InnoDB 存储引擎的后台线程与内存分配
InnoDB 体系结构
先参考 InnoDB 的内存结构 和 InnoDB 的磁盘文件结构
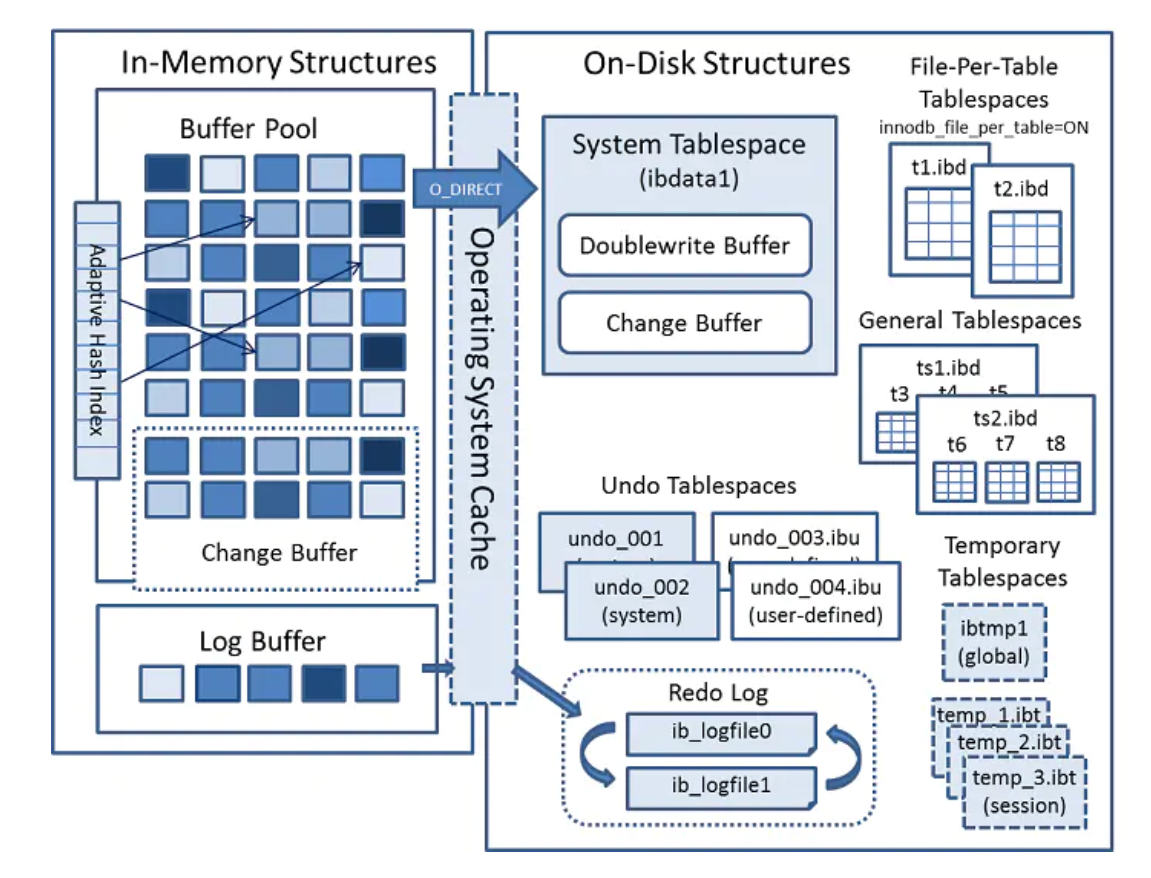
InnoDB 后台线程
InnoDB 存储引擎是多线程模型,后台有多个不同的后台线程
- Master Thread - 核心线程,主要负责将缓冲池中的数据异步刷新到磁盘,保证数据一致性
- IO Thread - 负责 AIO (Async IO) 请求回调处理
- insert buffer thread - 先写 buffer
- log thread - 再写 log
- read thread - 然后读 IO 线程
- write thread - 最后写 IO 线程
> show engine innodb status\G
...
