

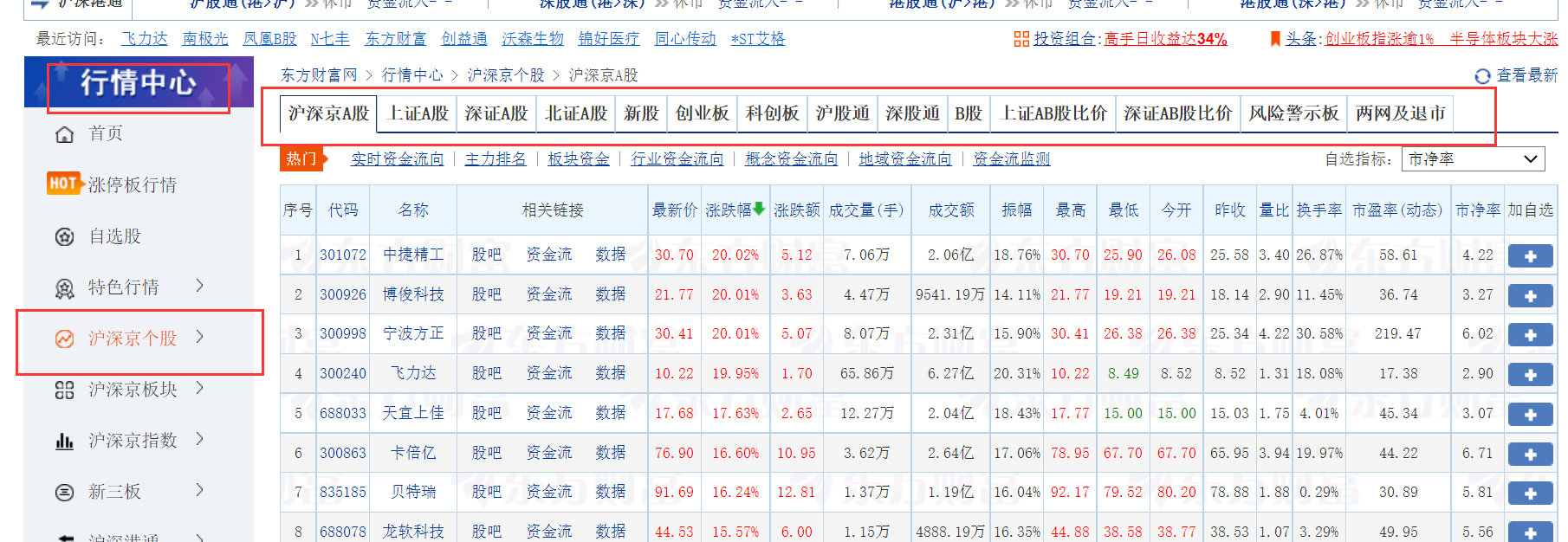
代码:
主要是爬取行情中心的不同板块的股票数据:

import requests
import json
import re
import pandas as pd
# 存储相关信息
def getMessage(getCount):
if getCount == 1:
stockPlateDict = {
'沪深京A股': 'hs_a_board',
'上证A股': 'sh_a_board',
'深证A股': 'sz_a_board',
'北证A股': 'bj_a_board',
'新股': 'newshares',
'创业板': 'gem_board',
'科创板': 'kcb_board',
'沪股通': 'sh_hk_board',
'深股通': 'sz_hk_board',
'B股': 'b_board',
'上证AB股比价': 'ab_comparison_sh',
'深证AB股比价': 'ab_comparison_sz',
'风险警示板': 'st_board',
'两网及退市': 'staq_net_board'
}
return stockPlateDict
elif getCount == 2:
webUrl = "https://23.push2.eastmoney.com/api/qt/clist/get?"
