

Microsoft 时序算法提供了一些针对连续值(例如一段时间内的产品销售额)预测进行了优化的多种算法。 虽然其他 Microsoft 算法(如决策树)也能预测趋势,但是他们需要使用其他新信息列作为输入才能进行预测,而时序模型则不需要。 时序模型仅根据用于创建该模型的原始数据集就可以预测趋势。 进行预测时您还可以向模型添加新数据,随后新数据会自动纳入趋势分析范围内。
下面的关系图显示了一个用于预测一段时间内某一产品在四个不同销售区域的销售额的典型模型。 该关系图中的模型以红色、黄色、紫色和蓝色线条分别显示每个区域的销售额。 每个区域的线条都分为两部分:
历史信息显示在竖线的左侧,表示算法用来创建模型的数据。
预测信息显示在竖线的右侧,表示模型所做出的预测。
源数据和预测数据的组合称为“序列 ”。
举例说明了时间序列
Microsoft 时序算法的一个重要功能就是可以执行交叉预测。 如果用两个单独但相关的序列为该算法定型,则可以使用生成的模型来根据一个序列的行为预测另一个序列的结果。 例如,一个产品的实际销售额可能会影响另一个产品的预测销售额。 在创建可应用于多个序列的通用模型时,交叉预测也很有用。 例如,由于序列缺少高质量的数据,造成对某一特定区域的预测不稳定。 您可以根据所有四个区域的平均情况来为通用模型定型,然后将该模型应用到各个序列,以便为每个区域产生更稳定的预测。
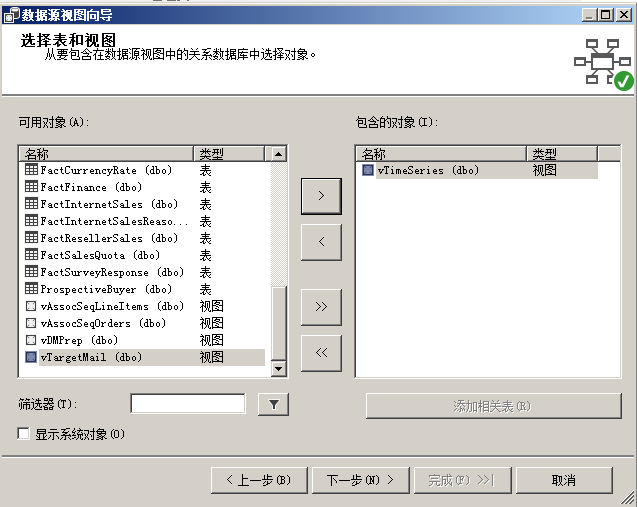