--------
FILE I/O
--------
I/O thread 0 state: waiting for completed aio requests (insert buffer thread)
I/O thread 1 state: waiting for completed aio requests (log thread)
I/O thread 2 state: waiting for completed aio requests (read thread)
I/O thread 3 state: waiting for completed aio requests (read thread)
I/O thread 4 state: waiting for completed aio requests (read thread)
I/O thread 5 state: waiting for completed aio requests (read thread)
I/O thread 6 state: waiting for completed aio requests (write thread)
I/O thread 7 state: waiting for completed aio requests (write thread)
I/O thread 8 state: waiting for completed aio requests (write thread)
I/O thread 9 state: waiting for completed aio requests (write thread)
Pending normal aio reads: [0, 0, 0, 0] , aio writes: [0, 0, 0, 0] ,
ibuf aio reads:, log i/o's:, sync i/o's:
Pending flushes (fsync) log: 0; buffer pool: 0
306 OS file reads, 55 OS file writes, 9 OS fsyncs
0.00 reads/s, 0 avg bytes/read, 0.00 writes/s, 0.00 fsyncs/s
...
----------------------------
END OF INNODB MONITOR OUTPUT
============================
1 row in set (0.01 sec)
# 默认是 4 个 read io 线程 和 write io 线程
mysql> show variables like "innodb_%io%_threads"\G
*************************** 1. row ***************************
Variable_name: innodb_read_io_threads
Value: 4
*************************** 2. row ***************************
Variable_name: innodb_write_io_threads
Value: 4
2 rows in set (0.00 sec)
- Purge Thread - 事务被提交后,其所使用的 undolog 可能不再需要,回收已分配的 undo 页
mysql> show variables like "innodb_purge_threads"\G
*************************** 1. row ***************************
Variable_name: innodb_purge_threads
Value: 4
1 row in set (0.00 sec)
# 配置文件
[mysqld]
innodb_purge_threads=4
# Purge Thread 需要离散的读取 undo 页, 多个 Purge Thread 可以加速回收
- Page Cleaner Thread - 从 buffer pool 中刷新脏页
# 5.6 版本以前,脏页的清理工作交由 master 线程的
# 5.6.2 版本引入该线程(单线程)
# 5.7 版本后支持多线程刷新脏页
# 查看该线程的数量
mysql> show variables like "%cleaners%";
+----------------------+-------+
| Variable_name | Value |
+----------------------+-------+
| innodb_page_cleaners | 1 |
+----------------------+-------+
1 row in set (0.00 sec)
# 配置 my.cnf 默认是 1 最大可以是 64
innodb_page_cleaners=$num
脏页(内存页)
当内存数据页跟磁盘数据页内容不一致的时候,我们称这个内存页为“脏页” 。
内存数据写入到磁盘后,内存和磁盘上的数据页的内容就一致了,称为“干净页” 。
平时很快的更新操作,都是在写内存和日志,他并不会马上同步到磁盘数据,这时内存数据页跟磁盘数据页内容不一致,我们称之为“脏页” 。
一条 SQL 语句,正常执行的时候特别快,偶尔很慢。那这时候可能就是在将脏页同步到磁盘中了 。
刷脏页的时机
什么时候会引起将脏页刷新同步到磁盘中?
