


陈民禾——原创作品转载请注明出处—— 《Linux内核分析》MOOC课程http://mooc.study.163.com/course/USTC-1000029000
一.复习上周内容
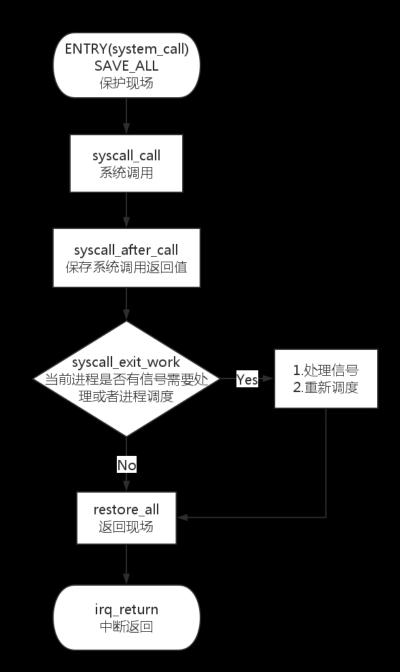
上周主要学习了Linux中的系统调用的过程,如图所示就是系统调用的大致过程:
一.关于进程调度的一些基本概念
fork():进程是处于执行期的程序以及相关资源的总称,进程在创建它的时候开始存活,在Linux系统中。这通常是调用fork()系统的结果,该系统调用通过复制一个现有进程来创建一个全新的进程,调用fork()的进程成为父进程,新产生的进程称之为子进程,在调用结束时,在返回点这个相同位置上,父进程恢复执行,子进程开始执行,fork()系统从内核返回两次:一次返回到父进程,另一次回到新的子进程。其中fork()实际上是由clone()系统调用实现的。
exec():创建新的进城之后会立即执行新的进程,接着调用exec()这组函数就可以创建新的地址空间,并把新的地址空间载入其中。
进程描述符:内核把进程的列表存放在叫做任务队列的双向循环列表中,链表中的类型都是task_struct、成为进程描述符的结构,进程描述符包含一个具体进程的所有信息,能完整的描述一个正在执行的程序:它打开的文件,进程的地址空间,挂起的信号,进程的状态,还有其它的更多信息。
thread_info:每个进程的task_struct存放在内核栈的尾端,
进程状态转换:
- TASK_RUNNING具体是就绪还是执行,要看系统当前的资源分配情况;
- TASK_ZOMBIE也叫僵尸进程
三.进程创建
3.1 写时拷贝
只有在需要写入的时候,数据才会被复制,从而使各个进程拥有各自的拷贝。也就是说,资
源的复制只有在需要写入的时候才进行,在此之前,只是以只读方式共享。这种技术使地址空间上的页的拷贝被推迟到实际发生写入的时候才进行。在页根本不会被写人的情况下(举例来说,fork()后立即调用exec(})它们就无须复制了。fork()的实际开销就是复制父进程的页表以反给予进程创建唯一的进程描述符。在一般情况下,进程创建后都会马上运行一个可执行的文件,这种优化可以避免拷贝大量根本就不会被使用的数据〈地址空间里常常包含数十她的数据〉。由于Unix 强调进程快速执行的能力,所以这个优化是很重要的。
3. 2 fork()
Linux 通过clone()系统调用实现fork() 。这个调用通过一系列的参数标志来指明父、子进程需要共享的资源〈关于这些标志更多的信息请参考本章后面3.4 节〉。fork()、vfork()和一clone()库函数都根据各自需要的参数杨L志去调用clone(),然后由clone()去调用do_fork().do_fork 完成了创建中的大部分工作,它的定义在kemeVfork.c 文件中。该函数调用copy_process()函数,然后让进程开始运行。copy_process()函数完成的工作很有意思:
l )调用dup_task_ struct()为新进程创建一个内核枝、也read_info 结构和task_struct,这些值与当前进程的值相同。此时, 子进程和父进程的描述符是完全相同的。
2 )检查并确保新创建这个子进程后,当前用户所拥有的进程数目没有超出绘色分配的资源
的限制.
3 )子进程着手使自己与父进程区别开来。进程描述符内的许多成员都要被清0 或设为初始值.那些不是继承而来的进程描述符成员,主要是统计信息。task_struct 中的大多数数据都依然未被修改.
4 ) 子进程的状态被设置为TASK_UNJNTERRUPTIBLE,以保证它不会投入运行。
5 ) copy _process()调用copy_flags()以更新task_struct 的组ags 成员.表明进程是否拥有超级用户权限的PF_SUPE盯RIV 标志被清0。表明进程还没有调用exec()函数的PF_FOR.KNOEXEC标志被设置。
6 )调用alloc _pid()为新进程分配一个有效的PID。
7 )根据传递给clone()的参数标志, copy_process()拷贝或共享打开的文件、文件系统信息、信号处理函数、进程地址空间和命名空间等。在一般情况下,这些资源会被给定进程的所有线程共享:否则,这些资源对每个进程是不同的,因此被拷贝到这里。的最后, copy_process()傲扫尾工作并返回一个指向子进程的指针。再回到do_fork()函数,如果copy_process()函数成功返回,新创建的子进程被唤醒并让其投入运行。内核有意选择子进程首先执行。.因为一般子进程都会马上调用exec()函数,这样可以避免写时拷贝的额外开销,如果父进程首先执行的话,有可能会开始向地址空间写入。
四.实验过程
1.更新menu内核,然后删除test_fork.c以及test.c(以减少对之后实验的影响)
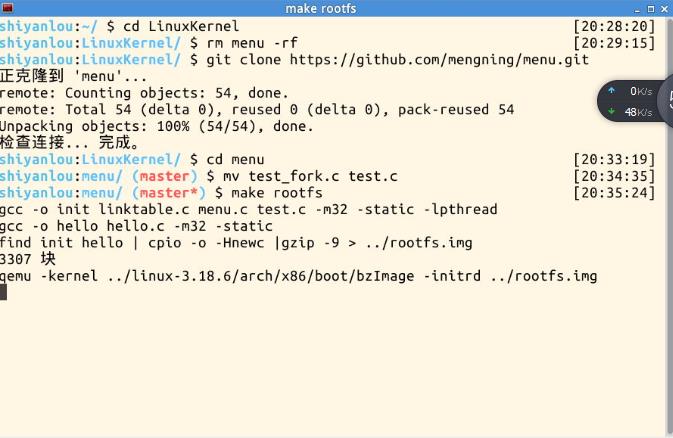
2.编译内核,可以看到fork命令
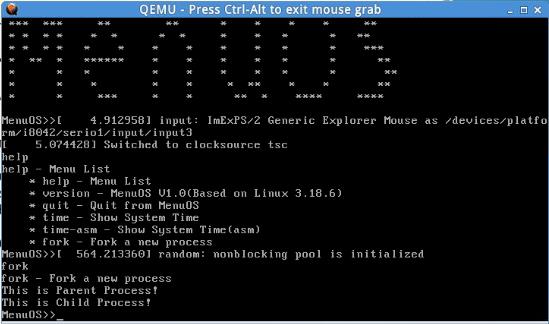
3.启动gdb调试,并对主要的函数设置断点
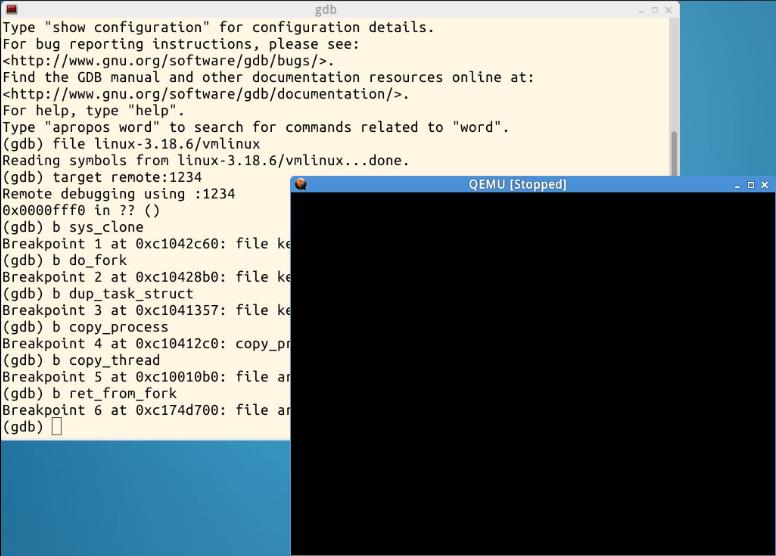
4.在MenuOS中执行fork,就会发现fork函数停在了父进程中

