



为了形象化,先看几张不同浏览器下下载文件时的效果图:
1:Firefox 36.0.1
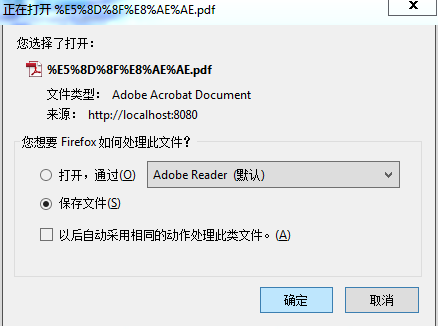
2:IE8
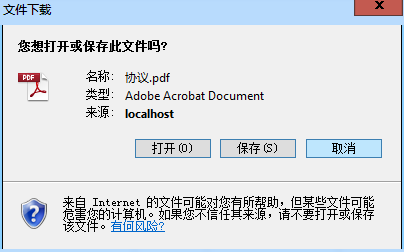
3:Chrome 40.0.2214.93 m
4:360 7.1.1.322

很明显在Firefox下出现了乱码,出现乱码一般是字符集的问题,这是怎么回事呢?为什么其他的浏览器都没有问题呢?看了一下Firefox的字符集是Unicode,改成简体中文看看,发现文件名是不乱了,不过网页的其他部分全乱了,连百度都乱了!如下图所示:


恩,一时我也不知道是什么原因,看看Firefox下的下载文件的响应信息是什么样的,如下图所示:

以前为了防止出现乱码问题,后台的文件名是经过这个转换的(java.net.URLEncoder.encode(fileName, "UTF-8");),证明传递的过程中没有问题,不过为什么其他浏览器在弹出下载对话框的时候没有问题,而Firefox却出现了乱码呢?可能是在弹出对话框的时候处理的方式不一样吧!我们百度看看!
针对这个问题,遇到的人还是不少的,下面是我觉得非常有借鉴作用的资源:
1:这篇博文解释的相当好,值得一看
http://qixinglu.com/post/redisposition.html
2:这一篇也有一定的借鉴意义
http://my.oschina.net/iceman/blog/67541
3:下面是具体解决方案
http://f0rb.iteye.com/blog/1308579
http://www.cnblogs.com/stangray/archive/2010/06/28/1766884.html
http://blog.csdn.net/shixing_11/article/details/5858902
恩,看到这里我相信,不管明白不明白为什么,只要动手实验实验,就能针对自己的情况,找到这个问题的解决方案了,关键就是如何按照要求写
"Content-Disposition","attachment;filename*=utf-8'zh_cn'文件名.xx"
我的解决方式如下(借鉴上面的解决方式):
//仅提供了部分代码,因为我们已经明确问题的所在,知道修改那一部分了,(代码中downloadFileName 即代表*=utf-8'zh_cn'文件名.xx部分)
String agent = (String)getRequest().getHeader("USER-AGENT"); if(agent != null && agent.toLowerCase().indexOf("firefox") > 0) { downloadFileName = "=?UTF-8?B?" + (new String(Base64.encodeBase64(fileName.getBytes("UTF-8")))) + "?="; } else { downloadFileName = java.net.URLEncoder.encode(fileName, "UTF-8"); }
该段代码经我测试,通过了Firefox 36.0.1/IE8/Chrome 40.0.2214.93 m/360 7.1.1.322等浏览器的考验!
Firefox修改后的效果如下所示:

4:如果你感兴趣,英文还不错,可以看看下面的内容
http://greenbytes.de/tech/tc2231/
非常感谢网络上无私的贡献者!
鉴于水平有限难保不会出现错漏之处,如果你觉得那里有错误,请点击一下“反对”按钮,并希望您提出宝贵的修改意见,您的宝贵意见将是我们进步的一大源泉!
如果您觉得阅读上文对您有所帮助,请轻点一下“推荐”按钮,您的“推荐”将是我最大的写作动力!