(1) 当 redo log写满了。这时候系统就会停止所有的更新操作,将更新的这部分日志对应的脏页同步到磁盘中,此时所有的更新全部停
止,此时写的性能变为0,必须待刷一部分脏页后才能更新,这时就会导致 sql语句 执行的很慢 。
(2) 也可能是系统内存不足时,需要将一部分数据页淘汰掉,如果淘汰的是脏页,则需要先将脏页同步到磁盘,空出来的给别的数据页使用 。
(3) MySQL 认为系统“空闲”的时候,反正闲着也是闲着反正有机会就同步到磁盘一些数据 。
(4) MySQL 正常关闭。这时候,MySQL 会把内存的脏页都同步到磁盘上,这样下次 MySQL 启动的时候,就可以直接从磁盘上读数据,启动速度会很快 。
脏页满了会造成的影响
1 如果是 redo log buffer 写满了
尽量要避免的。因为出现这种情况的时候,整个系统就不能再接受更新了,所有的更新都都会停止。此时写的性能变为 0,必须待刷一部分脏页后才能更新,这时就会导致 sql语句 执行的 很慢
2 内存不够用了
常态,正常
InnoDB 内存分配
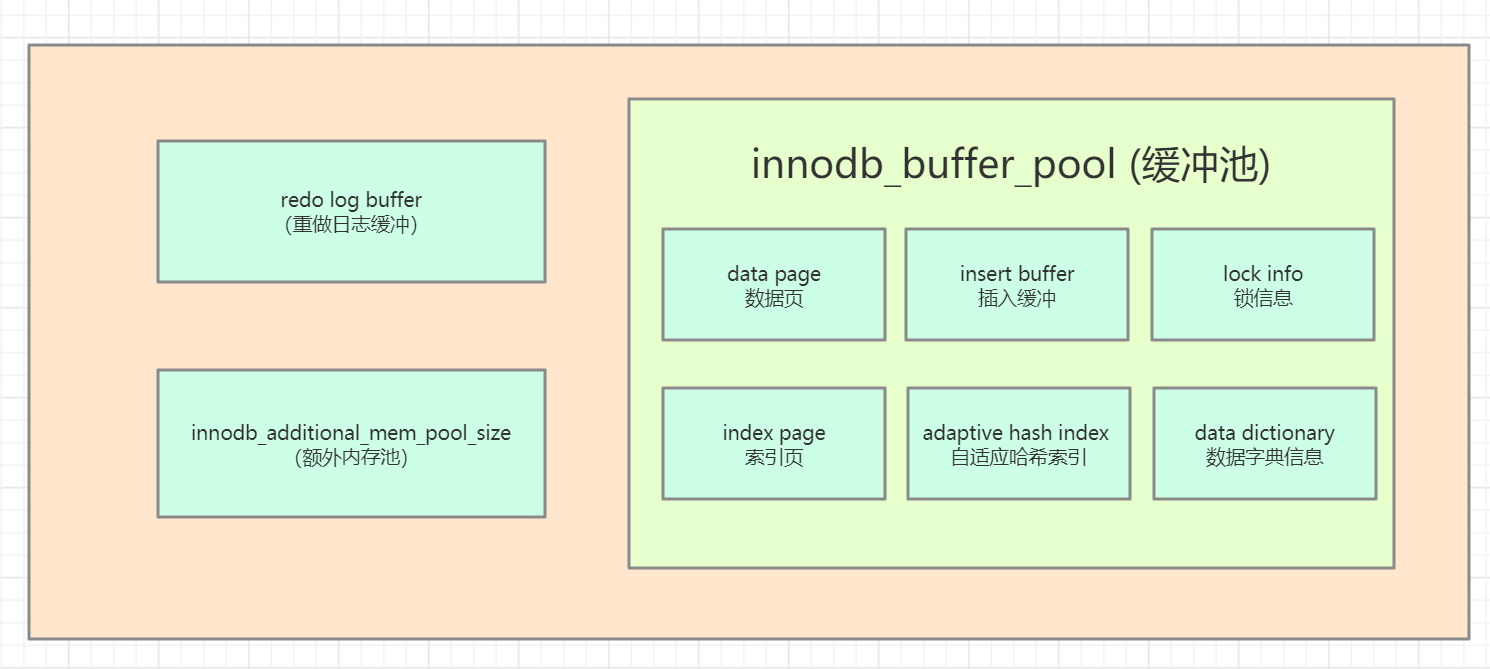
一. 缓冲池(innodb_buffer_pool)
- InnoDB 存储引擎基于磁盘存储,并将其中的记录按照页的方式进行管理 。是基于磁盘的数据库系统
- 缓冲池就是一片内存区域,通过内存的速度弥补磁盘速度对于数据库性能的影响
- 在数据库中读取页时:
- 首先,将磁盘中的页 => 放入内存中 (这个过程称为将页 FIX 在缓冲池中)
- 下次若是读相同页,判断该页是否在内存中,若在缓冲池中,则该页在缓冲池被命中
- 若不在缓冲池中,读取磁盘上的数据页
# 查看缓冲池大小,byte 单位
mysql> show variables like 'innodb_buffer_pool_size';
+-------------------------+-----------+
| Variable_name | Value |
+-------------------------+-----------+
| innodb_buffer_pool_size | 134217728 |
+-------------------------+-----------+
1 row in set (0.00 sec)
mysql> select 134217728/1024/1024;
+---------------------+
| 134217728/1024/1024 |
+---------------------+
| 128.00000000 |
+---------------------+
1 row in set (0.00 sec)
二. 重做日志缓冲(redo_log_buffer)
三. 额外内存池(innodb_additional_mem_pool_size)
LRU List && Free List
LRU List
通常来说,数据库中的缓冲池是通过 LRU (Lastest Recent Used,最近最少使用)算法维护的,最少使用的页在 LRU 列表的尾端,当缓冲池中,不能存放新读取到的页时,将首先释放 LRU 列表中尾端的页
