

一、LINUX内核分析 链接汇总
操作系统是如何工作的
系统调用的三个层次
创建新进程的过程
二、读书笔记汇总
三、学习总结
1、计算机是如何工作的
1.冯诺依曼体系结构——核心:存储程序计算机;
2.X86汇编基础:CPU的寄存器(通用寄存器、段寄存器、标志寄存器)、常见汇编指令、堆栈
2、操作系统是如何工作的
1.函数调用堆栈
2.借助Linux内核部分源代码模拟存储程序计算机工作模型及时钟中断
3.在mykernel基础上构造一个简单的操作系统内核
4.三个法宝:
存储程序计算机:所有计算机基础性的逻辑框架堆栈:高级语言的起点,函数调用需要堆栈机制中断机制:多道系统的基础,是计算机效率提升的关键
5.在my_schedule函数中,完成进程的切换。进程的切换分两种:
下一个进程没有被调度过;下一个进程被调度过,可以通过下一个进程的state知道其状态。
3、构造一个简单的Linux系统MenuOS
1.Linux内核源代码简介:sched_init()进程调度初始化函数,函数内关键的初始化——对0号进程,即idle进程进行初始化;rest_init()其他初始化函数,函数内将创建1号进程,即init进程。
2.构造一个简单的Linux系统
3.跟踪调试Linux内核的启动过程:老师用一句中国的古话来形容:道生一,一生二,二生三,三生万物。内核启动过程包括start_kernel之前和之后,之前全部是做初始化的汇编指令,之后开始C代码的操作系统初始化,最后执行第一个用户态进程init。一般分两阶段启动,先是利用initrd的内存文件系统,然后切换到硬盘文件系统继续启动。
4、扒开系统调用的三层皮(上)
1.用户态、内核态和中断处理过程
内核态:一般现代CPU有几种指令执行级别。在高执行级别下,代码可以执行特权指令,访问任意的物理地址,这种CPU执行级别对应着内核态用户态:在相应的低级别执行状态下,代码的掌控范围有限,只能在对应级别允许的范围内活动中断处理是从用户态进入内核态的主要方式,中断/int指令会在堆栈上保存一些寄存器的值:如用户态栈顶地址、当前的状态字、当时cs:eip的值。
2.系统调用概述:
系统调用是操作系统为用户态进程与硬件设备进行交互提供的一组接口系统调用概述和系统调用的三层皮:xyz(API)、system_ call(中断向量)、sys_xyz(中断向量对应的中断服务程序)
3.使用库函数API和C代码中嵌入汇编代码触发同一个系统调用。使用库函数API获取系统当前时间;C代码中嵌入汇编代码的方法;使用C代码中嵌入汇编代码触发系统调用获取系统当前时间
5、扒开应用系统的三层皮(下)
①给MenuOS增加time和time-asm命令
rm menu -rf //强制删除当前menu
git clone http://github.com/mengning/menu.git //重新克隆新版本的menu
cd menu
ls
make rootfs
vi test.c //进入test.c文件
MenuConfig("getpid","Show Pid",Getpid);
MenuConfig("getpid_asm","Show Pid(asm)",GetpidAsm); //在main函数中增加MenuConfig()
int Getpid(int argc,char *argv[]);
int GetpidAsm(int argc,char *argv[]); //增加对应的Getpid和GetpidAsm两个函数
make rootfs //编译
②使用gdb跟踪系统调用内核函数sys_time
qemu -kernel linux-3.18.6/arch/x86/boot/bzImage -initrd rootfs.img -s -Sgdb(gdb)file linux-3.18.6/vmlinux(gdb)target remote:1234 //连接到需要调试的MenuOS(gdb)b start_kernel //设置断点(gdb)c //执行,可见程序在start_kernel处停下list //可查看start_kernel的代码(gdb)b sys_time //sys_time是13号系统调用对应的内核处理函数,在该函数处设置断点(gdb)c
3.系统调用在内核代码中的工作机制和初始化
系统调用在内核代码中的工作机制和初始化简化后便于理解的system_call伪代码简单浏览system_call和iret之间的主要代码
6、进程的描述和进程的创建
1.进程的描述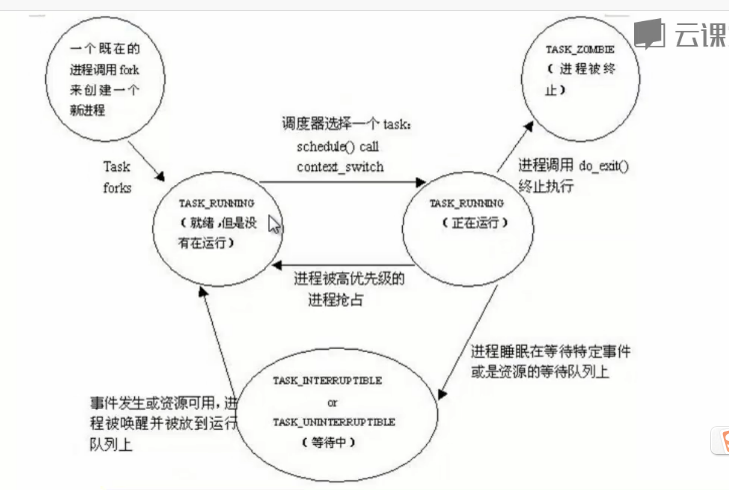
2.进程的创建
进程的创建概览及fork一个进程的用户态代码- 理解进程创建过程复杂代码的方法
- 浏览进程创建过程相关的关键代码
- 创建的新进程是从哪里开始执行的?
