【Flink】使用之前,先简单了解一下Flink吧!
Flink简单介绍
概述
在使用Flink之前,我们需要大概知道Flink是什么?
首先,从Flink的官网可以有一个简单的了解:Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。
这里了解过大数据的可以看到几个熟悉的词,分布式处理、内存计算,首先分布式处理是大数据集群最常见的,也是必备的处理方式,其次,内存计算也不难让人想到现在很火的Spark,至少通过这个词肯定可以联想到Flink处理任务的速度一定也很快。
那么,什么是无边界和有边界数据流呢?
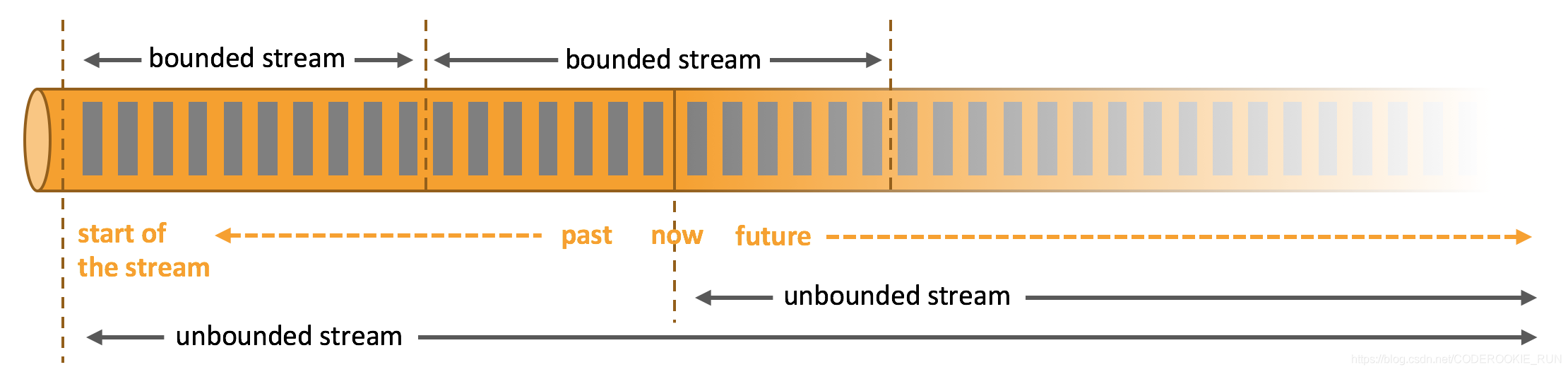
无边界数据流和有边界数据流
- 无边界数据流 | Unbounded Stream
官方的定义:有定义流的开始,但没有定义流的结束。它们会无休止地产生数据。无界流的数据必须持续处理,即数据被摄取后需要立刻处理。我们不能等到所有数据都到达再处理,因为输入是无限的,在任何时候输入都不会完成。处理无界数据通常要求以特定顺序摄取事件,例如事件发生的顺序,以便能够推断结果的完整性。 - 有边界数据流 | Bounded Stream
官方的定义:有定义流的开始,也有定义流的结束。有界流可以在摄取所有数据后再进行计算。有界流所有数据可以被排序,所以并不需要有序摄取。有界流处理通常被称为批处理。
技术栈核心组成
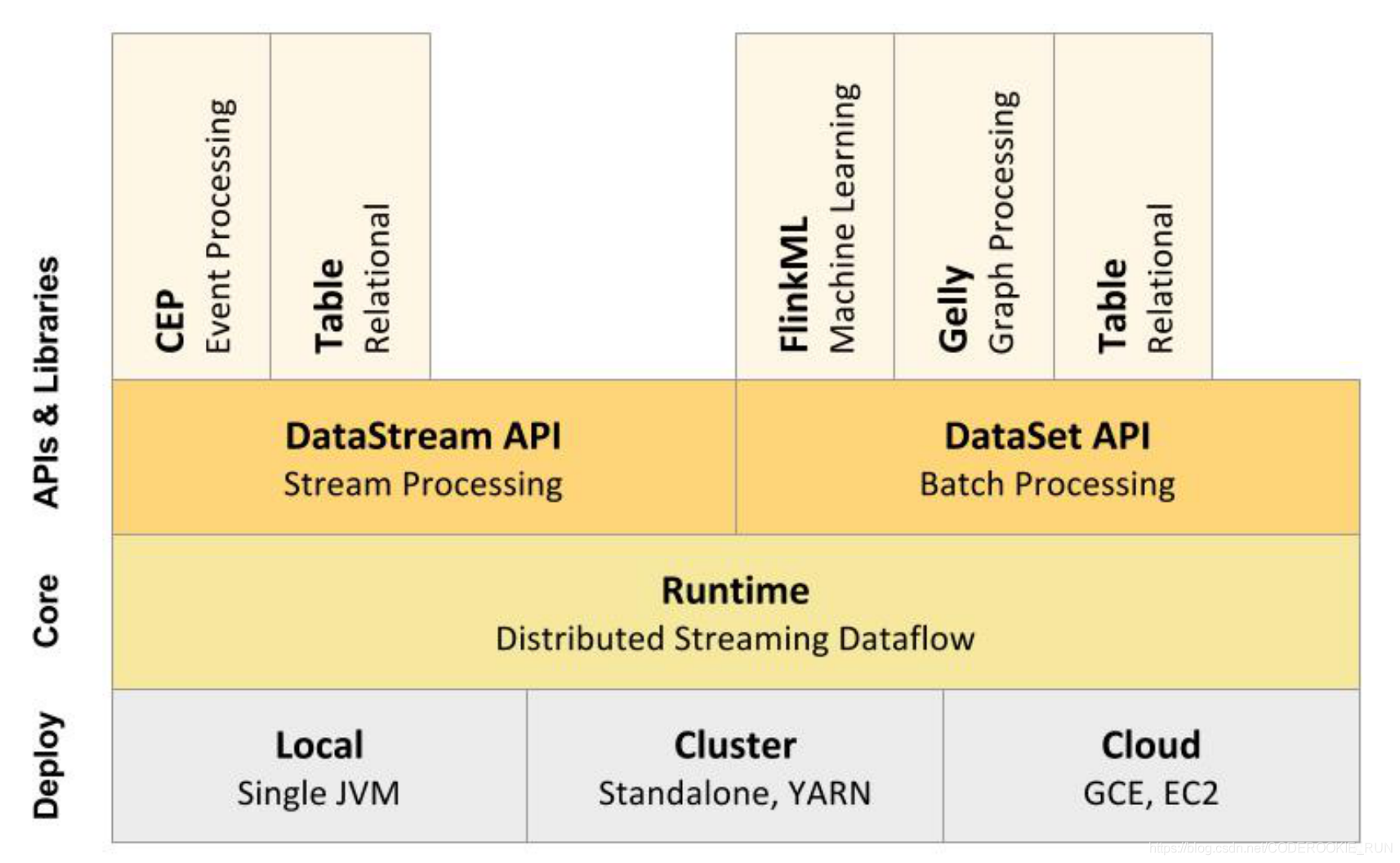
从上图可以看出,底层是Flink的集群部署选择,不仅可以运行在包括 YARN、 Mesos、Kubernetes 在内的多种资源管理框架上,还支持在裸机集群上独立部署。在启用高可用选项的情况下,它不存在单点失效问题。
核心计算架构是Runtime执行引擎,它是一个分布式系统,能够接 受数据流程序并在一台或多台机器上以容错方式执行。
DataStream API用于流处理,DataSet API用于批处理。
- 流处理特性
