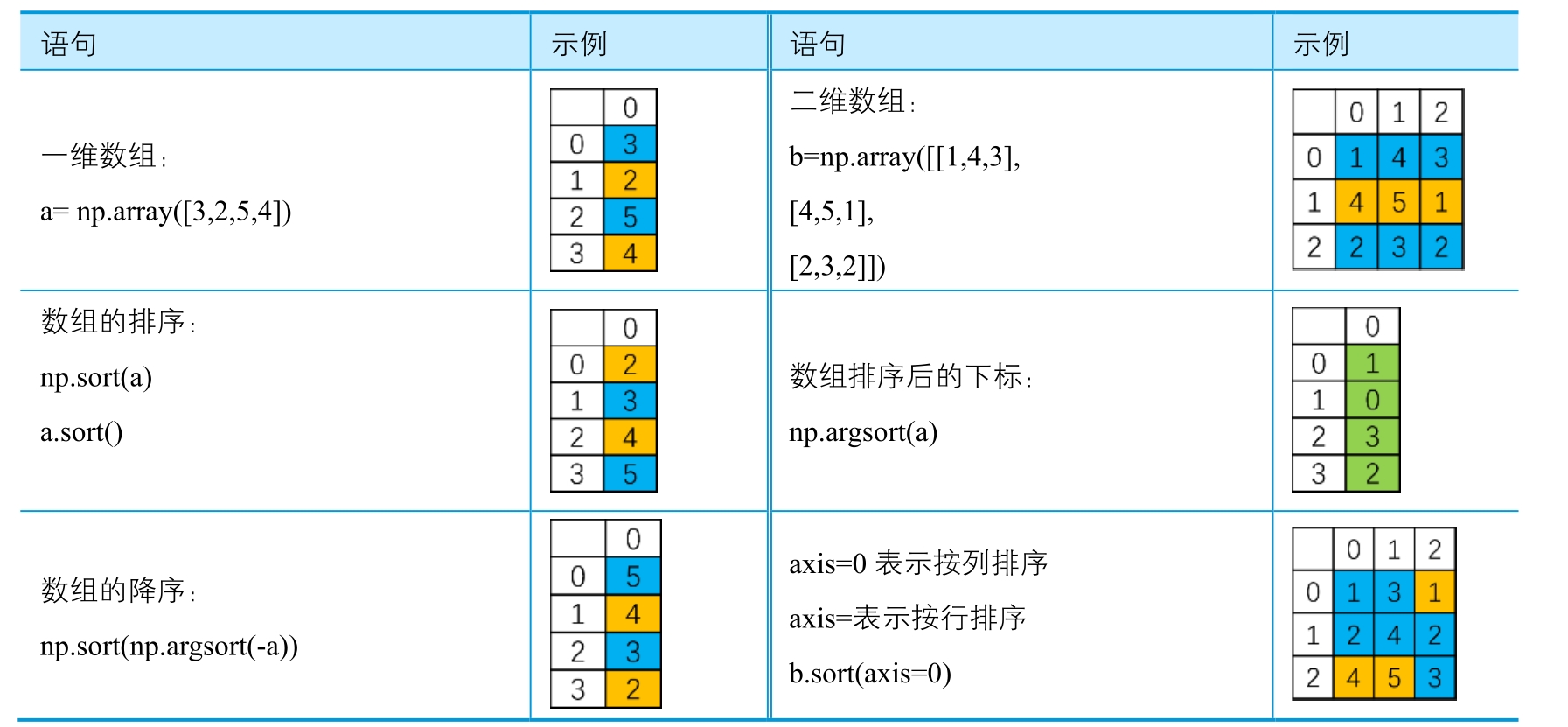
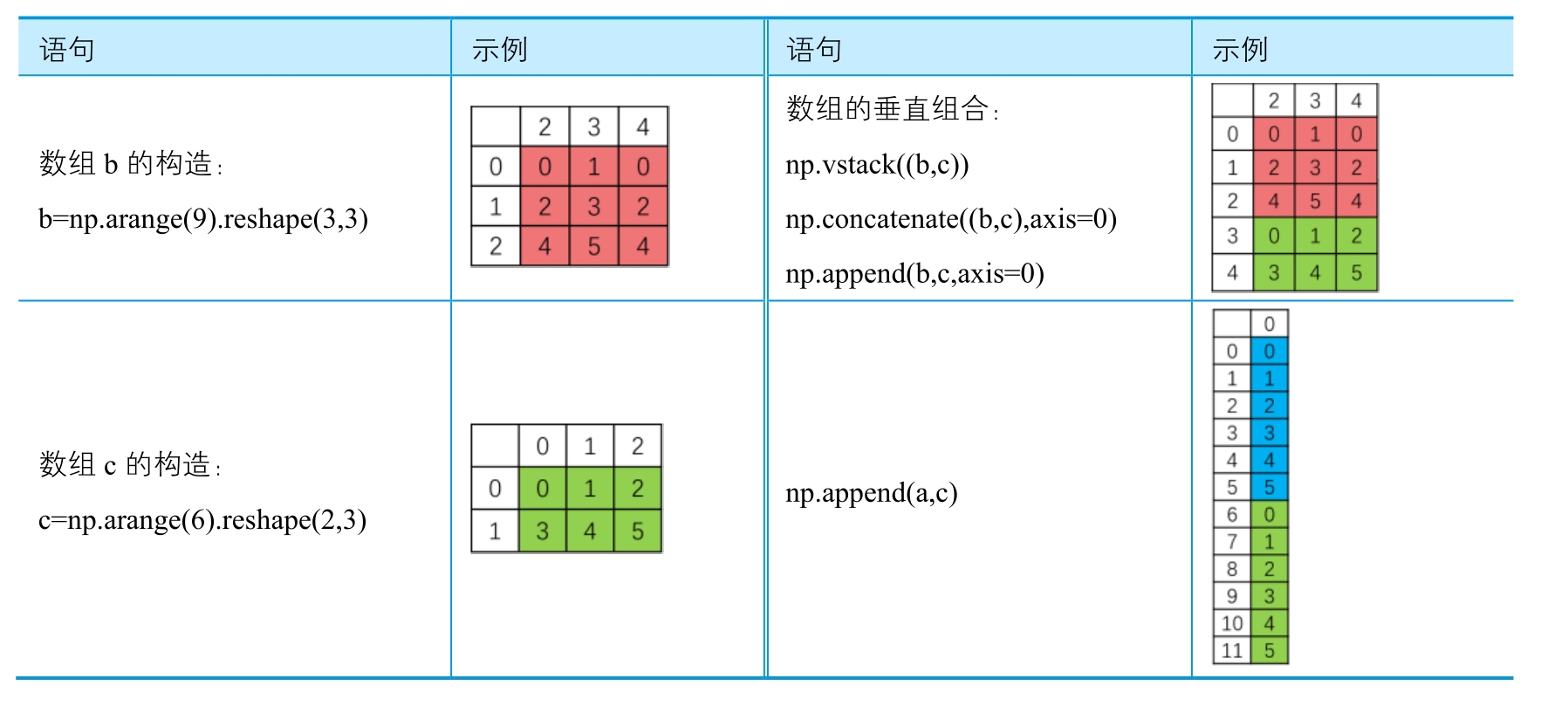
2.1.3 数组的组合¶
'''
NumPy数组的组合可以分为:水平组合(hstack)、垂直组合(vstack)、深度组合(dstack)、列组合(colume_stack)、行组合(row_stack)等。其中,水平组合就是把所有参加组合的数组拼接起来,各数组行数应该相等,对于二维数组,列组合和水平组合的效果相同。垂直组合就是把所有组合的数据追加在一起,各数组列数应该一样,对于二维数组,行组合和垂直组合的效果一样。
'''In [ ]:
# 数组a的构造
a = np.arange(6).reshape(3,2)
# 数组b的构造
b = np.arange(9).reshape(3,3)
# 数组c的构造
c = np.arange(6).reshape(2,3)
# 数组的水平组合
np.hstack((a,b))
np.concatenate((a,b),axis=1)
np.append(a,b,axis=1)
# 数组的垂直组合
np.vstack((b,c))
np.concatenate((b,c),axis=0)
np.append(b,c,axis=0)
np.append(a,c)Out[ ]:
array([0, 1, 2, 3, 4, 5, 0, 1, 2, 3, 4, 5])数值的组合 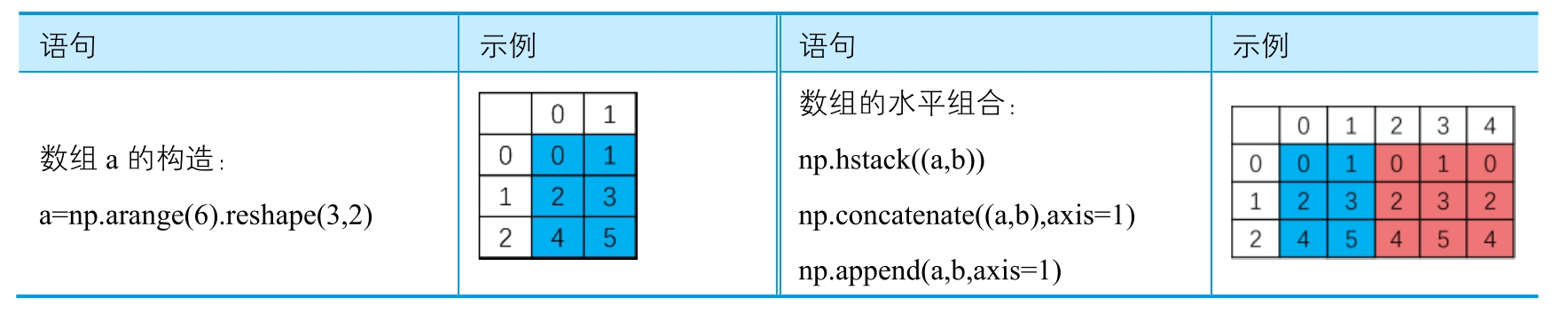
2.1.4 数组的统计函数¶
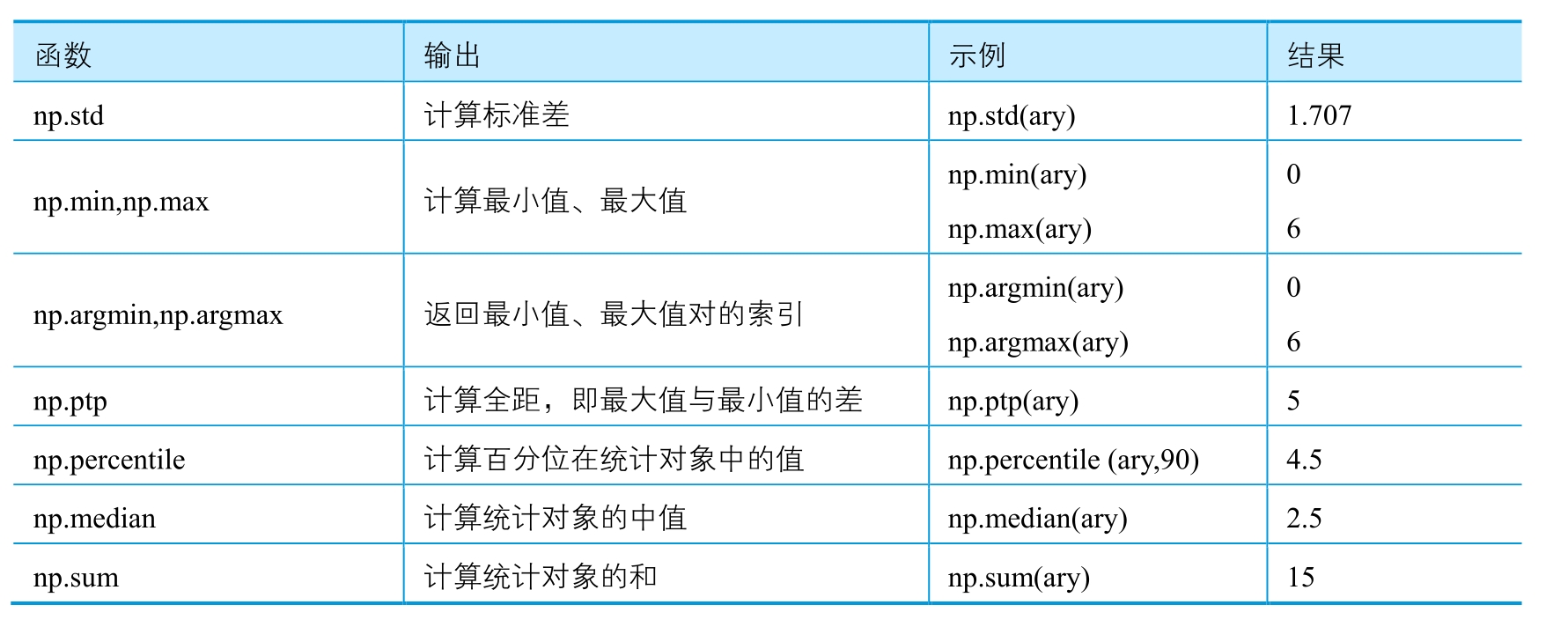
'''有时候,我们需要对数组进行简单的统计分析,包括数组的均值、中值、方差、标准差、最大值、最小值等。图2-1-1所示为3种不同数据分布的统计直方图分析:均值(红色实线)、中值(蓝色实线)、最大值(桔色圆圈)、最小值(绿色圆圈)。NumPy的简单统计函数如表2-1-5所示。示例数据:ary=np.arange(6),则数组ary为array([0,1,2,3,4,5])。'''
In [ ]:
ary = np.arange(6)
# np.mean,np.average 计算平均值、加权平均值
np.mean(ary)
np.average(ary)
# 计算标准差
np.std(ary)
# 计算方差
np.var(ary)
# 计算最大值,最小值
np.min(ary)
np.max(ary)