return webUrl
elif getCount == 3:
urlSuf = [ # 每个板块的网址后缀
"cb=jQuery1124011309990273440462_1650110291355&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1650110291377",
"cb=jQuery1124011309990273440462_1650110291355&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:1+t:2,m:1+t:23&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1650110291388",
"cb=jQuery1124011309990273440462_1650110291355&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:0+t:6,m:0+t:80&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1650110291392",
"cb=jQuery1124011309990273440462_1650110291355&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:0+t:81+s:2048&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1650110291396",
"cb=jQuery1124011309990273440462_1650110291355&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f26&fs=m:0+f:8,m:1+f:8&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f26,f22,f11,f62,f128,f136,f115,f152&_=1650110291400",
"cb=jQuery1124011309990273440462_1650110291355&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:0+t:80&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1650110291405",
"cb=jQuery1124011309990273440462_1650110291355&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:1+t:23&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1650110291408",
"cb=jQuery1124011309990273440462_1650110291351&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f26&fs=b:BK0707&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f26,f22,f11,f62,f128,f136,f115,f152&_=1650110291412",
"cb=jQuery1124011309990273440462_1650110291351&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f26&fs=b:BK0804&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f26,f22,f11,f62,f128,f136,f115,f152&_=1650110291416",
"cb=jQuery1124011309990273440462_1650110291351&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:0+t:7,m:1+t:3&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1650110291420",
"cb=jQuery1124011309990273440462_1650110291351&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f199&fs=m:1+b:BK0498&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152,f201,f202,f203,f196,f197,f199,f195,f200&_=1650110291424",
"cb=jQuery1124011309990273440462_1650110291351&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f199&fs=m:0+b:BK0498&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152,f201,f202,f203,f196,f197,f199,f195,f200&_=1650110291427",
"cb=jQuery1124031292793882810255_1650114519858&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:0+f:4,m:1+f:4&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1650114519867",
"cb=jQuery1124031292793882810255_1650114519858&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:0+s:3&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f26,f22,f33,f11,f62,f128,f136,f115,f152&_=1650114519872"
]
return urlSuf
elif getCount == 4:
stockMessage = {
'f12': '股票代码',
'f14': '名称',
'f2': '最高',
'f3': '涨跌幅%',
'f4': '涨跌额',
'f5': '成交量(手)',
'f6': '成交额',
'f7': '振幅%',
'f8': '换手率%',
'f9': '市盈率(动态)',
'f10': '量比',
'f15': '最新价',
'f16': '最低价',
'f17': '今开',
'f18': '昨收',
'f23': '市净率',
}
return stockMessage
# 得到板块名称
def getPlateName():
stockPlateDict = getMessage(1)
plateName = [] # 板块名称
for i in stockPlateDict:
plateName.append(i)
return plateName
# 得到板块uel列表
def getPlateUrlList(inputPlateName, pageCount):
webUrl = getMessage(2) # 网站首地址