1.支持高吞吐、低延迟、高性能的流处理
2.支持带有事件时间的窗口(Window)操作
3.支持有状态计算的 Exactly-once 语义
4.支持高度灵活的窗口(Window)操作,支持基于 time、count、session,以及 data-driven 的窗口操作
5.支持具有 Backpressure 功能的持续流模型
6.支持基于轻量级分布式快照(Snapshot)实现的容错
7.一个运行时同时支持 Batch on Streaming 处理和 Streaming 处理
8.Flink 在 JVM 内部实现了自己的内存管理
9.支持迭代计算
10.支持程序自动优化:避免特定情况下 Shuffle、排序等昂贵操作,中间结果有必要进行缓存 - 批处理特性
1.有界、持久、大量
2.适合需要访问全套记录才能完成的计算工作,一般用于离线统计
Flink和Spark有一点最明显的不同,就是 Spark应对批处理和流处理采用了不同的技术框架,批处理由SparkSQL实现,流处理由Spark Streaming实现。Flink则可以做到同时实现批处理和流处理, 它的解决办法就是将批处理(即处理有限的静态数据)视作是一种特殊的流处理。
Flink支持的拓展库涉及机器学习(FlinkML)、复杂事件处理(CEP)、图计算(Gelly) 和分别针对流处理与批处理的 Table API。
架构体系
重要角色
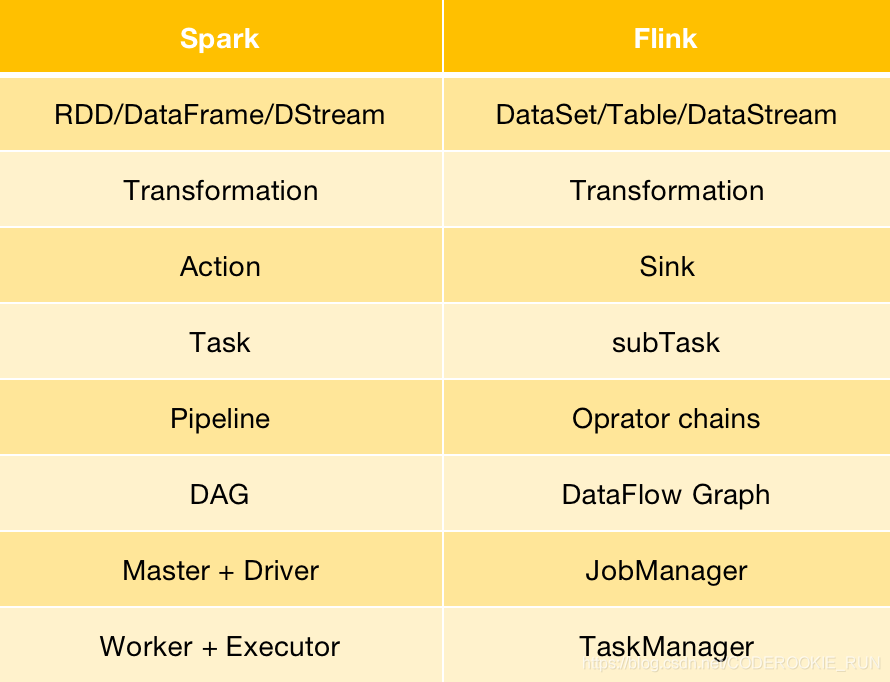
- JobManager
可以认为是Spark中的Master,用于调度task,协调检查点,协调失败时的恢复等。至少要存在一个Master处理器,高可用模式下会存在多个Master,一个是leader,剩下的是standby。 - TaskManager
可以认为是Spark中的Worker,用于执行一个dataflow中的task或者特殊的subtask、数据缓冲和data stream的交换。至少要存在一个Worker处理器。
Flink与Spark架构概念转换