# 返回最小值。最大值的索引
np.argmin(ary)
np.argmax(ary)
# 计算全距,即最大值与最小值的差
np.ptp(ary)
# 计算百分位统计对象的值
np.percentile(ary,90)
# 计算统计对象中的中值
np.median(ary)
# 计算统计对象的和
np.sum(ary)Out[ ]:
15简单统计函数 
2.2 Pandas:表格处理¶
'''
Pandas提供了3种数据类型,分别是Series、DataFrame和Panel。其中,Series用于保存一维数据,DataFrame 用于保存二维数据,Panel 用于保存三维或者可变维数据,其提供的数据结构使得Python做数据处理变得非常快速与简单。平常的数据分析最常用的数据类型为Series和DataFrame,而Panel较少用到。在Python中调用Pandas往往使用如下约定俗成的方式:
'''In [ ]:
import pandas as pd2.2.1 Series数据结构¶
'''Series本质上是一个含有索引的一维数组,看起来,其包含一个左侧可以自动生成(也可以手动指定)的index和右侧的values值,分别使用 s.index s.values 进行查看。index返回一个index对象,而values则返回一个array(见表2-2-1)。
Series就是一个带有索引的列表,为什么我们不使用字典呢?一个优势是,Series更快,其内部是向量化运行的,和迭代相比,使用Series可以获得显著的性能上的优势。'''表2-2-1 Series的创建与属性 
In [ ]:
s = pd.Series([1,3,2,4])
s.values
# 起始值,终点值,步长
s.index
s = pd.Series([1,3,2,4],index=['a','b','c','d'])
s.values
s.indexOut[ ]:
Index(['a', 'b', 'c', 'd'], dtype='object')2.2.2 数据结构:DataFrame¶
'''DataFrame(数据框)类似于Excel电子表格,也与R语言中DataFrame的数据结构类似。创建类DataFrame实例对象的方式有很多,包括如下几种(见表2-2-2)。'''● 使用list或者ndarray对象创建DataFrame: 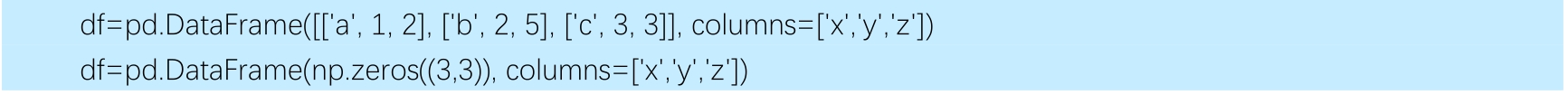
In [ ]:
# 表头
df = pd.DataFrame([['a',1,2],['b',2,5],['c',3,3]],columns=['x','y','z'])
df
df = pd.DataFrame(np.zeros((3,3)),columns=['x','y','z'])
dfOut[ ]:
| x | y | z | |
|---|---|---|---|
| 0 | 0.0 | 0.0 | 0.0 |
| 1 | 0.0 | 0.0 | 0.0 |
| 2 | 0.0 | 0.0 | 0.0 |
● 使用字典创建DataFrame:使用字典创建DataFrame 实例时,利用DataFrame可以将字典的键直接设置为列索引,并且指定一个列表作为字典的值,字典的值便成为该列索引下所有的元素。¶
In [ ]:
df = pd.DataFrame({'x':['a','b','c'],'y':range(1,4),'z':[2,5,3]})
df
df = pd.DataFrame(dict(x=['a','b','c'],y=range(1,4),z=[2,5,3]))
df
# 需要注意的是:数据框的行索引默认是从0开始的。Out[ ]:
| x | y | z | |
|---|---|---|---|
| 0 | a | 1 | 2 |
| 1 | b | 2 | 5 |
| 2 | c | 3 | 3 |
表2-2-2 数据框数据的选取 
In [ ]:
# 数据框的构建
df = pd.DataFrame(dict(x=['a','b','c'],y=range(1,4),z=[2,5,3]))
print(df)
# 选取某一列
df['y']
df.y
df.loc[:,['y']]
df.iloc[:,[1]]
# 选取多列
df[['x','y']]
df.loc[:,['x','y']]
df.iloc[:,[1,2]]
# 选取某一行
df.loc[1,:]
df.iloc[1,:]
# 选取多行
df.loc[[0,1],:]
df.iloc[[0,1],:]
# 选取某个元素
df.loc[1,'y']
df.loc[[1],['y']]
df.iloc[1,1]
# 单条件过滤
df[df.z>=3]
# 多条件过滤
df[(df.z>=3)&(df.z<=4)]
df.query('z>=3&z<=4') x y z
0 a 1 2
1 b 2 5
2 c 3 3Out[ ]:
| x | y | z | |
|---|---|---|---|
| 2 | c | 3 | 3 |
In [ ]:
# 获取数据框的行数、列数和维数:
df.shape[0]
len(df)
df.shape[1]
df.shape
# 获取数据框的列名或行名
df.columns
df.index
# 重新定义列名
df.columns=["X","Y","Z"]
df
# 重新更改某列的列名 注意,如果缺少 inplace选项,则不会更改,而是增加新列。
df.rename(columns={'X':'x'},inplace=True)
df
# 观察数据框的内容
df.info() # info属性表示打印DataFrame的属性信息
df.head() # 查看DataFrame前五行的数据信息。
df.tail() # 查看DataFrame最后五行的数据信息。<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3 entries, 0 to 2
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 x 3 non-null object
1 Y 3 non-null int64
2 Z 3 non-null int64
dtypes: int64(2), object(1)
memory usage: 200.0+ bytesOut[ ]:
| x | Y | Z | |
|---|---|---|---|
| 0 | a | 1 | 2 |
| 1 | b | 2 | 5 |
| 2 | c | 3 | 3 |
数据框的多重索引:通常DataFrame(数据框)只有一列索引,但是有时候要用到多重索引。表2-2-3中的df.set_index(['X','year'])就有两层索引,第0级索引为“X”,第1级索引为“year”,这时使用loc方法选择数据。
表2-2-3 数据框的多重索引 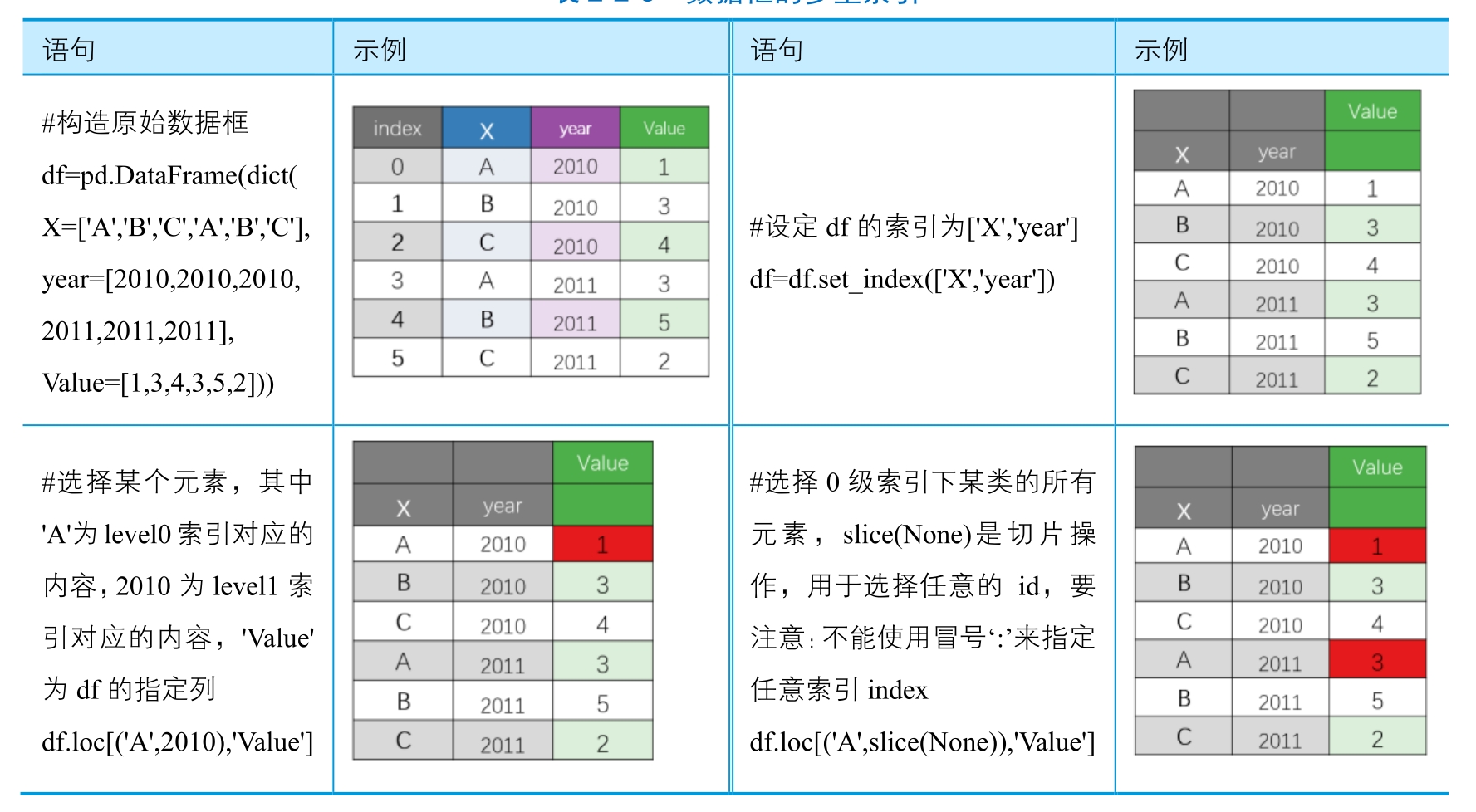
In [ ]:
# 构造原始数据框
df = pd.DataFrame(dict(X=['A','B','C','A','B','C'],year=[2010,2010,2010,2011,2011,2011],Value=[1,3,4,3,5,2]))
df
# 设定df的索引为['X','year']
# df.set_index(['X','year'])
# 选择某个元素,其中'A'为leve10索引对应的内容,2010位leve11索引对应的内容,'Value'为df的指定列
# df.loc[('A',2010),'Value']
# 选择0级索引下某类的所有元素,slice(None)是切片操作,用于选择任意的id
# df.loc[('A',slice(None)),'Value']Out[ ]:
| X | year | Value | |
