.net网站的文件上传读取进度条和断点下载
1、 文件上传到服务器时的进度读取
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 | UpfileResult result = new UpfileResult();try{ //直接使用request.Files读取,是无法计算进度的。需要主动操作文件流的读取,同时计算上传进度 IServiceProvider provider = HttpContext.Current; HttpWorkerRequest request = (HttpWorkerRequest)provider.GetService(typeof(HttpWorkerRequest)); // 获取请求正文的大小 long length = long.Parse(request.GetKnownRequestHeader(HttpWorkerRequest.HeaderContentLength)); CheckFileSize(length, upfileConfig); int bytesRead = 0; // 已读数据大小 int readSize; // 当前读取的块的大小 int packSize = 1024 * 10; byte[] buffer; byte[] tempBuff; if (request.IsClientConnected() && !request.IsEntireEntityBodyIsPreloaded()) { buffer = new byte[length]; //http请求正文已被读取的部分 tempBuff = request.GetPreloadedEntityBody(); // 将已读取数据复制过来 Buffer.BlockCopy(tempBuff, 0, buffer, bytesRead, tempBuff.Length); // 开始记录已读取大小 bytesRead = tempBuff.Length; //计算当前上传文件的百分比 long percent = (long)bytesRead * 100 / length; SetPercent(SessionId, percent); int ii = 0; tempBuff = new byte[packSize]; // 循环分块读取,直到所有数据读取结束 while (request.IsClientConnected() && !request.IsEntireEntityBodyIsPreloaded()) { // 分块读取 readSize = request.ReadEntityBody(tempBuff, packSize); // 复制已读数据块 Buffer.BlockCopy(tempBuff, 0, buffer, bytesRead, readSize); // 记录已上传大小 bytesRead += readSize; ii++; if (ii % 30 == 0)//每300kb更新一次进度 { //计算当前上传文件的百分比 percent = (long)bytesRead * 100 / length; SetPercent(SessionId, percent); } if (readSize == 0) { break; } } if (!request.IsEntireEntityBodyIsPreloaded()) { //如果当前状态依然是没有读取完全,通过反射更新预读内容 BindingFlags bindingFlags = BindingFlags.Instance | BindingFlags.NonPublic; Type type = request.GetType(); while (type != null && type.FullName != "System.Web.Hosting.ISAPIWorkerRequest" && type.FullName != "System.Web.Hosting.IIS7WorkerRequest") { type = type.BaseType; } if (type != null) { if (type.FullName == "System.Web.Hosting.ISAPIWorkerRequest") { type.GetField("_contentAvailLength", bindingFlags).SetValue(request, buffer.Length); type.GetField("_contentTotalLength", bindingFlags).SetValue(request, buffer.Length); type.GetField("_preloadedContent", bindingFlags).SetValue(request, buffer); type.GetField("_preloadedContentRead", bindingFlags).SetValue(request, true); } else { type.GetField("_contentTotalLength", bindingFlags).SetValue(request, buffer.Length); type.GetField("_preloadedContent", bindingFlags).SetValue(request, buffer); type.GetField("_preloadedContentRead", bindingFlags).SetValue(request, true); type.GetField("_preloadedLengthRead", bindingFlags).SetValue(request, true); type.GetField("_preloadedLength", bindingFlags).SetValue(request, buffer.Length); } } } } HttpPostedFile imgFile = _request.Files[0]; string fileName = imgFile.FileName; UpLoadFile(result, imgFile, fileName, upfileConfig, SessionId); return result;}catch (Exception ex){ SetPercent(SessionId, 100); result.IsOk = false; result.ErrMsg = ex.Message; return result;} |
Ps: 在不用兼容低版本浏览器的情况下,上传进度已经可以由客户端的JS来完成了。
2、 服务器文件的断点下载
