slab分配器
引子
前文介绍了使用为了解决外部碎片,使用Buddy System进行连续内存页面的分配,但对于使用内存的程序而言,Buddy System分配的内存粒度过大,假如我们需要动态申请一个内核结构体(占 20 字节),若仍然分配一页内存,这将严重浪费内存。那么该如何分配呢?slab 分配器专为小内存分配而生,由Sun公司的一个雇员Jeff Bonwick在Solaris 2.4中设计并实现。slab分配器分配内存以字节为单位,基于Buddy System的伙伴分配器的大内存进一步细分成小内存分配。换句话说,slab 分配器仍然从 Buddy 分配器中申请内存,之后自己对申请来的内存细分管理。
除了提供小内存外,slab 分配器的第二个任务是维护常用对象的缓存。对于内核中使用的许多结构,初始化对象所需的时间可等于或超过为其分配空间的成本。当创建一个新的slab 时,许多对象将被打包到其中并使用构造函数(如果有)进行初始化。释放对象后,它会保持其初始化状态,这样可以快速分配对象。
SLAB详细思路还可以参考论文:The Slab Allocator: An Object-Caching Kernel Memory Allotor
slub
SLUB是SLAB的改进版本,从版本 2.6.24 开始,SLUB 分配器取代 SLAB,成为 Linux 内核的默认分配器。SLUB 通过减少 SLAB 分配器所需的大量开销,来解决 slab 分配的性能问题,一个改变是,在 SLAB 分配下每个 slab 存储的元数据,移到 Linux 内核用于每个页面的结构 page。此外,对于 SLAB 分配器,每个 CPU 都有队列以维护每个 cache 内的对象,SLUB 会删除这些队列。 对于具有大量处理器的系统,分配给这些队列的内存量是很重要的。因此,随着系统处理器数量的增加,SLUB 性能也更好。
