

一。调用链跟踪的必要性
首先我们简单来看一下下单到支付的过程,别的不多说,在业务复杂的时候往往服务会一层接一层的调用,当某一服务环节出现响应缓慢时会影响整个服务的响应速度,由于业务调用层次很“深”,那么在排查问题的时候也会更加困难,如果有一种机制帮我们监控、收集这些服务之间层层调用的时间与逻辑关系是否会助于我们排查问题呢?要解决这个问题。我们就必须借助于分布式服务跟踪系统的力量了
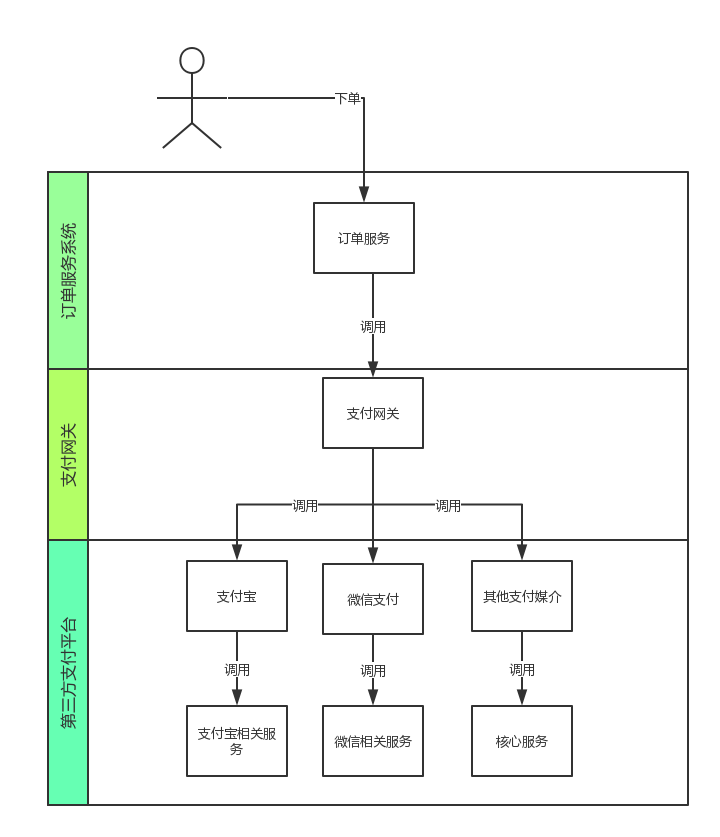
一般的,一个分布式服务跟踪系统,主要有三部分:数据收集、数据存储和数据展示。根据系统大小不同,每一部分的结构又有一定变化。譬如,对于大规模分布式系统,数据存储可分为实时数据和全量数据两部分,实时数据用于故障排查(troubleshooting),全量数据用于系统优化。那么我在贴一张图,此图是spring-cloud-sleuth的概念图:
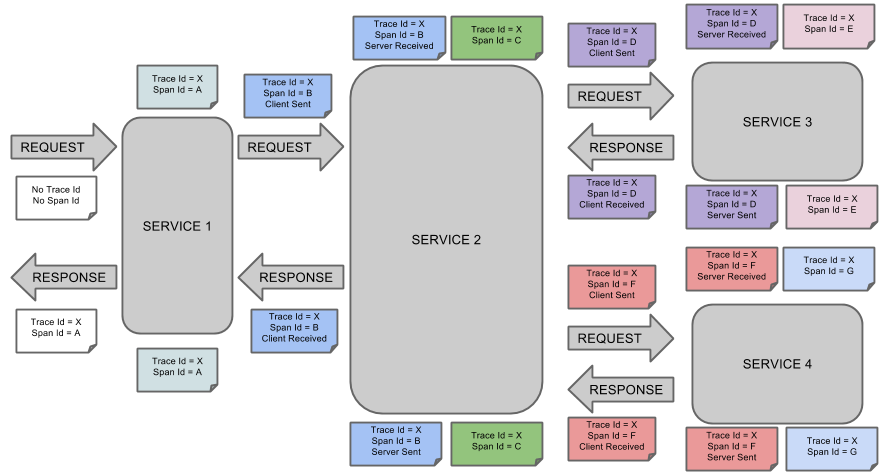
初次看这个图会有点迷糊,因为有一些名词需要大家了解一下
trace:是指我们从服务开始到服务执行的终点的一次完整的请求与相应。
span: 在一次完整的trace过程中,每调用一个服务都会记录调用信息与响应时间,这个就是span