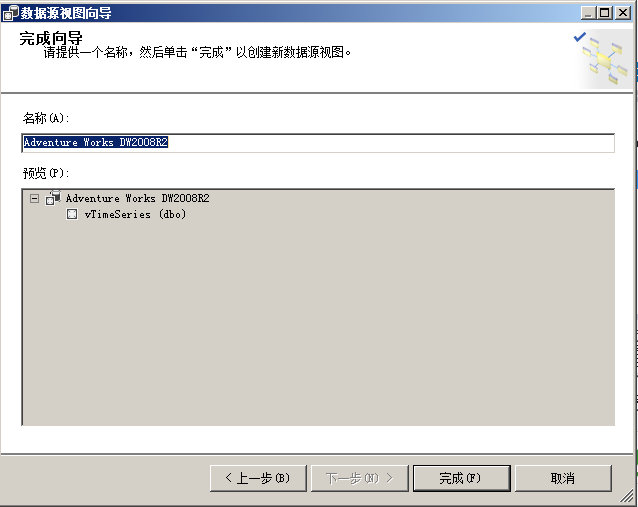
新建数据源视图,选择adventureDW2008R2数据库
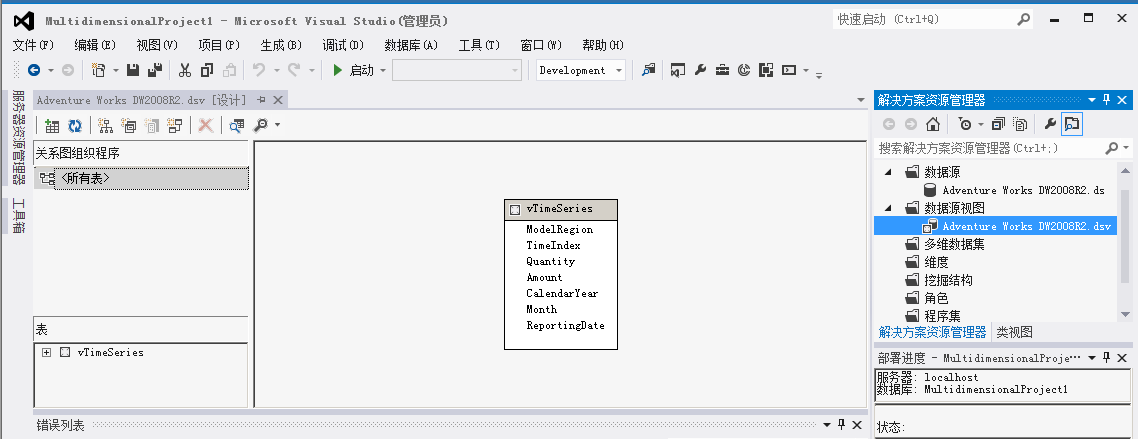
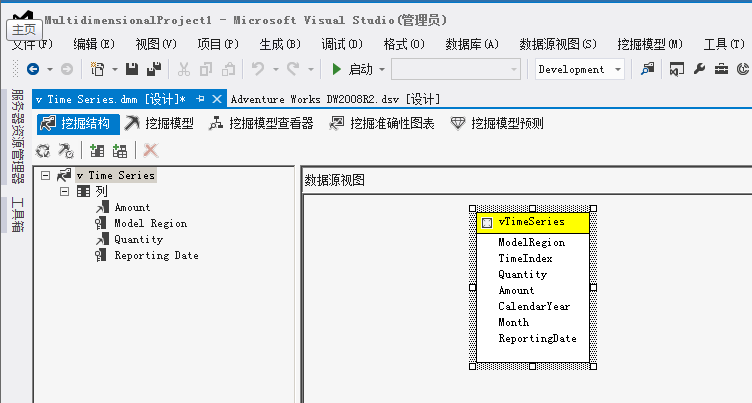
新建数据挖掘结构
选择时序分析

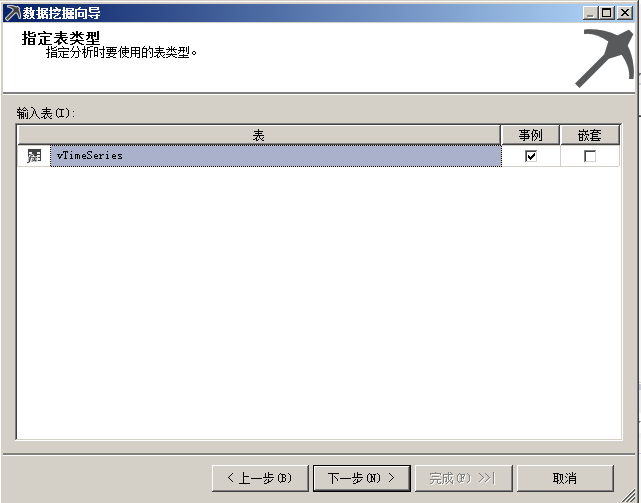
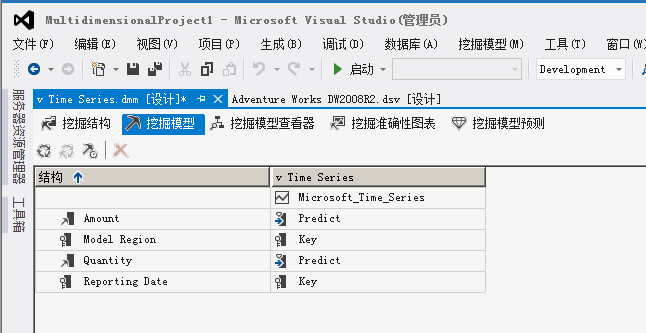
选择挖掘类型结构
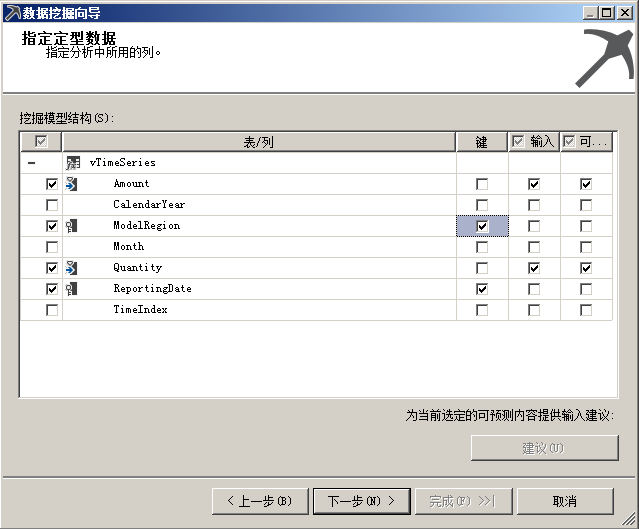

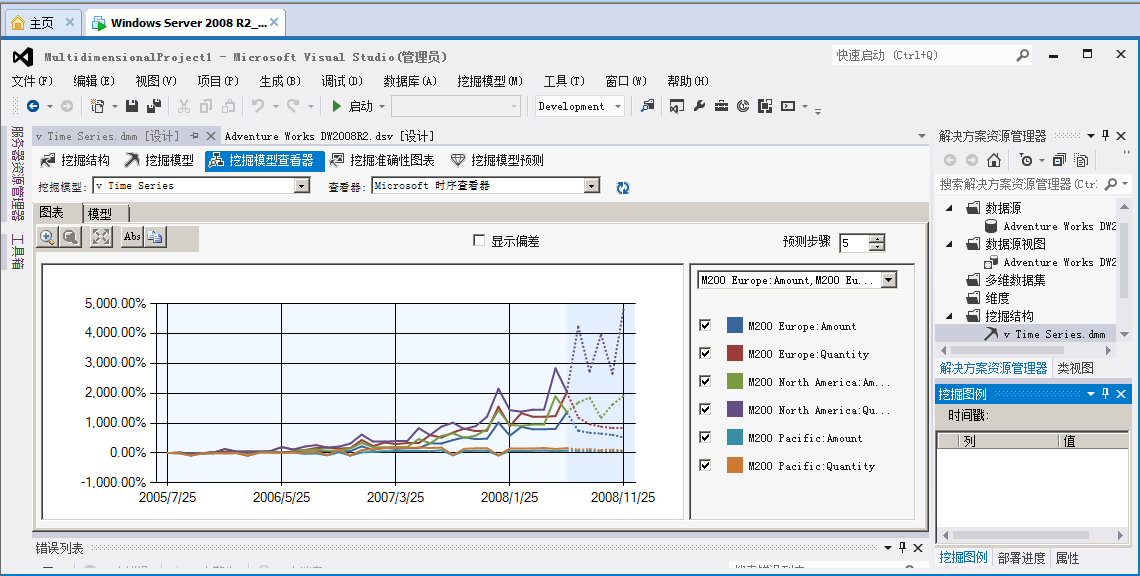
