InnoDB 存储引擎 Checkpoint 技术
为什么需要重做日志 ?
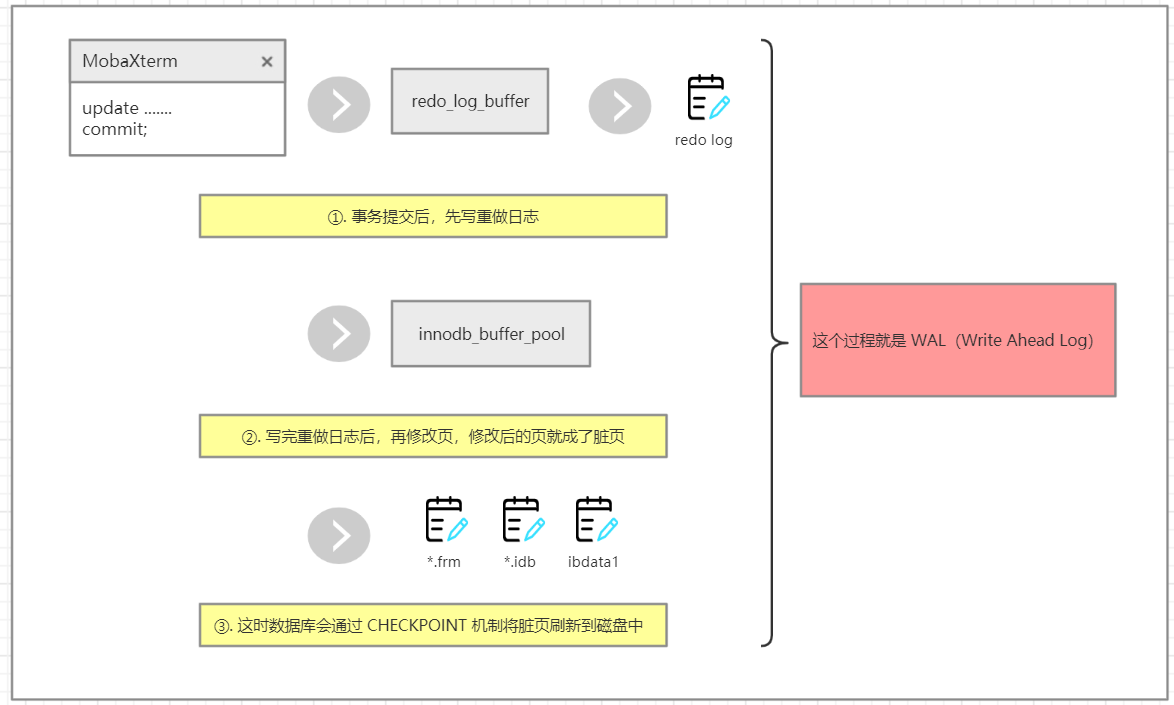
Ⅰ. 倘若产生一个脏页,就立即刷新到磁盘中,那么这个开销是非常大的
Ⅱ. 如果热点数据集中在某几个页中,数据库性能也会非常差
Ⅲ. 如果从缓冲池中刷新脏页到磁盘中时,发生了宕机,数据无法恢复
为了避免数据丢失的问题,当前事务数据库都采用了 Write Ahead Log 策略,
当事务提交时,先写重做日志(redo log),再修改缓冲池中的页(产生脏页)
当发生宕机而导致数据丢失时,通过重做日志完成数据的修复,
这是事务特性 ACID 中,Durability 持久性的要求
当数据库宕机了,重启数据库,都发生了什么?
读取重做日志恢复整个数据库系统中的数据,到宕机发生的时间
有一个场景:
如果缓冲池可以缓存数据库中所有数据,同时,重做日志可以无限扩大
数据库重启时,无需刷新数据到磁盘
因为读取所有的重做日志即可恢复数据,缓冲池中重新缓存了数据库所有数据
但这不切实际,重做日志也许可以无限扩大(仅仅是成本问题)
一般内存不可能缓冲数据库所有数据的(如 3T 数据很常见,但 3T 内存不现实)
CheckPoint 机制起了什么作用 ?