|---|---|---|---|
| 0 | A | 2010 | 1 |
| 1 | B | 2010 | 3 |
| 2 | C | 2010 | 4 |
| 3 | A | 2011 | 3 |
| 4 | B | 2011 | 5 |
| 5 | C | 2011 | 2 |
空数据表框的创建¶
'''空数据框的创建在需要自己构造绘图的数据框数据信息时,尤为重要。有时候,在绘制复杂的数据图表时,我们需要对现有的数据进行插值、拟合等处理时,再使用空的数据框存储新的数据,最后使用新的数据框绘制图表。创建空数据框的方法很简单:'''In [ ]:
# 创建空数据框
df_empty = pd.DataFrame(columns=['x','y','z'])
df_emptyOut[ ]:
| x | y | z |
|---|
网络分布型数据的创建¶
'''在三维插值展示时尤为重要。结合 np.meshgrid()函数可以创建网格分布型数据框,如下所示。np.meshgrid()函数就是用两个坐标轴上的点在平面上画网格(当传入的参数是两个的时候)。也可以指定多个参数,比如3个参数,那么就可以用三个一维的坐标轴上的点在三维平面上画网格(见表2-2-4)。'''表2-2-4 网格分布型数据的创建 
In [ ]:
a = ['A','B','C']
b = [5,7,9]
# X对应于a中的元素在水平方向上重复,Y对应b中的元素在竖直方向上重复
X,Y = np.meshgrid(a,b)
df_grid = pd.DataFrame(dict(x=X.flatten(),y=Y.flatten()))
df_gridOut[ ]:
| x | y | |
|---|---|---|
| 0 | A | 5 |
| 1 | B | 5 |
| 2 | C | 5 |
| 3 | A | 7 |
| 4 | B | 7 |
| 5 | C | 7 |
| 6 | A | 9 |
| 7 | B | 9 |
| 8 | C | 9 |
2.2.3 数据类型:Categorical¶