在 InnoDB 存储引擎中,缓冲池中默认页面大小 16KB ,同样使用 LRU 算法对缓冲池进行处理
但是,InnoDB 存储引擎对于传统的 LRU 算法做了一些优化
最新访问的页,不放在 LRU 列表的首部,而放在 LRU 列表的 midpoint 位置,这个算法在 InnoDB 存储引擎中称为 midpoint insertion strategy 。默认配置下,这个位置在 LRU 列表长度 5/8 的位置,midpoint 的位置由 innodb_old_blocks_pct 控制,该值默认是 37,表示距离 LRU 尾端 37% 的位置(即离尾端 3/8 的位置),midpoint 之前的数据是 new 的数据,midpoint 之后的数据是 old 的数据 。
# 查看 midpoint 位置
mysql> show variables like "innodb_old_blocks_pct";
+-----------------------+-------+
| Variable_name | Value |
+-----------------------+-------+
| innodb_old_blocks_pct | 37 |
+-----------------------+-------+
1 row in set (0.00 sec)
为什么不采用朴素的 LRU 算法?
若直接将读取到的数据放到 LRU 列表的首部,某些 SQL 操作会使缓冲池中的大量的页被刷出
某些 SQL 操作:索引或者数据的扫描操作,这类操作会访问表中的许多页,甚至全部的页,这些页通常只是此次查询操作中需要的,并不是活跃的热点数据
如果放到 LRU 列表首部,那 LRU 列表中的活跃的热点数据可能被刷出(LRU 中 new 的部分的数据),下一次读取该页时,还需要访问磁盘
为了解决这个问题,InnoDB 存储引擎引入了另外一个参数管理 LRU 列表
# innodb_old_blocks_time
# 放在冷热数据交界处(实际上在冷数据的范围中),默认 1000 ms,过了这 1 s,还能存活下去,就调到热数据区了
mysql> show variables like "innodb_old_blocks_time";
+------------------------+-------+
| Variable_name | Value |
+------------------------+-------+
| innodb_old_blocks_time | 1000 |
+------------------------+-------+
1 row in set (0.00 sec)
# 这个参数的作用是,当磁盘中的页 FIX 到缓冲池中的 LRU 列表 midpoint 后,
# 等待多久才放入 LRU 列表的热端(new 部分,默认是 LRU 列表的前 5/8 部分)
# ========== 如果有扫描数据或索引的 SQL 操作,可以按以下操作使 LRU 列表中的热点数据不被刷出
mysql> set @@global.innodb_old_blocks_time=10000;
Query OK, 0 rows affected (0.00 sec)
mysql> -- 数据或索引的扫描操作
mysql> -- ......