op = getSplitURL() # 分割后的网址
plateName = getPlateName() # 板块名称
pagesStart = [] # 存储分割后页码之前的后缀
pagesEnd = [] # 存储分割后页码之后的后缀
plateURL = [] # 板块URL
for i in range(0, len(op)): # 组装每一个板块
pagesStart.append(webUrl + op[i][0][0]) # 分割后页码之前的后缀
pagesEnd.append(op[i][0][1]) # 分割后页码之后的后缀
for i in range(0, len(plateName)):
if plateName[i] == inputPlateName:
for j in range(1, pageCount + 1): # 添加第i个板块的第j页
plateURL.append(pagesStart[i] + str(j) + pagesEnd[i])
return plateURL # 返回多页数的URL列表
# 处理url(不加页码的)
def getSplitURL():
urlSuf = getMessage(3) # 得到网址后缀
suf = [i.split("fields")[0] for i in urlSuf] # 分割掉无用的后缀
pattern = re.compile("(.*pn=)1(&.*)") # 分割页码
op = [re.findall(pattern, i) for i in suf] # 正则匹配分割页码
return op
# 请求网页得到json数据
def requestURL(plateName, requestCount): # 请求已经处理好的url
urls = getPlateUrlList(plateName, requestCount) # 得到指定板块指定页数的url列表
resTxT = [] # 存储请求到的每一页数据
for i in range(0, requestCount):
# 请求第i页url
res = requests.get(urls[i])
# text文本
doc = res.text
# 正则表达式
pat = re.compile("({\"f1\".*?})")
# 正则匹配
resTxT.append(re.findall(pat, doc))
return resTxT
# 程序开始的选择项
def getChoose(choose):
plateNmae = getPlateName() # 板块名称列表
for i in range(0, len(plateNmae)):
if choose == i + 1: # 对应的选择返回对应的板块名称
return plateNmae[i]
# 处理f信息
def getStockMsg(chPlateNmae, pageCount):
text = requestURL(chPlateNmae, pageCount) # 请求到的f信息
dicMessage = [] # 二维列表,第一层的个数表示页码数,第二层是存储的对应页码的数据
for i in range(0, len(text)): # 遍历第i页
dicMessage.append([])
for j in range(0, len(text[i])): # 第i页的第j个元素
dicMessage[i].append(json.loads(text[i][j])) # 转换为字典
return dicMessage
def getStockFF():
stockMessage = getMessage(4) # 拿到f信息字典
stockFF = [i for i in stockMessage] # f信息
return stockFF
# 获取股票的信息
def getStockValue(dicMsg):
# dicMsg # 二维列表,存储股票信息
stockFF = getStockFF() # 获取对应的f信息
stockVal = [] # 存储f信息对应的值
for i in range(0, len(dicMsg)): # 访问第i页
stockVal.append([])
for j in range(0, len(dicMsg[i])): # 访问第i页的第j个元素
stockVal[i].append([])
for k in stockFF: # 保存对应的f信息的值
stockVal[i][j].append(dicMsg[i][j].get(k))
return stockVal
# 创建表格
def makeDataDrame(stockValueList):
stockFF = getStockFF() # 得到f信息
stockMsg = getMessage(4) # 拿到股票title
columns = [] # 存储f信息对应的值
df = pd.DataFrame()
for i in stockFF:
columns.append(stockMsg.get(i)) # 添加值
stockList = []
for i in range(0, len(stockValueList)): # 遍历每一页
for j in range(0, len(stockValueList[i])):
stockList.append(stockValueList[i][j]) # 使用一个新列表将三维转为二维
index = [i for i in range(1, len(stockList) + 1)] # 行数
df = pd.DataFrame(stockList, columns=columns, index=index) # 创建表格
return df
# 保存
def toSave(df):
df.to_excel('D:\df.xlsx')
return True
if __name__ == '__main__':
plateNmae = getPlateName()
print("----------------- 请选择板块 ---------------------")
for i in range(0, len(plateNmae)):
print("" + str(i + 1) + "、" + plateNmae[i])
print("----------------- 请选择以上板块-------------------------------")
chPlateNmae = getChoose(int(input("请输入您的选择:")))
pageCount = int(input("请输入您要爬取的页数:"))
dicMsg = getStockMsg(chPlateNmae, pageCount)
stockValueList = getStockValue(dicMsg)
df = makeDataDrame(stockValueList)
isOk = toSave(df)
print(isOk)
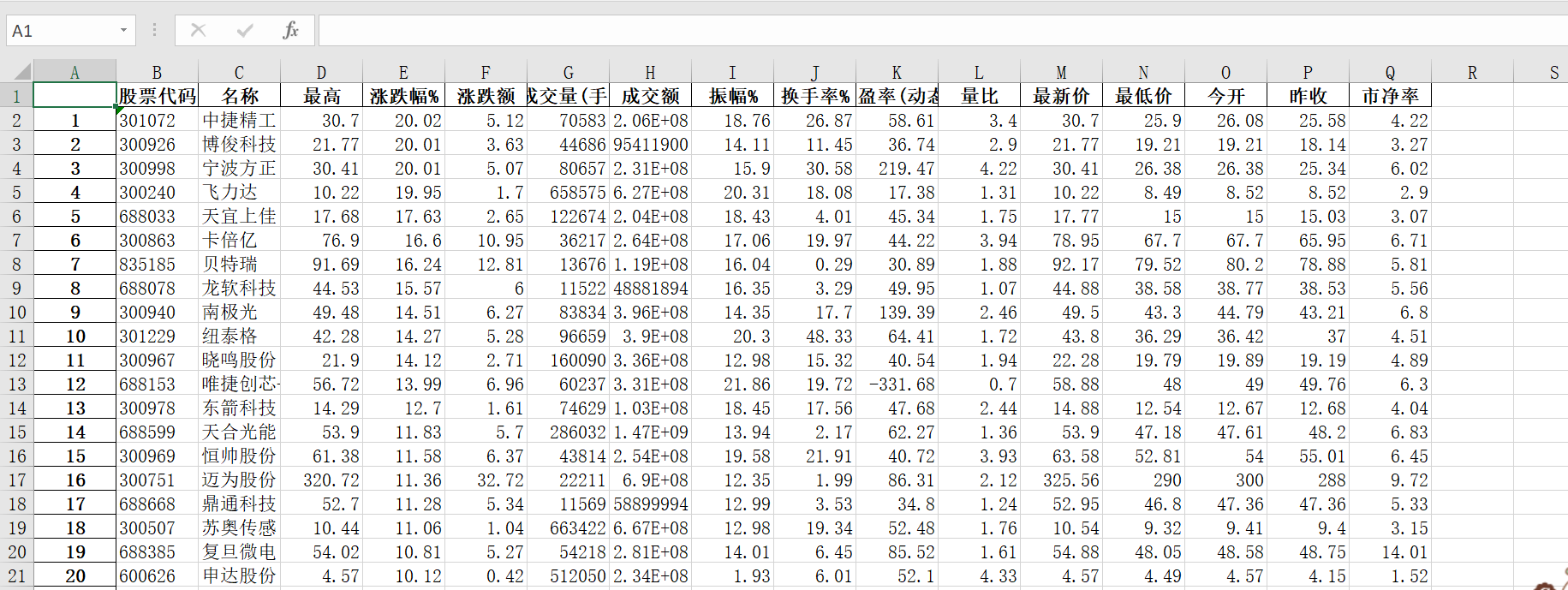
保存结果:


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 【.NET】调用本地 Deepseek 模型
· CSnakes vs Python.NET:高效嵌入与灵活互通的跨语言方案对比
· Plotly.NET 一个为 .NET 打造的强大开源交互式图表库
· DeepSeek “源神”启动!「GitHub 热点速览」
· 上周热点回顾(2.17-2.23)