由此我们可以得出一个结论就是:一次trace由若干个span构成,sleuth是用于调用链追踪,通过sleuth我们可以轻易的追踪到trace经过了哪几个服务,每个服务花费的时间等,而zipkin是一个开源的追踪系统,它负责收集,存储数据并展示给用户。Zipkin提供了可插拔数据存储方式:In-Memory、MySql、Cassandra以及Elasticsearch。
二。spring-cloud-sleuth的快速使用
注意SpringCloud的Finchley M8版本的sleuth和zipkin的包还有点冲突,因此我使用Edgware SR2的版本,此版本对应的SpringBoot的版本是1.5.10.RELEASE,我们还是基于以下项目模块构建:
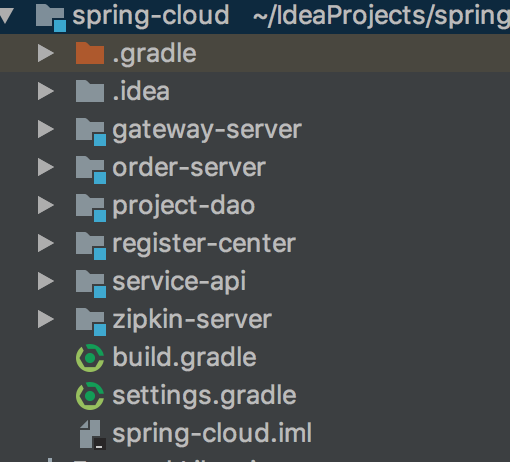
1. 添加启动zipkin服务zipkin-server模块
gradle配置:
dependencies { compile('org.springframework.cloud:spring-cloud-starter-eureka') compile('io.zipkin.java:zipkin-server') compile('io.zipkin.java:zipkin-autoconfigure-ui') }