- 使用gdb跟踪创建新进程的过程
7、可执行程序的装载
1.预处理、编译、链接和目标文件的格式
- C源代码(.c)经过编译器预处理被编译成汇编代码(.asm)
- 汇编代码由汇编器被编译成目标代码(.o)
- 将目标代码链接成可执行文件(a.out)
- 可执行文件由操作系统加载到内存中执行
2.目标文件的三种形式:
- 1. 可重定位文件.o,用来和其他object文件一起创建可执行文件和共享文件.
- 2. 可执行文件,指出应该从哪里开始执行.
- 3. 共享文件,主要是.so文件,用来被链接编辑器和动态链接器链接
3.可执行程序、共享库和动态加载
1.创建新进程2.新进程调用execve()系统调用执行指定的ELF文件3.调用内核的入口函数sys_execve(),sys_execve()服务例程修改
3.当ELF被load_elf_binary()装载完成后,函数返回至do_execve()在返回至sys_execve()。ELF可执行文件的入口点取决于程序的链接方式:
1.静态链接:elf_entry就是指向可执行文件里边规定的那个头部,即main函数处。2.动态链接:可执行文件是需要依赖其它动态链接库,elf_entry就是指向动态链接器的起点。
8、进程的切换和系统的一般执行过程
1.进程进度与进程调度的时机分析
schedule()函数实现调度:中断处理过程(包括时钟中断、I/O中断、系统调用和异常)中,直接调用schedule(),或者返回用户态时根据need_resched标记调用schedule();内核线程可以直接调用schedule()进行进程切换,也可以在中断处理过程中进行调度,也就是说内核线程作为一类的特殊的进程可以主动调度,也可以被动调度 用户态进程无法实现主动调度,仅能通过陷入内核态后的某个时机点进行调度,即在中断处理过程中进行调度
2.特殊情况
通过中断处理过程中的调度时机,用户态进程与内核线程之间互相切换和内核线程之间互相切换,与最一般的情况非常类似,只是内核线程运行过程中发生中断没有进程用户态和内核态的转换;内核线程主动调用schedule(),只有进程上下文的切换,没有发生中断上下文的切换,与最一般的情况略简略;创建子进程的系统调用在子进程中的执行起点及返回用户态,如fork;
加载一个新的可执行程序后返回到用户态的情况,如execve;
通过中断处理过程中的调度时机,用户态进程与内核线程之间互相切换和内核线程之间互相切换,与最一般的情况非常类似,只是内核线程运行过程中发生中断没有进程用户态和内核态的转换内核线程主动调用schedule(),只有进程上下文的切换,没有发生中断上下文的切换,与最一般的情况略简略。创建子进程的系统调用在子进程中的执行起点及返回用户态,如fork,加载一个新的可执行程序后返回到用户态的情况,如execve
四、学习体会
经过了这两个多月的学习,个人感觉学习Linux最困难的部分是还是入门的时候。因为对于汇编的基础太薄弱,起初的学习还是有点吃力,一个十分钟的视频至少得看30分钟才能勉强理解。后来视频看得多了,也也大概有了一些“感觉”。然后通过阅读《Linux内核设计与分析》这本教材,对老师上课的内容起了一个补充说明的作用,我对例如Linux内核的构架和原理,有了一些初步的了解,明白了内核的工作流程。在今后的学习中,我将会更加努力,按照老师的教学思路,多多实践,争取将理论知识运用到实际中,深入理解Linux内核。
何佳原创作品转载请注明出处
《Linux内核分析》MOOC课程http://mooc.study.163.com/course/USTC-1000029000