mysql> -- 数据或索引的扫描操作
mysql> set @@global.innodb_old_blocks_time=1000;
Query OK, 0 rows affected (0.00 sec)
# 这样 LRU 列表中被刷出的数据只能是尾端的 37% 的数据
# 如果用户预估自己的热点数据不止 63% ,那么可以通过设置 innodb_old_blocks_pct 保留更多的热点数据
mysql> set @@global.innodb_old_blocks_pct=20;
Query OK, 0 rows affected (0.00 sec)
mysql> show variables like "innodb_old_blocks_pct";
+-----------------------+-------+
| Variable_name | Value |
+-----------------------+-------+
| innodb_old_blocks_pct | 20 |
+-----------------------+-------+
1 row in set (0.00 sec)
Free List
LRU 列表用来管理已经读取的页,
当数据库刚刚启动,LRU 列表是空的,没有任何的页
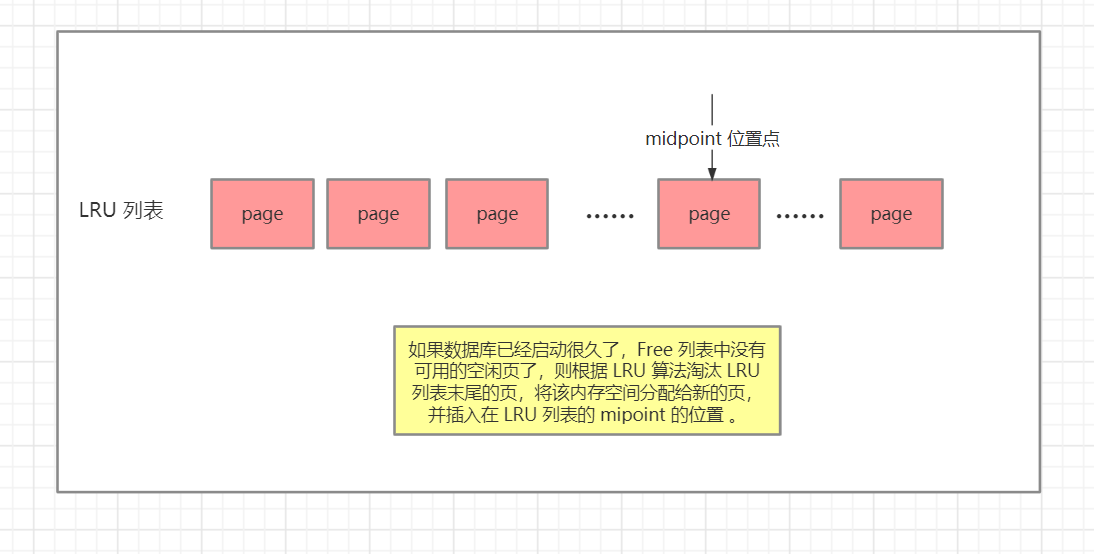
这时页都存在 Free 列表中,当需要从缓冲池分页时,首先从 Free 列表中查找是否有可用的空闲页,如果有则将该页从 Free 列表中删除,放入到 LRU 列表中 。

如果数据库已经启动很久了,Free 列表中没有可用的空闲页了,则根据 LRU 算法淘汰 LRU 列表末尾的页,将该内存空间分配给新的页,并插入在 LRU 列表的 mipoint 的位置 。
当页从 LRU 列表的 old 部分加入到 new 部分时(升级为热数据),称此时发生的操作为 page made young
因为 innodb_old_blocks_time 的设置(5.7.22 中默认为 1000),没有从 old 部分移动到 new 部分的操作称为 page not made young 。
可以通过 SHOW ENGINE INNODB STATUS\G 来观察 LRU 列表和 Free 列表的使用情况和运行状态
# Free buffers Free 列表中页的数量
# Database pages LRU 列表中页的数量
mysql> show engine innodb status\G
...