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 | /// <summary>/// 支持断点下载/// </summary>/// <param name="Request"></param>/// <param name="Response"></param>/// <param name="filePath">文件的物理地址</param>private void Down(HttpRequest Request, HttpResponse Response, string filePath){ /*断点下载与普通模式不一样的是: 断点下载的请求头信息里面增加一个属性 RANGE: bytes=100000- 响应头里 增加一个属性 Content-Range=bytes 100000-19999/20000 返回状态码为206(Partial Content) 表示头500个字节:Range: bytes=0-499 表示第二个500字节:Range: bytes=500-999 表示最后500个字节:Range: bytes=-500 表示500字节以后的范围:Range: bytes=500- 第一个和最后一个字节:Range: bytes=0-0,-1 同时指定几个范围:Range: bytes=500-600,601-999 */ // 打开文件 using (Stream fileStream = new FileStream(filePath, FileMode.Open, FileAccess.Read, FileShare.Read)) { // 获取文件的大小 long fileSize = fileStream.Length; string range = Request.Headers["Range"]; Response.Clear(); Response.AddHeader("Accept-Ranges", "bytes"); Response.AddHeader("Connection", "Keep-Alive"); Response.Buffer = false; //数据包大小 int pack = 10240; //10Kb int sleep = 0; if(this.Speed.HasValue) { sleep = (int)Math.Floor(1000.0 * 10 / this.Speed.Value); } long begin = 0; long end = fileSize - 1; if (!string.IsNullOrEmpty(range)) { //获取请求的范围,如果有多个范围,暂时只处理第一个,Range: bytes=500-600,601-999 range = range.Replace("bytes=", ""); range = range.Split(',')[0]; string[] region = range.Split('-'); string startPoint = region[0].Trim(); string endPoint = region[1].Trim(); if (startPoint == "") { long.TryParse(endPoint, out end); begin = fileSize - end; end = fileSize - 1; } else if (endPoint == "") { long.TryParse(startPoint, out begin); end = fileSize - 1; } else { long.TryParse(startPoint, out begin); long.TryParse(endPoint, out end); } Response.StatusCode = 206; Response.AddHeader("Content-Range", string.Format("bytes {0}-{1}/{2}", begin, end, fileSize)); } //以字节流返回数据 Response.ContentType = "application/octet-stream"; Response.AddHeader("Content-Disposition", "attachment; filename=\"" + HttpUtility.UrlEncode(Request.ContentEncoding.GetBytes(this.FileName)) + "\""); long size = end - begin + 1; Response.AddHeader("Content-Length", size.ToString()); // 创建一比特数组 byte[] buffer = new Byte[pack]; fileStream.Position = begin; //设置当前流位置 // 当文件大小大于0是进入循环 while (size > 0) { // 判断客户端是否仍连接在服务器 if (Response.IsClientConnected) { int length = fileStream.Read(buffer, 0, pack); Response.OutputStream.Write(buffer, 0, length); // 将缓冲区的输出发送到客户端 Response.Flush(); size = size - length; if (sleep > 0) { Thread.Sleep(sleep); } } else { //当用户断开后退出循环 size = -1; } } }} |
3、 iis7上传大文件报404错误的解决
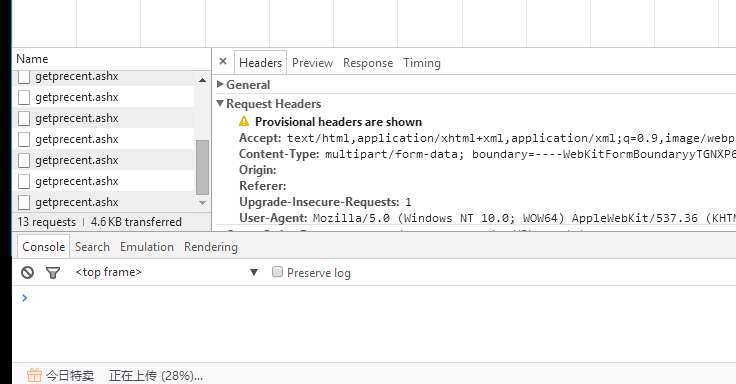
下午测试一个60M的视频文件,报404错误,处理页面里的代码压根没有触发。
请求头里Content-Length属性初始没有出现,就看着360浏览器左下角的百分比一直在涨,到99%后,这个属性才出现,同时抛出404报错信息。
原因是文件超出了 IIS的上传文件大小限制
修改步骤:
1、打开IIS管理器,找到相应的网站。
2、在IIS中双击“请求筛选”打开。
3、点击右边的“编辑功能设置”,打开“编辑请求筛选设置”对话框。
其中的允许的最大容量长度,默认是”30000000“,不到30M。

long length = long.Parse(request.GetKnownRequestHeader(HttpWorkerRequest.HeaderContentLength));
可以正常取到正文大小,从而提前拦截掉太大的文件上传。
但如果文件太大,超出IIS的限制的话,就会出现上面提到的问题,文件会一直上传结束,然后出现404报错。
另外HttpPostedFile的ContentLength属性是int类型,也就是不可能超出整型的上限2147 483 647,大约2G
Web.Config中配置文件大小限制
1 2 3 4 5 6 7 8 9 10 11 12 13 | <system.web> <httpRuntime maxRequestLength="2097151" executionTimeout="5600" useFullyQualifiedRedirectUrl="true" /> </system.web> <system.webServer> <security> <requestFiltering> <requestLimits maxAllowedContentLength="100000000"/> </requestFiltering> </security> </system.webServer> |
4、 大文件的上传
如果不需要读取上传进度的话,直接使用request.Files[0]读取上传文件,IIS是会自动对大文件进行磁盘缓存的。而上面的方法为了读取上传进度,把文件先缓冲到内存里再保存,自然无法支持大文件的上传。而且大文件上传也是需要支持断点续传的,否则用户体验太差。
断点续传一方面需要用户上传的每一个文件在服务器上都有唯一的文件名和它对应,从而方便匹配读取之前的上传进度。
另一方面客户端上传文件前先向服务器请求之前的上传进度,然后跳过已上传的部分再按规则分块将文件一块块传到服务器。也就是需要在用户端直接操作文件读取。



【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek 解答了困扰我五年的技术问题
· 为什么说在企业级应用开发中,后端往往是效率杀手?
· 用 C# 插值字符串处理器写一个 sscanf
· Java 中堆内存和栈内存上的数据分布和特点
· 开发中对象命名的一点思考
· 为什么说在企业级应用开发中,后端往往是效率杀手?
· DeepSeek 解答了困扰我五年的技术问题。时代确实变了!
· 本地部署DeepSeek后,没有好看的交互界面怎么行!
· 趁着过年的时候手搓了一个低代码框架
· 推荐一个DeepSeek 大模型的免费 API 项目!兼容OpenAI接口!