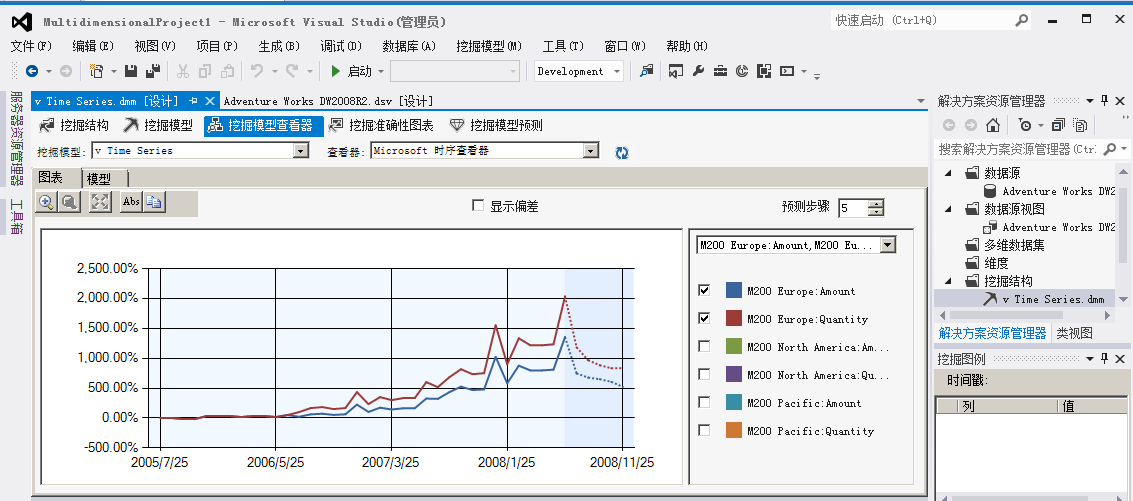
前半部分模型历史分析数据,后面模糊区为推测区域,右侧一个序列筛选的下拉选项框,从横轴中我们可以看到,时间区间为2005年7月25——2007年11月25折线以实线表示,后面的区域为预测区域,预测区间为2008年7月25日至2008年11月25,折线以虚线表示。
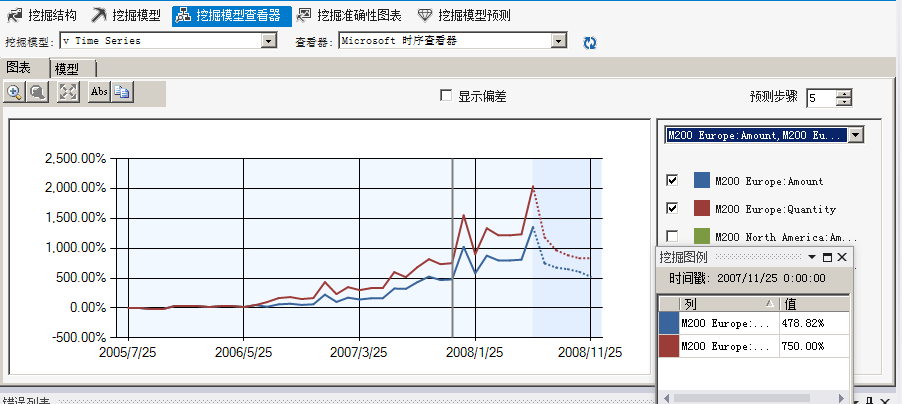
通过点击图表中间的点击线,我们可以分析这款自行车在这个两个地区一年中的销售峰值为5月和12月,也就是所谓的旺季,根据此我们更能够采取相应的应对措施,比如旺季多增加库存,淡季减少库存