'''Pandas拥有特殊的数据结构类型:Categorical(分类)可以用于承载基于整数的类别展示或编码的数据,可分为类别型和有序型,类似于 R 语言里面的因子向量(factor)。分类数据类型可以看成是包含了额外信息的列表,这额外的信息就是不同的类别,可以称之为类别(categories)。分类数据类型在Python的plotnine包中很重要,因为它决定了数据的分析方式以及如何进行视觉呈现。'''分类数据的创建¶
一个分类数据不仅包括分类变量本身,还可能包括变量不同的类别(即使它们在数据中不出现)。分类函数 pd.Categorical()用下面的选项创建一个分类数据。对于字符型列表,分类数据的类别默认依字母顺序创建:[Fair,Good,Ideal,Premium,Very Good]。
数据分析和处理中,经常会遇到一些列的数据是分类变量(Categorical data),也就是指只有有限个数的取值的变量,例如性别、民族、学历、职业等等。为了更方便地对这些变量进行分析和处理,Pandas 库提供了 Categorical 类型。
Categorical 类型是一个由 Pandas 提供的数据类型,用于处理分类变量。它的实现方式是将分类变量转换为数值编码,从而提高数据处理的效率和可读性。通过使用 Categorical 类型,可以将分类变量转换为整数或字符串编码,方便存储和计算。In [ ]:
Cut = ["Fair","Good","Very Good","Premium","Ideal"]
Cut_Facor1 = pd.Categorical(Cut)
Cut_Facor1Out[ ]:
['Fair', 'Good', 'Very Good', 'Premium', 'Ideal']
Categories (5, object): ['Fair', 'Good', 'Ideal', 'Premium', 'Very Good'] 很多时候,按默认的字母顺序排序的因子很少能够让人满意。因此,可以指定类别选项来覆盖默认排序。更改分类数据的类别为[Good,Fair,Very Good,Ideal,Premium],可以在使用pd.Categorical()函数创建分类数据的时候就直接设定好类别。In [ ]:
# pd.Categorical() 函数的第一个参数是一个列表,表示要转换为分类变量的数据。第二个参数 categories 是一个列表,表示分类变量的分类值,其中 "Good"、"Fair"、"Very Good"、"Idel"
# 和 "Premium" 分别对应于分类变量的五个取值。第三个参数 ordered 是一个布尔值,表示分类变量是否有序,这里设置为 True 表示有序。
Cut_Facor2 = pd.Categorical(['Fair', 'Good', 'Very Good', 'Premium', 'Ideal'],
