


今天为了提高一个程序的效率,将程序中的大多数map换成了hash_map,替换之后效率提升了不少。
替换之前也有犹豫,理论上hash_map比map效率要高很多,一个查找时是接近O(1),一个是O(lg N),数量级就不一样;但凡事总有两面性,hash_map目前没有正式写入STL的标准,而且由于它比红黑树实现的map要复杂一些,在小一些的数据集上可能未必有明显的优势;
那么我是应该把自己的程序中全部的map替换掉,还是替换一部分,还是根本就不需要替换?
我想自己先看一看hash_map在多大的数据集上比map有优势。
先做了个小实验看map插入数据的效率(代码是hash_map的,map实现的只需简单修改)
 View Code
View Code

#include <iostream>
#include <hash_map>
//#include<map>
#include <ctime>
using namespace std;
using namespace __gnu_cxx;
int main()
{
clock_t start = clock();
clock_t finish;
double totaltime;
hash_map<int,int> hm;
//map<int,int> m;
for(int i = 0; i < 50000000; i++)
{
hm.insert(make_pair(i,i));
if(i%1000000 == 0)
{
finish = clock();
totaltime = (double)(finish-start)/CLOCKS_PER_SEC;
cout<<i<<" "<< totaltime << endl;
}
}
finish = clock();
totaltime=(double)(finish-start)/CLOCKS_PER_SEC;
cout<<"\nRuntime is: "<< totaltime << "s" << endl;
//system("pause");
return 0;
}
#include <hash_map>
//#include<map>
#include <ctime>
using namespace std;
using namespace __gnu_cxx;
int main()
{
clock_t start = clock();
clock_t finish;
double totaltime;
hash_map<int,int> hm;
//map<int,int> m;
for(int i = 0; i < 50000000; i++)
{
hm.insert(make_pair(i,i));
if(i%1000000 == 0)
{
finish = clock();
totaltime = (double)(finish-start)/CLOCKS_PER_SEC;
cout<<i<<" "<< totaltime << endl;
}
}
finish = clock();
totaltime=(double)(finish-start)/CLOCKS_PER_SEC;
cout<<"\nRuntime is: "<< totaltime << "s" << endl;
//system("pause");
return 0;
}
以上代码在xp下用codeblocks gcc提供的hash_map实现(网上有人说vs的hash_map效率不高,maybe
插入的数据量是五千万,之所以测这个数据量是因为它和我要修改的程序数据量级别相当,内存2G,一亿以上有时候程序会报错,内存溢出。
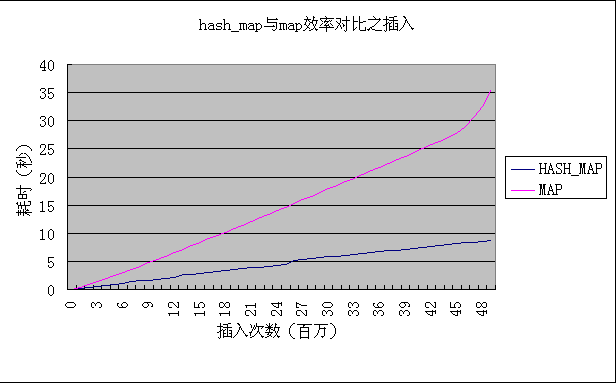
效果比较明显的还是另外一个小实验,对比查找效率,进行五千万次查找。可见hash_map速度一直是优于map的,而且是明显优势。
View Code
#include <iostream>
#include <hash_map>
//#include<map>
#include <ctime>
using namespace std;
using namespace __gnu_cxx;
int main()
{
hash_map<int,int> hm;
//map<int,int> m;
for(int i = 0; i < 50000000; i++)
hm.insert(make_pair(i,i));
clock_t start = clock();
clock_t finish;
double totaltime;
for(int i = 0; i < 50000000; i++)
{
if(hm.find(i)== hm.end())
cout<<"Error!";
if(i%1000000 == 0)
{
finish = clock();
totaltime = (double)(finish-start)/CLOCKS_PER_SEC;
cout<<i<<" "<< totaltime << endl;
}
}
finish = clock();
totaltime=(double)(finish-start)/CLOCKS_PER_SEC;
cout<<"\nRuntime is: "<< totaltime << "s" << endl;
//system("pause");
return 0;
}
#include <hash_map>
//#include<map>
#include <ctime>
using namespace std;
using namespace __gnu_cxx;
int main()
{
hash_map<int,int> hm;
//map<int,int> m;
for(int i = 0; i < 50000000; i++)
hm.insert(make_pair(i,i));
clock_t start = clock();
clock_t finish;
double totaltime;
for(int i = 0; i < 50000000; i++)
{
if(hm.find(i)== hm.end())
cout<<"Error!";
if(i%1000000 == 0)
{
finish = clock();
totaltime = (double)(finish-start)/CLOCKS_PER_SEC;
cout<<i<<" "<< totaltime << endl;
}
}
finish = clock();
totaltime=(double)(finish-start)/CLOCKS_PER_SEC;
cout<<"\nRuntime is: "<< totaltime << "s" << endl;
//system("pause");
return 0;
}
#
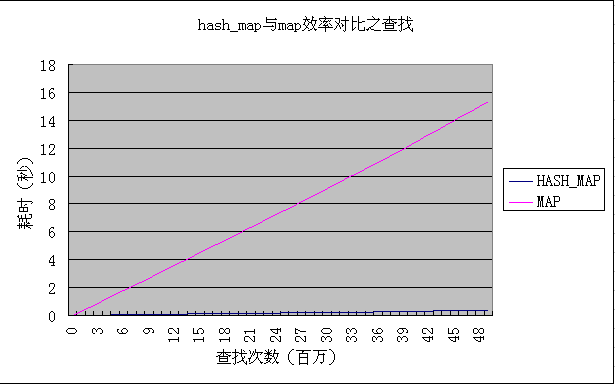
需要说明的是,这里的对比只是为了自己了解一下两种数据结构孰优孰劣,简单地这样随手一对比不保证严谨。