由此引入 CheckPoint 机制,CheckPoint 机制的主要解决以下问题,
①. 缩短数据库的恢复时间
当数据库发生宕机了,数据库无需读取所有的重做日志,执行重做动作,
CheckPoint 之前的重做日志指向的页都已经刷新到磁盘,只需要对 CheckPoint 之后的重做日志进行恢复。
②. 缓冲池不够用时,将脏页刷新到磁盘
当缓冲池不够用时,根据 LRU 算法会溢出最近使用最少的页,如果是脏页,需要强制执行 CheckPoint 机制,将脏页刷新到磁盘
③. 重做日志不可用时,刷新脏页
重做日志不可用,是因为当前数据库对于重做日志的设计都是循环使用的,并不是任其无限增大(成本上难以控制)
重做日志可以被重用的部分,代表着这部分重做日志已经不再被需要
数据库宕机后,重新启动恢复时,数据库恢复操作不需要这部分重做日志,这部分就可以被覆盖利用
如果此时重做日志还需要使用,强制产生 CheckPoint,将缓冲池刷新到当前重做日志的位置
LSN(Log Sequence Number)
LSN 用来标记版本,本质是 8 个字节的数字
每个页都有 LSN ,重做日志中也有 LSN,CheckPoint 也有 LSN
查看 Log sequence number
mysql> show engine innodb status\G
---
LOG
---
Log sequence number 757260660
Log flushed up to 757260660
Pages flushed up to 757260660
Last checkpoint at 757260651
...
CheckPoint 发生的时间、条件、刷新脏页的选择
其实,CheckPoint 机制无外乎将脏页刷新到磁盘
考虑以下问题,
①. 每次 CheckPoint 刷多少页?
②. 每次 CheckPoint 从哪里取脏页?
③. 什么时间触发 CheckPoint 刷脏页动作?
CheckPoint 的种类
Sharp 尖锐 ;Fuzzy 模糊
Sharp CheckPoint
Sharp CheckPoint 发生在数据库关闭时,将所有的脏页都刷新到磁盘,这也是数据库默认的工作方式
Sharp CheckPoint 由 innodb_fast_shutdown = 1 参数控制
数据库运行期间,则不能使用 Sharp CheckPoint,否则影响数据库性能
Fuzzy CheckPoint
- Master Thread CheckPoint
每一秒或者每十秒的速度,从缓冲池脏页列表(Flush List)刷新一定比例的页到磁盘,这个过程是异步的(意思是说,InnoDB 存储引擎可以进行其他操作,用户查询线程不会阻塞)
- Flush_LRU_List CheckPoint
自 MySQL 5.6 版本以后,
InnoDB 存储引擎要保证,LRU 列表中有 1000 个空闲页可用
如果没有 1000 个空闲页可用,那么将 LRU 列表尾端的页移除
如果这些页中有脏页,则需要执行 CheckPoint
因为这些页是来自 LRU 列表的,所以称为 Flush_LRU_List CheckPoint
这个检查由 Page Cleaner 线程进行
可以通过 innodb_lru_scan_depth 控制 LRU 列表中可用页的数量,默认为 1024
# Page Cleaner 线程数控制
mysql> show variables like "%clean%";
+----------------------+-------+
| Variable_name | Value |
+----------------------+-------+
| innodb_page_cleaners | 1 |
+----------------------+-------+
1 row in set (0.00 sec)
# LRU 可用空闲页数量控制
mysql> show variables like "%innodb_%depth%";
+-----------------------+-------+
| Variable_name | Value |
+-----------------------+-------+
| innodb_lru_scan_depth | 1024 |
+-----------------------+-------+
1 row in set (0.01 sec)
- Async/Sync Flush CheckPoint
重做日志不可用时(一般 InnoDB 存储引擎重做日志是循环利用的),需要强制将一些页刷新回磁盘
此时脏页是从脏页列表(Flush List)中选取的(具体请见书中 35 页)
总之,Async/Sync Flush CheckPoint 是为了保证重做日志的循环使用的可用性
在 MySQL 5.6 版本以前,Async Flush CheckPoint 会阻塞发现问题的用户查询线程,Sync Flush CheckPoint 会阻塞所有的用户查询线程,并等待脏页刷新完成
MySQL 5.6 版本之后,这部分刷新操作单独放入了 Page Cleaner 线程中,不会阻塞用户查询线程
- Dirty page too much CheckPoint
脏页数量太多,导致 InnoDB 存储引擎强制执行 CheckPoint
为了保证缓冲池中有足够的可用的页
可以由参数 innodb_max_dirty_pages_pct 控制
# 如下,当缓存中脏页数量占据 75% 时,强制执行 CheckPoint,
# 即刷新一部分脏页到磁盘
mysql> show variables like "innodb_max_dirty_pages_pct";
+----------------------------+-----------+
| Variable_name | Value |
+----------------------------+-----------+
| innodb_max_dirty_pages_pct | 75.000000 |
+----------------------------+-----------+
1 row in set (0.00 sec)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号