slob
SLOB是用于嵌入式等内存容量不大的场景下的对象分配算法,SLOB 使用简单的链表结构来管理空闲内存块。只维护一个空闲块的链表,所有分配和释放操作都在这个链表上进行。其简单,开销低,但是也有一些缺点如:性能较低,由于采用线性搜索,分配和释放操作的性能较低,尤其在内存块较多时。缺乏复杂功能,如缓存和对象复用,不能满足大型系统的需求。简而言之,它就是用于简单的嵌入式系统这类场景下的。
slab介绍
slab分配器的管理数据主要划分为两大结构,管理数据结构kmem_cache(称之为缓存)和保存obj对象的各个slab。关于slab这些数据结构组织可以见下图所示:

定义介绍
slab与per-CPU缓存
为了提升效率,SLAB分配器为每一个CPU都提供了每CPU数据结构struct array_cache,该结构指向被释放的对象。当CPU需要使用申请某一个对象的内存空间时,会先检查array_cache中是否有空闲的对象,如果有的话就直接使用。如果没有空闲对象,就像SLAB分配器进行申请。
struct kmem_list3
kmem_list3是per node类型数据,一个node对应一个kmem_list3结构,我们的系统是UMA,所以只有一个kmem_list3结构。kmem_list3中有三个链表slabs_partial、slabs_full、slabs_free,每个链表中挂着都是slab结构。其中,已经有部分obj被分配出去的slab均挂在slabs_partial下;全部obj都被分配出去的slab挂在slabs_full下;全部obj都未分配出去的slab挂在slabs_free下。
struct array_cache