application.yml配置


server: port: 8200 eureka: client: service-url: defaultZone: http://localhost:8000/eureka spring: application: name: zipkin-server
定义启动类:
package com.hzgj.lyrk.zipkin.server; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springframework.cloud.client.discovery.EnableDiscoveryClient; import zipkin.server.EnableZipkinServer; @EnableZipkinServer @EnableDiscoveryClient @SpringBootApplication public class ZipkinServerApplication { public static void main(String[] args) { SpringApplication.run(ZipkinServerApplication.class, args); } }
当我们启动成功后,访问http://localhost:8200/可以看到如下界面: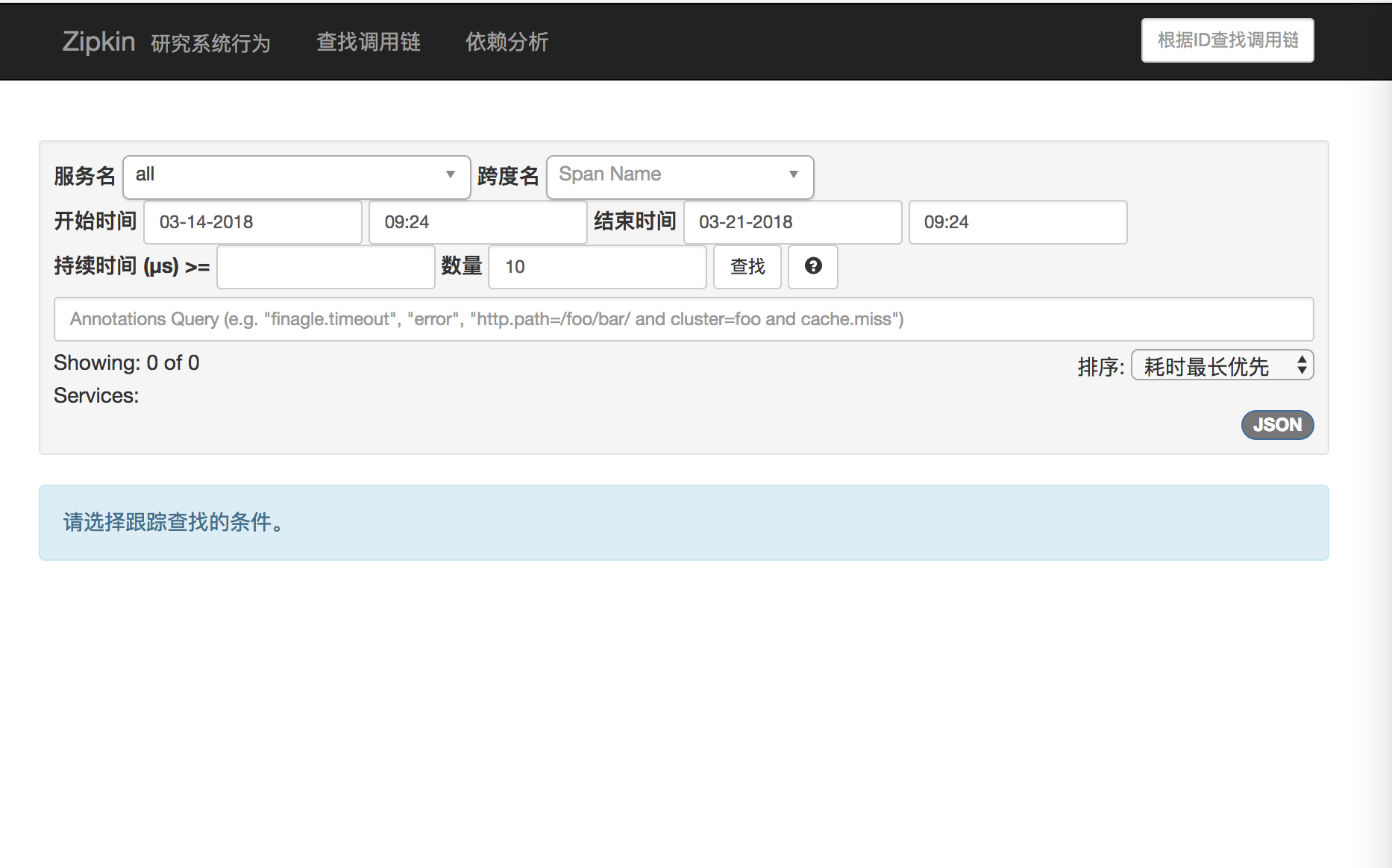
由于我们没有配置监控的服务内容,因此在zipkin里并没有统计数据
2.处理要跟踪的服务模块
tips:在这里gateway-server为网关模块使用zuul来实现,通过网关调用order-server。
分别在要进行服务追踪的模块gateway-server里添加如下依赖:
compile('org.springframework.cloud:spring-cloud-starter-eureka-server')
compile('org.springframework.cloud:spring-cloud-sleuth-zipkin')
compile 'org.springframework.cloud:spring-cloud-starter-sleuth'
在application.yml里的配置:
spring: zipkin: base-url: http://localhost:8200 sleuth: sampler: percentage: 1.0
spring.zipkin.baseUrl是指我们启动的zipkin-server服务地址
spring.sleuth.sampler.percentage 是代表采样率,值越大就代表采样的频率越高 默认为0.1 最大为1.0(即每次请求都进行跟踪)
分别启动gateway-server与order-server并通过gateway-server访问order-server若干次后,我们在通过zipkin查找按钮来访问结果,如下:
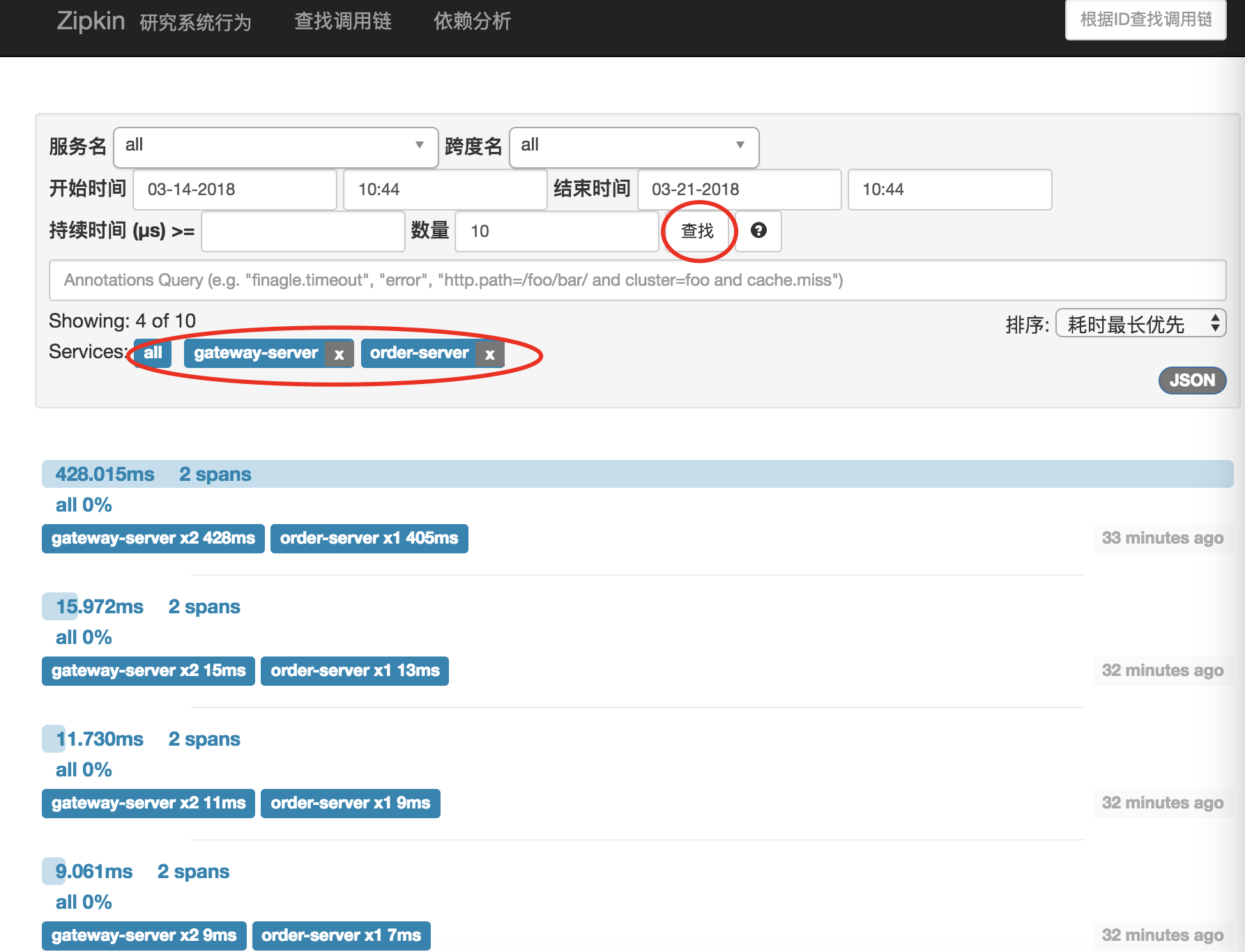
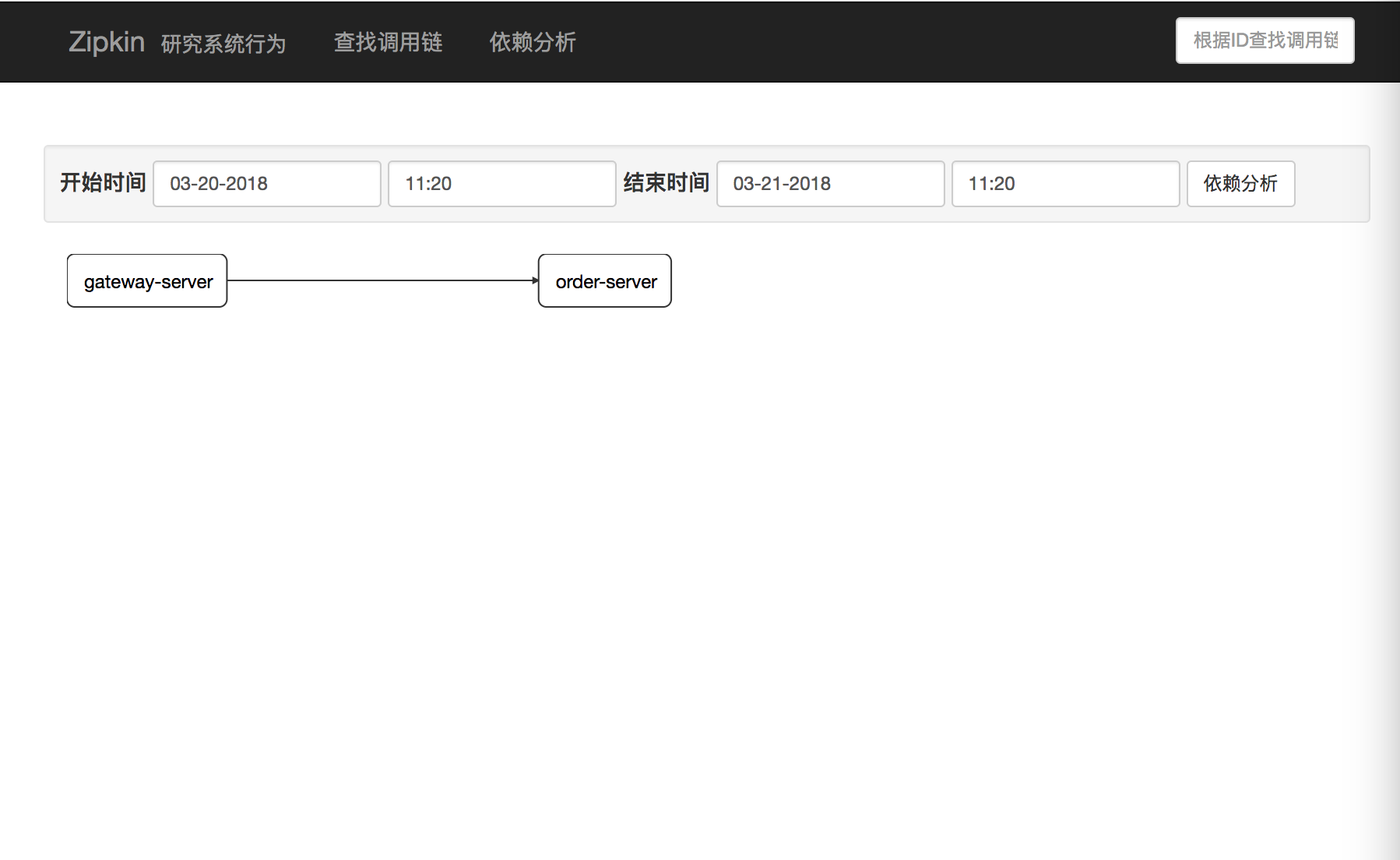
在这里面我们留意几个问题:
1)通过上述的配置,sleuth每次将监控的span通过http请求发送到zipkin-server会浪费一些性能,同时如果zipkin-server出现问题时,数据容易产生丢失
2)在本例当中,数据存到内存当中,数据量过大容易产生OOM错误
在以后的篇幅中会给出这些问题的解决方案。