----------------------
BUFFER POOL AND MEMORY
----------------------
Total large memory allocated 137428992
Dictionary memory allocated 428931
Buffer pool size 8191
Free buffers 1024 ---------------------------- Free 列表中页的数量
Database pages 6724 ---------------------------- LRU 列表中页的数量
Old database pages 2462
Modified db pages 0
Pending reads 0
Pending writes: LRU 0, flush list 0, single page 0
Pages made young 293, not young 394091
0.00 youngs/s, 0.00 non-youngs/s
Pages read 10165, created 58, written 103
0.00 reads/s, 0.00 creates/s, 0.00 writes/s
No buffer pool page gets since the last printout
Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s
LRU len: 6724, unzip_LRU len: 0
I/O sum[0]:cur[0], unzip sum[0]:cur[0]
...
----------------------------
END OF INNODB MONITOR OUTPUT
============================
1 row in set (0.01 sec)
可以计算出,Free buffers + Database pages 不等于 Buffer pool size 的页的数量
因为缓冲池中的页,也会被分配给自适应哈希索引(adaptive hash index)、锁信息(lock info)、插入缓冲(insert buffer)使用
而这部分页不需要 LRU 算法维护,所以不存在于 LRU 列表中
pages_made_young 和 pages_not_made_young
pages_made_young : 当 old 部分的页移动到 new 部分时,就是一次 pages_made_young 操作
pages_not_made_young : 当 old 部分的页由于 innodb_old_blocks_time (在这个时间段内,有更多新页插入到 old 部分中,该页被淘汰)没有从 old 部分移动到 new 部分,就是一次 page_not_made_young 操作
# 如何监控这两个操作?
mysql> show engine innodb status\G
...
----------------------
BUFFER POOL AND MEMORY
----------------------
...
Pages made young 293, not young 394091 -------------- 总次数
0.00 youngs/s, 0.00 non-youngs/s -------------------- 速率
...
# =============== youngs/s 和 non-youngs/s ================ #
# youngs/s:坚持到了 1 s,进入了热数据区
# non-youngs/s:没有坚持到 1 s,于是被刷出去了
non-youngs/s 的值过大原因
- 可能存在严重的全表扫描(频繁的被刷出来)
- 可能是 innodb_old_blocks_pct 设置的过小(冷数据区就很小,来一点数据就刷出去了)
- 可能是 innodb_old_blocks_time 设置的过大(没坚持到 10000 s,被刷出去了)
youngs/s 的值过大原因
正常不可能一直很高,因为热数据区就那么大,不可能一直往里调
- innodb_old_blocks_pct 设置过大(pct 过大,冷区大,热区小,time 过小,就容易 young 进去)
- innodb_old_blocks_time 设置过小
hit_rate 变量
# hit_rate 表示缓冲池的命中率,如果是 1000 即 100% 代表缓冲池运行状态很好
# 如果小于 950 需要观察是否是因为全表扫描引起的 LRU List 污染问题
mysql> select pool_id,hit_rate,pages_made_young,pages_not_made_young from information_schema.innodb_buffer_pool_stats;
+---------+----------+------------------+----------------------+
| pool_id | hit_rate | pages_made_young | pages_not_made_young |
+---------+----------+------------------+----------------------+
| 0 | 1000 | 5594 | 1248 |
+---------+----------+------------------+----------------------+
1 row in set (0.02 sec)
mysql> show variables like "innodb_old_blocks_time";
+------------------------+-------+
| Variable_name | Value |
+------------------------+-------+
| innodb_old_blocks_time | 1000 |
+------------------------+-------+
1 row in set (0.03 sec)
LRU 列表中每个页的具体信息
# 查询 innodb_buffer_page_lru 表中 SPACE = 1 的表的页的信息
mysql> select table_name,space,page_number,page_type from information_schema.innodb_buffer_page_lru where space=23 ;
+--------------------+-------+-------------+-------------------+
| table_name | space | page_number | page_type |
+--------------------+-------+-------------+-------------------+
| NULL | 23 | 0 | FILE_SPACE_HEADER |
| NULL | 23 | 1 | IBUF_BITMAP |
| NULL | 23 | 2 | INODE |
| `ethan`.`count_t1` | 23 | 3 | INDEX |
+--------------------+-------+-------------+-------------------+
4 rows in set (0.00 sec)
LRU 列表中的非 16KB 页
InnoDB 支持压缩页的功能,将 16KB 大小的页压缩成 1KB/2KB/4KB/8KB ,那么非 16KB 的页在 LRU 列表中怎么管理?