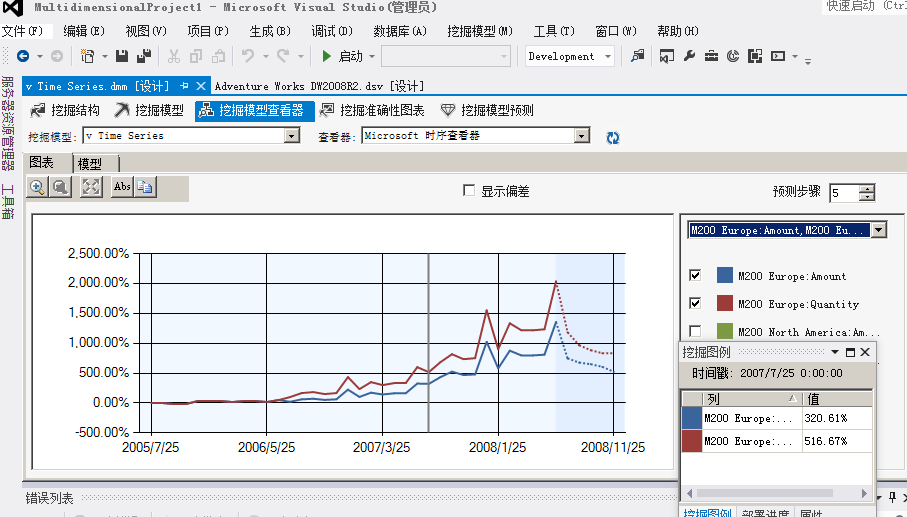
08年的7月份将是这款产品的旺季,同样淡季为九月份
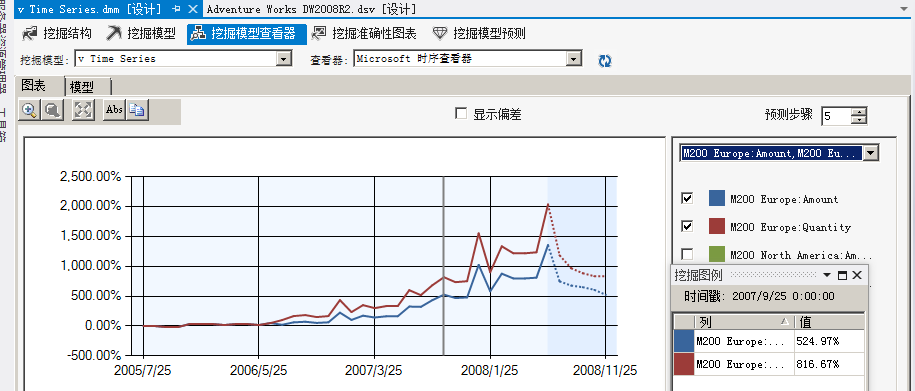
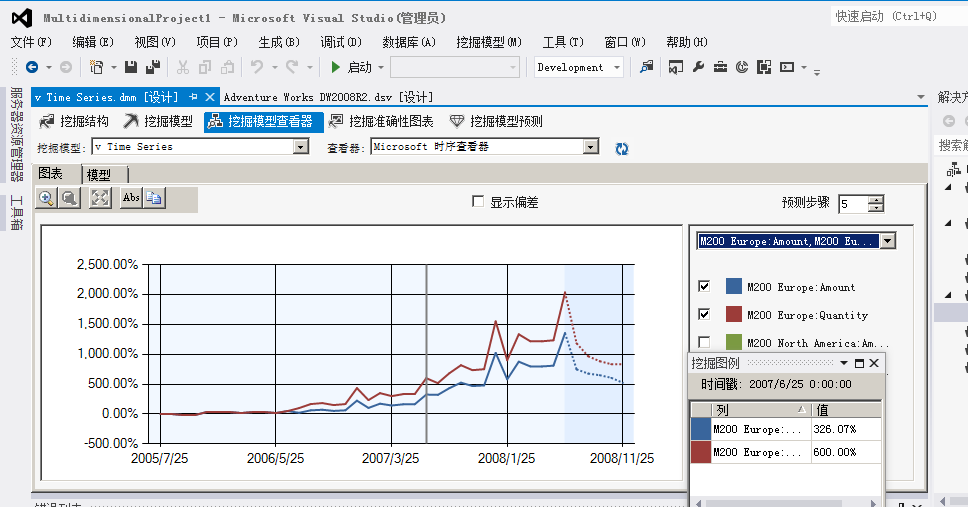
而这是在欧洲的销量,但是在北美就不一样了,它反而是在08年的9月份为旺季,上图中可以看到,说明这两个区域的销售量还会有蛮大区别的,仅仅凭靠经验是分析不出来的对吧。同样它的淡季反而提前到来了,看下图:
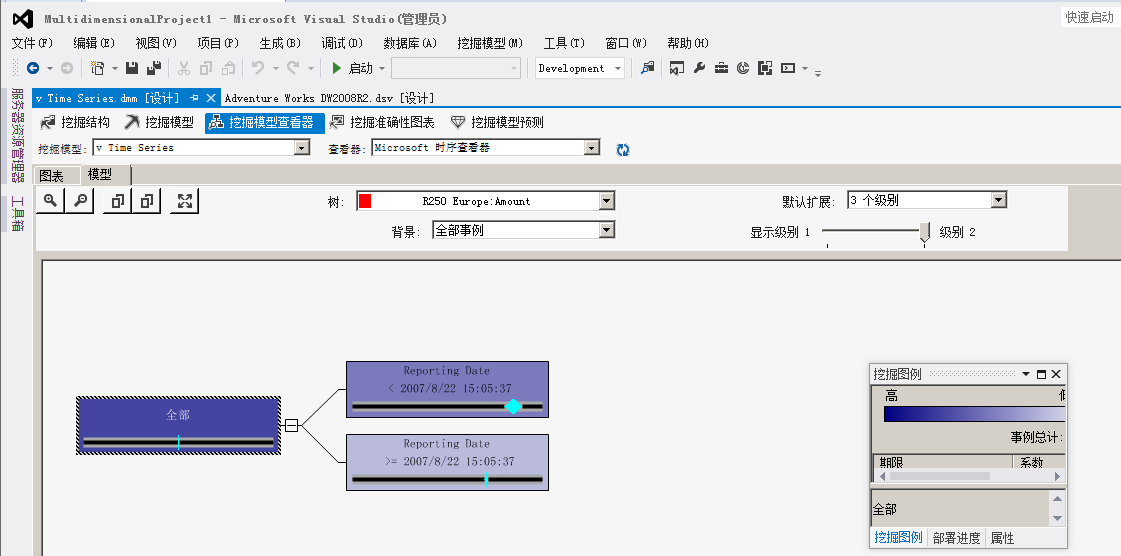
上图中可以看到R250这款产品将以2007年8月22日这天为分界线,在这之前销量值远远大于这之后的销量