categories=["Good","Fair","Very Good","Idel","Premium"],
ordered=True)
Cut_Facor2Out[ ]:
['Fair', 'Good', 'Very Good', 'Premium', NaN]
Categories (5, object): ['Good' < 'Fair' < 'Very Good' < 'Idel' < 'Premium']2.类别的更改¶
对于已经创建的分类数据或者数据框,可以使用*.astype()函数指定类别选项来覆盖默认排序,从而将分类数据的类别更改为[Good,Fair,Very Good,Ideal,Premium]。In [ ]:
# pd.Series() 是一个用于创建 Series 对象的函数。Series 是 Pandas 中的一种数据结构,类似于一维数组或者列表,但是可以包含不同类型的数据,并且支持标签索引。
Cut = pd.Series(['Fair', 'Good', 'Very Good', 'Premium','Ideal'])
Cut_Facor2 = pd.Categorical(Cut.astype(str),categories=['Good', 'Fair', 'Very Good', 'Ideal', 'Premium'],ordered=True)
Cut_Facor2Out[ ]:
['Fair', 'Good', 'Very Good', 'Premium', 'Ideal']
Categories (5, object): ['Good' < 'Fair' < 'Very Good' < 'Ideal' < 'Premium']3.类型的转换¶
有时,我们需要获得分类数据的类别(categories)和编码(codes),如表2-2-5所示。这样相当于将分类型数据转换成数值型数据。In [ ]:
print(Cut_Facor1)
# 使用 codes 属性获取分类变量中每个取值的编码
Cut_Facor1.codes
# 使用 categories 属性获取分类变量的分类值,返回一个包含分类值的一维数组。
Cut_Facor1.categories
Cut_Facor2.codes
Cut_Facor2.categories['Fair', 'Good', 'Very Good', 'Premium', 'Ideal']