# SHOW ENGINE INNODB STATUS\G
----------------------
BUFFER POOL AND MEMORY
----------------------
.......
LRU len: 6724, unzip_LRU len: 150
I/O sum[0]:cur[0], unzip sum[0]:cur[0]
.......
# InnoDB 支持压缩页,unzip_LRU 管理者压缩页
# LRU 列表一共有 6724 个页,其中非 16 KB 的页有 150 个
# unzip_LRU len 是包含在 LRU len 里的
首先,在 unzip_LRU 列表中,对于不同大小的压缩页,也是分别管理的。
其次,通过伙伴算法进行内存的分配,例如申请 4KB 的 LRU 列表压缩页,其过程如下,
① 检查 4KB 的 unzip_LRU 列表,检查是否有可用的空闲页
② 如果有,则直接用
③ 否则,检查 8KB 的 unzip_LRU 列表
④ 如果能得到空闲的 8KB 页,将页分成 2 个 4KB 页,存到 4KB 的 unzip_LRU 列表
⑤ 如果不能得到空闲的 8KB 页,从 LRU 列表中申请一个 16KB 的页
⑥ 将申请到的 16KB 页分为 1 个 8KB 页,两个 4KB 页
⑦ 得到的 1 个 8KB 页存入 8KB 的 LRU 列表,2 个 4KB 页存入 4KB 的 LRU 列表
# 同样可以从 innodb_buffer_page_lru 表中观察 unzip_LRU 列表
mysql> select table_name,space,page_number,compressed_size from information_schema.innodb_buffer_page_lru where compressed_size <> 0;
Flush List
在 LRU 列表中的页被修改后,称该页为脏页(dirty page)
即缓冲池中的页和磁盘上的页数据不一致
这时数据库会通过 CHECKPOINT 机制将脏页刷新到磁盘中
Flush 列表就是脏页列表,脏页既存在于 LRU 列表,也存在于 Flush 列表
LRU 列表用来管理缓冲池中页的可用性,Flush 列表用来管理将页刷新到磁盘
二者互不影响
# 同 LRU 列表一样, Flush 列表也可以通过
# SHOW ENGINE INNODB STATUS\G 查看
# Modified db pages ------- 脏页的数量
----------------------
BUFFER POOL AND MEMORY
----------------------
Total large memory allocated 137428992
Dictionary memory allocated 111567
Buffer pool size 8191
Free buffers 7665
Database pages 525
Old database pages 122
Modified db pages 194
.......
