
机器学习介绍
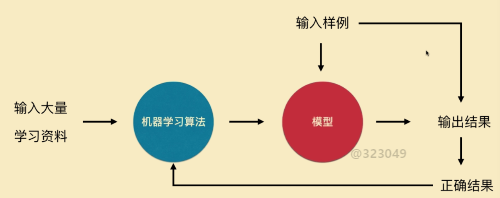
机器学习:让机器去学习

机器学习面对的是高度不确定的世界中的问题
1. 举一个栗子
e.g. 传统垃圾邮件分类问题
传统解决思路:设定规则, 定义“垃圾邮件”, 让计算机去执行规则。
问题:对很多问题规则难以定义,比如识别一只猫或人脸识别。且规则总在不断变化。
新思路:借鉴人类学习的过程,资料->学习归纳总结->知识经验积累->对类似问题做出正确反应
机器学习:

model即f(x)
2. 机器学习的大分类
机器学习的应用:
搜索引擎根据输入的部分关键字联想出你最可能想搜索的内容
浏览商品时,最有可能购买的商品
可能喜欢的音乐,图书,文章
语音识别,人脸识别
医疗诊断,市场分析,金融领域
无人驾驶
宇宙探索,药物研发
标准1:
监督学习supervised learning
训练数据有标记或答案
- 分类任务classification
- 二分类:不是a就是b。e.g. 判断是猫还是狗。银行是否给客户发放信用卡。
- 多分类:多个种类中选一个。e.g.手写数字识别。银行对客户进行信用评级。
一些复杂任务可转换为分类任务,如无人车任务,时刻在方向盘各种角度和刹车/油门深浅的组合中选一个。
-
- 多标签分类:一个东西可属于多个类别。如一张图片既分类到海景又分类到动物。(海边小猫图哈哈)
-
回归任务regression,结果是一个连续数字的值而非类别。
- 如房屋/股票价格,学生成绩。
一些回归问题可以被看成分类问题 --> 将连续数值划分区间成一个个类别。
算法:k近邻,线性回归,多项式回归,逻辑回归,SVM,决策树和随机森林。
非监督学习unsupervised learning
训练数据无标记
- 聚类分析cluster:对无标记数据分类
- 数据降维
- 特征提取:将与结果无关的特征扔掉
- 特征压缩:PCA,尽量少损失信息将高维压成低维->1)提高效率不影响准确率。 2)方便可视化
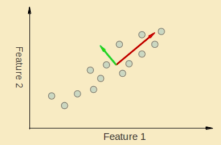
有时特征间的关联特别强,如上图中所有的点都有一个整体的趋势。可将这些点用红线涵盖。此时则将二维压缩为了一维。
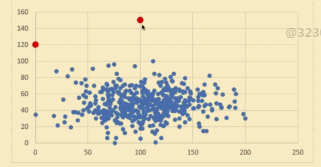
- 异常检测,将与一般数据点相差甚远的点去掉。(还是cluster的思想)
半监督学习semi-supervised learning
一部分数据有标记,另一部分没 --> 现实中更常见,因各种原因缺失数据。
通常先用无监督学习处理数据(使无标签数据因与有标签数据一类而获得标签),再用监督学习手段训练模型做预测。
增强学习reinforcement learning

采取行动->获得反馈(奖赏或惩罚)->改进算法(Agent)->...
通过一轮一轮的行动->反馈的循环中来调整Agent增强自己的智能。
如AlphaGo,机器人,无人驾驶。
标准2:
- 批量学习batch learning/offline learning
- 特点:1)先准备好训练数据,2)模型后续不会再根据新数据来自我优化
- 优:简单
- 缺:如何适应环境变化? -> 问题自身在不断变化。
- 解:定期更新数据库,重新批量学习
- 又缺:1)每次重新,运算量巨大。2)环境变化太快,重训练模型跟不上,如股市每分每秒都在变换
- 需:及时将新数据用于改进模型
- 在线学习online learning
-
- 优:及时跟上环境变化,也适用于数据量太大无法批量学习的环境->一小批小批不断喂给模型
- 缺:新数据带来不好变化? -> 不正常数据
- 解:加强对数据的监控
标准3:
- 参数学习,一旦学到了参数就不再需要原来数据集。如线性回归,假定y=ax+b,求a,b参值。
- 非参数学习,不对模型进行过多假设。非参学习不代表没参数!
3. 数据
数据集data set:数据整体
样本sample:每一行数据
特征feature:每一列数据
标记label:分类
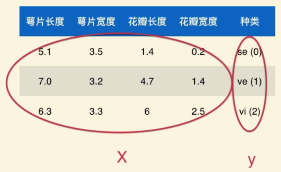

第i个样本:i行;第j个特征值:j列。大写字母表示矩阵(如X),小写字母表示向量(如y)
每一行也是一个向量,称作特征向量X(i)。
行向量:1*n,1行n列
列向量:n*1,n列1行
在数学中通常将向量表示为列向量。因此特征向量X(i)表示为如下形式:

因此上表可表示成如下形式,X(1)T即表示原表中第一行数据:
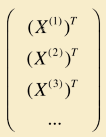
特征空间feature space:由各种特征构成的n维空间(一维到n维),分类任务的本质即切分特征空间。(不同的切分方法即不同机器学习算法的由来)。
tip:有时在高维空间中思考问题太复杂可将其先降到低维空间可视化,得到解决办法再推广到高维空间。难问题拆解为小问题。
特征并不总是很直观,也可以很抽象,如图像的每一个像素点,一个28*28的图=784个特征。
ref:https://github.com/liuyubobobo/Play-with-Machine-Learning-Algorithms

 浙公网安备 33010602011771号
浙公网安备 33010602011771号