Categories (5, object): ['Fair', 'Good', 'Ideal', 'Premium', 'Very Good']Out[ ]:
Index(['Good', 'Fair', 'Very Good', 'Ideal', 'Premium'], dtype='object')如果需要从另一个数据源获得分类编码数据,则可以使用 from_codes()函数构造。如下所示的Cut_Factor3输出结果为[Fair,Good,Ideal,Fair,Fair,Good],其中categories (3,object)为:[Fair,Good,Ideal]。
编码(encoding)是将非数值型的数据转换为数值型数据的过程。在编码过程中,需要为每个非数值型的取值指定一个唯一的编码,通常使用整数来表示。例如,在将一个包含 ["Fair", "Good", "Very Good", "Premium", "Ideal"] 这五个字符串的列表转换为数值型数据时,可以为它们分别指定编码为 [0, 1, 2, 3, 4]。
分类(category)是将编码后的数值型数据重新转换为非数值型数据的过程。在分类过程中,需要将每个编码对应的非数值型的取值还原出来。例如,在下面的例子中,可以将编码为 0 的数值型数据还原为字符串 "Fair",将编码为 1 的数值型数据还原为字符串 "Good",以此类推。In [ ]:
"""
pd.Categorical.from_codes() 方法的第一个参数是一个列表,
表示分类变量的编码,这里是一个包含六个整数的列表。
第二个参数是一个列表,表示分类变量的分类值,
这里是一个包含三个字符串的列表。将编码列表和分类值列表传递给
pd.Categorical.from_codes() 方法后,它会自动将它们组合成
一个分类变量,并存储在 Cut_Factor3 中。
"""
categories = ["Fair","Good","Ideal"]
codes = [0,1,2,0,0,1]
Cut_Facor3 = pd.Categorical.from_codes(codes,categories)
Cut_Facor3Out[ ]:
['Fair', 'Good', 'Ideal', 'Fair', 'Fair', 'Good']
Categories (3, object): ['Fair', 'Good', 'Ideal']
 浙公网安备 33010602011771号
浙公网安备 33010602011771号