非生产环境下模拟数据插入后,脏页刷新,想要上面数据看得见 Modified db pages 的变化,可以执行下面存储过程
# 建立测试表
create table onebillion (id int,name varchar(12));
# 定义存储过程
delimiter $$
create procedure sp_onebillion_tbl()
begin
declare num int;
set num=1;
repeat
insert into onebillion values(num,CONCAT('ethanz_',num));
commit;
set num = num + 1;
until num > 1000000 end repeat;
end$$
delimiter ;
# 模拟数据插入
call sp_onebillion_tbl();
因为,脏页同样的存在于 LRU 列表中,所以可以通过元数据表 innodb_buffer_page_lru 查看脏页的信息
# 需要加入 oldest_modification > 0 的条件,table_name 是 null 的代表系统表空间
mysql> select table_name,space,page_number,compressed_size,oldest_modification from information_schema.innodb_buffer_page_lru where oldest_modification >0 limit 5;
+------------+-------+-------------+-----------------+---------------------+
| table_name | space | page_number | compressed_size | oldest_modification |
+------------+-------+-------------+-----------------+---------------------+
| NULL | 0 | 309 | 0 | 141970599 |
| NULL | 0 | 329 | 0 | 141684317 |
| NULL | 0 | 310 | 0 | 141960100 |
| NULL | 0 | 311 | 0 | 141960224 |
| NULL | 0 | 330 | 0 | 141688209 |
+------------+-------+-------------+-----------------+---------------------+
5 rows in set (0.01 sec)
mysql> select table_name,space,page_number,compressed_size,oldest_modification from information_schema.innodb_buffer_page_lru where oldest_modification >0 limit 300,5;
+-----------------------+-------+-------------+-----------------+---------------------+
| table_name | space | page_number | compressed_size | oldest_modification |
+-----------------------+-------+-------------+-----------------+---------------------+
| `ethan`.`onethousand` | 29 | 3362 | 0 | 144187930 |
| `ethan`.`onethousand` | 29 | 3363 | 0 | 144227982 |
| `ethan`.`onethousand` | 29 | 3364 | 0 | 144268033 |
| `ethan`.`onethousand` | 29 | 3365 | 0 | 144308074 |
| `ethan`.`onethousand` | 29 | 3366 | 0 | 144348126 |
+-----------------------+-------+-------------+-----------------+---------------------+
5 rows in set (0.02 sec)
重做日志缓冲(redo log buffer)
InnoDB 存储引擎首先将重做日志先放入到这个 redo_log_buffer 缓冲区,然后按一定频率将其刷新到重做日志文件
重做日志缓冲一般不宜设置过大,因为一般情况下,每一秒钟都会将重做日志缓冲刷新到日志文件,因此用户只需要保证每秒产生的事务量在这个缓冲大小之内即可。
# 可以配置参数 innnodb_log_buffer_size
mysql> show variables like "innodb_log_buffer_size";
+------------------------+----------+
| Variable_name | Value |
+------------------------+----------+
| innodb_log_buffer_size | 16777216 |
+------------------------+----------+
1 row in set (0.00 sec)
16MB 其实足以满足绝大部分应用,因为重做日志在下列三种情况下,会将重做日志缓冲中的内容。刷新到尾部磁盘中的日志文件
①. Master Thread 每一秒,会将重做日志缓冲,刷新到重做日志文件
②. 每个事务提交时,会将重做日志缓冲,刷新到重做日志文件
③. 重做日志缓冲剩余空间小于 1/2 时,会将重做日志缓冲,刷新到重做日志文件
额外的内存池(innodb_additional_mem_pool_size)
InnoDB 存储引擎对于内存的管理是通过内存堆(heap)的方式进行的
对于数据结构本身的内存进行分配时,需要在额外的内存池申请,当该区域内存不够时,则从缓冲池申请
举个例子,每个缓冲池中的帧缓冲(frame buffer),有对应的缓冲控制对象(buffer control block)
这个对象记录了 LRU、锁、等待等信息
这个对象需要从额外的内存池中申请
因此,在申请了较大的缓冲池的时候,也要适宜的增加额外的内存池的大小