5.继续执行之后,停在了do_fork的位置。然后n单步执行,依次进入copy_process、dup_task_struct。按s进入该函数,可以看到dst = src(也就是复制父进程的struct)

6.在copy_thread中,可以看到把task_pg_regs(p)也就是内核堆栈特定的地址找到并初始化
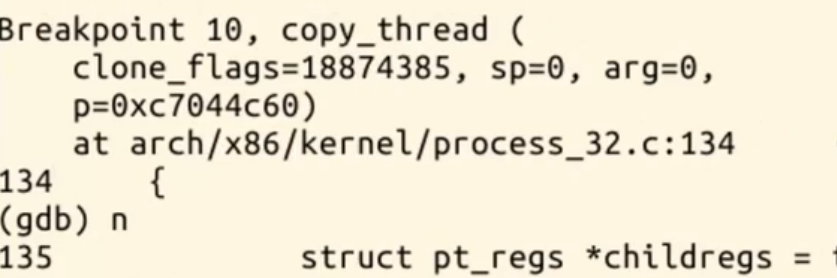
7.到了159、160行的代码就是把压入的代码再放到子进程中:
*children = *current_pt_regs(); childregs->ax = 0;
8.164行,是确定返回地址
p->thread.ip = (unsigned long) ret_from_fork;
实验感想:
只是我第一次这么早就完成博客,在这次实验的过程中我了解了进程间调度的基本方法,还自己实践了gdb对内核代码的调试,很有意义。可执行程序代码( Unix 称其为代码段, text section)。通常进程还要包含其他资源,像打开的文件,挂起的信号,内核内部数据,处理器状态, 一个或多个具有内存映射的内存地址空间及一个或多个执行线程( thread of execution ),当然还包括用来存放全局变量的数据段等。实际上,进程就是正在执行的程序代码的实时结果。
