
数据归一化Feature Scaling
数据归一化Feature Scaling

当我们有如上样本时,若采用常规算欧拉距离的方法sqrt((5-1)2+(200-100)2), 样本间的距离被‘发现时间’所主导。尽管5是1的5倍,200只是100的2倍。这是由于量纲不同,导致数据不在同一个度量级上。
因此我们需要进行一些数据归一化的处理,将所有的数据映射到同一尺度。
最值归一化:把所有数据映射到0-1之间。
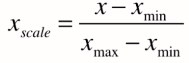
适用于分布有明显边界的情况,缺点是受outlier影响较大。如收入的分布,大多数人是一万,而少部分人月收入是100万。
解决方法出炉(一般都用这种)->
均值方差归一化 standardization: 把所有数据归一到均值为0方差为1的分布中。
数据分布没有明显边界,有可能存在极端数据值时,都可使用这种方法。
 ((特征值 - 均值)/ 方差)
((特征值 - 均值)/ 方差)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号