array_cache是per cpu类型数据,每个core对应一个array_cache结构。当array_cache中的obj为空时,系统会以batchcount值为准,一次性从kmem_list3中搬运batchcount个obj到arry_cache中,存放在entry里。
slab
slab主要包含两大部分,管理性数据和obj对象,其中管理性数据包括struct slab和kmem_bufctl_t。slab有两种形式的结构,管理数据外挂式或内嵌式。如果obj比较小,那么struct slab和kmem_bufctl_t可以和obj分配在同一个物理page中,可称为内嵌式;如果obj比较大,那么管理性数据需要单独分配一块内存来存放,称之为外挂式。我们在上图中所画的slab结构为内嵌式。
kmem_bufctl_t
kmem_bufctl_t的类型是unsigned int,本质上是一个空闲obj链表,用于描述下一个可用obj序号。初始化时,当前slab中的obj均可用,所以图中kmem_bufctl_t中的值依次就是下一个可用的obj序。
kmem_bufctl_t中使用方法可参考下图场景。
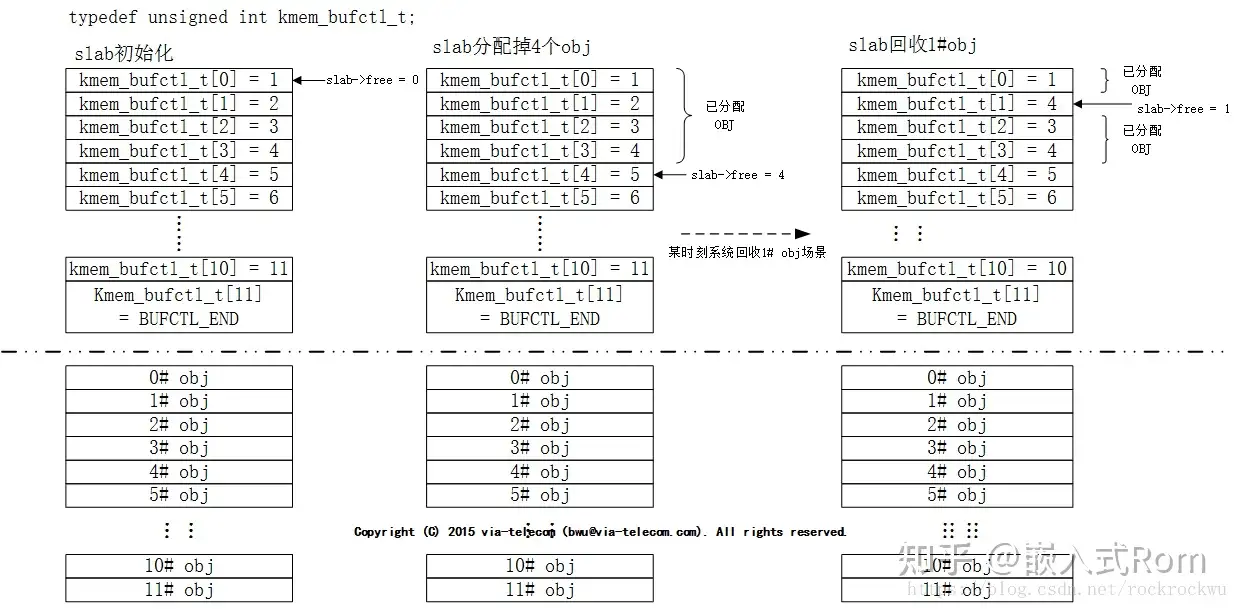
系统初始化时slab->free执行0#slab,某时刻系统已将0#—3# obj分配出去,此时slab->free指向4# slab,而4#slab对应的kmem_bufctl_t中存放的值是5。表明slab中current可用obj是4#,next可用obj是5#。系统运行一段时间后,1# obj需回收。此时,1#obj对应的kmem_bufctl_t中填入slab->free值4,并将slab->free修正为1。这表明slab中current可用obj是1#,next可用的obj为4#。
slab的full、partial、free
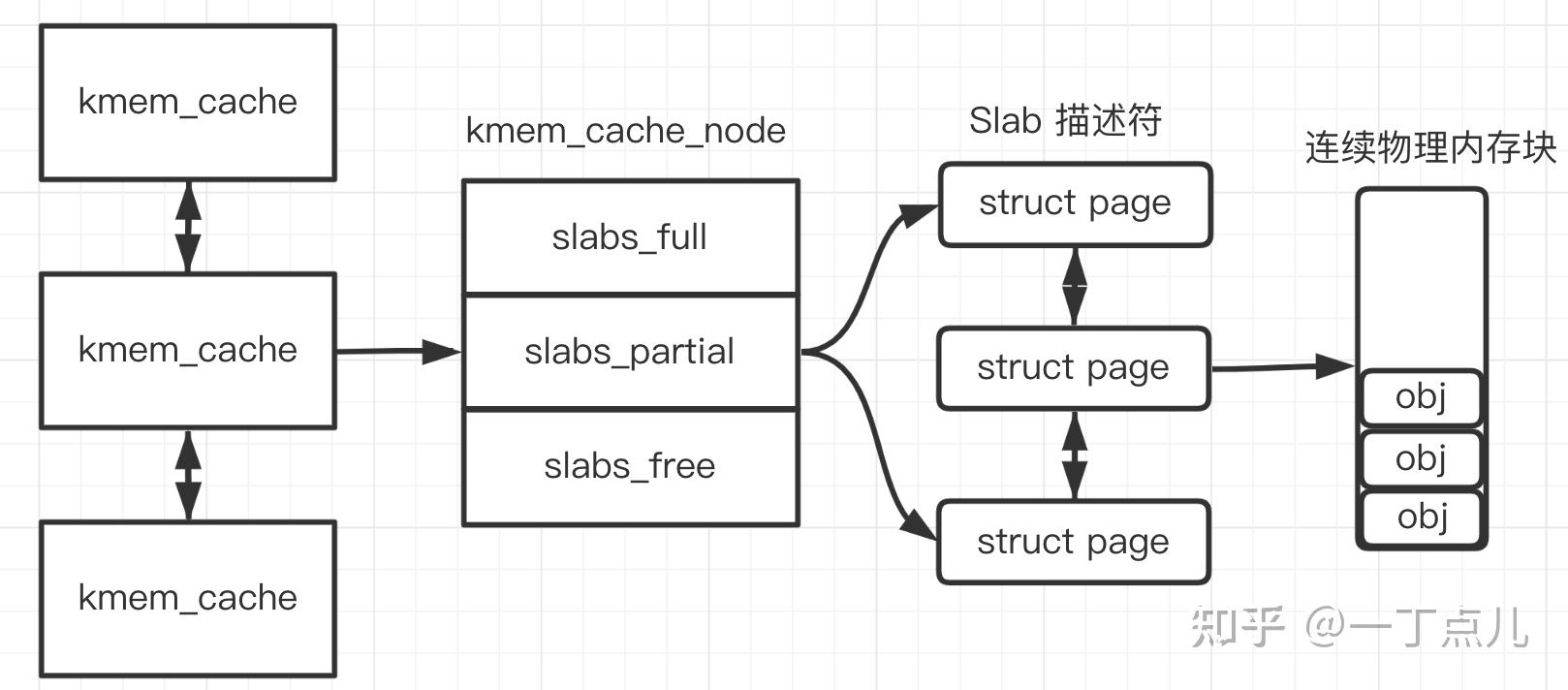
kmem_cache_node 记录了3种slab:(可见上方代码中struct kmem_list3部分)
slabs_full :已经完全分配的 slab
slabs_partial: 部分分配的slab
slabs_free:空slab,或者没有对象被分配
以上3个链表保存的是slab 描述符,Linux kernel 使用 struct page 来描述一个slab。单个slab可以在slab链表之间移动,例如如果一个半满slab被分配了对象后变满了,就要从 slabs_partial 中被删除,同时插入到 slabs_full 中去。
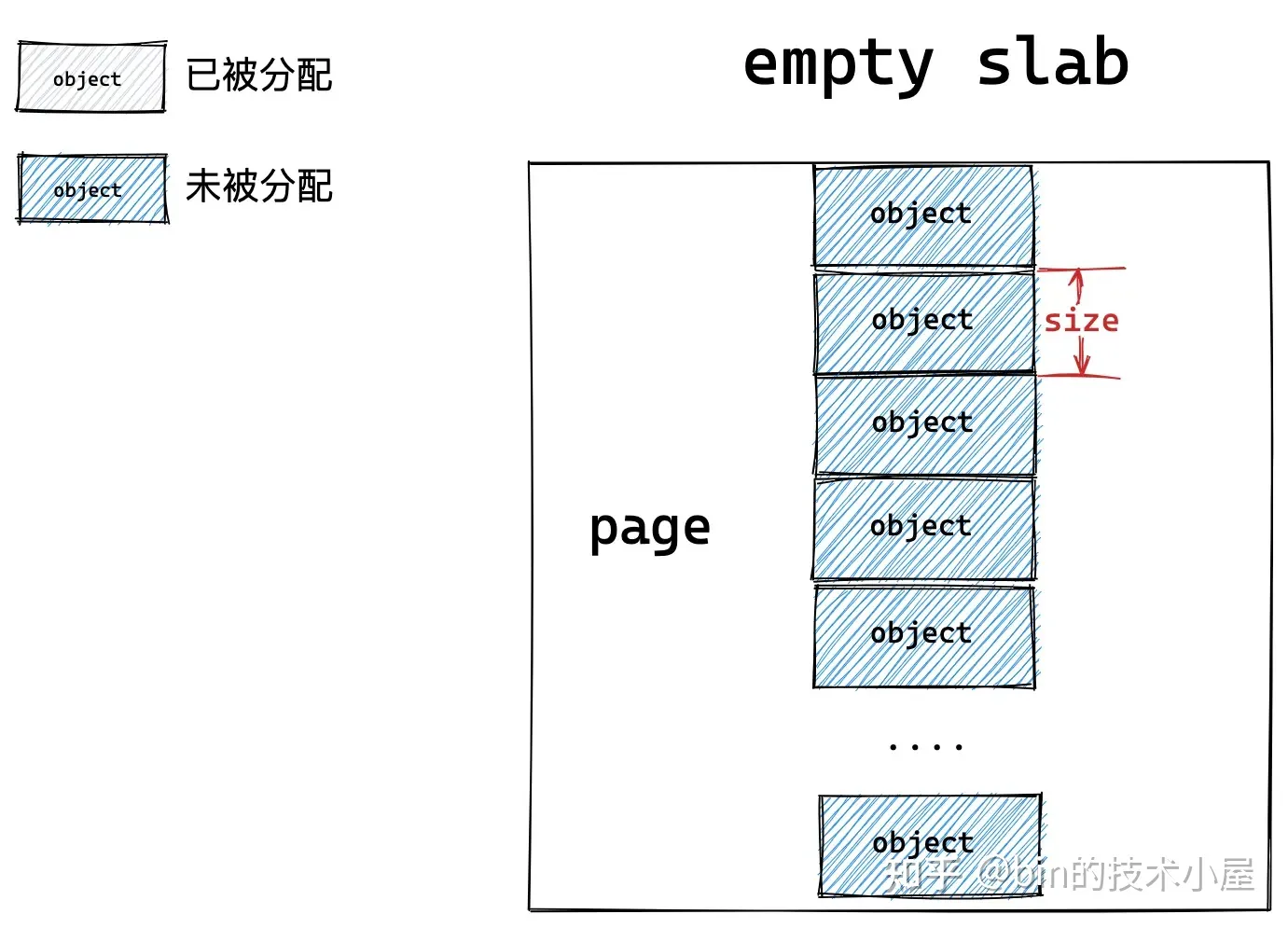
如果一个 slab 中的对象全部分配出去了,slab cache 就会将其视为一个 full slab,表示这个 slab 此刻已经满了,无法在分配对象了。slab cache 就会到伙伴系统中重新申请一个 slab 出来,供后续的内存分配使用。

当内核将对象释放回其所属的 slab 之后,如果 slab 中的对象全部归位,slab cache 就会将其视为一个 empty slab,表示 slab 此刻变为了一个完全空闲的 slab。如果超过了 slab cache 中规定的 empty slab 的阈值,slab cache 就会将这些空闲的 empty slab 重新释放回伙伴系统中。
如果一个 slab 中的对象部分被分配出去使用,部分却未被分配仍然在 slab 中缓存,那么内核就会将该 slab 视为一个 partial slab。
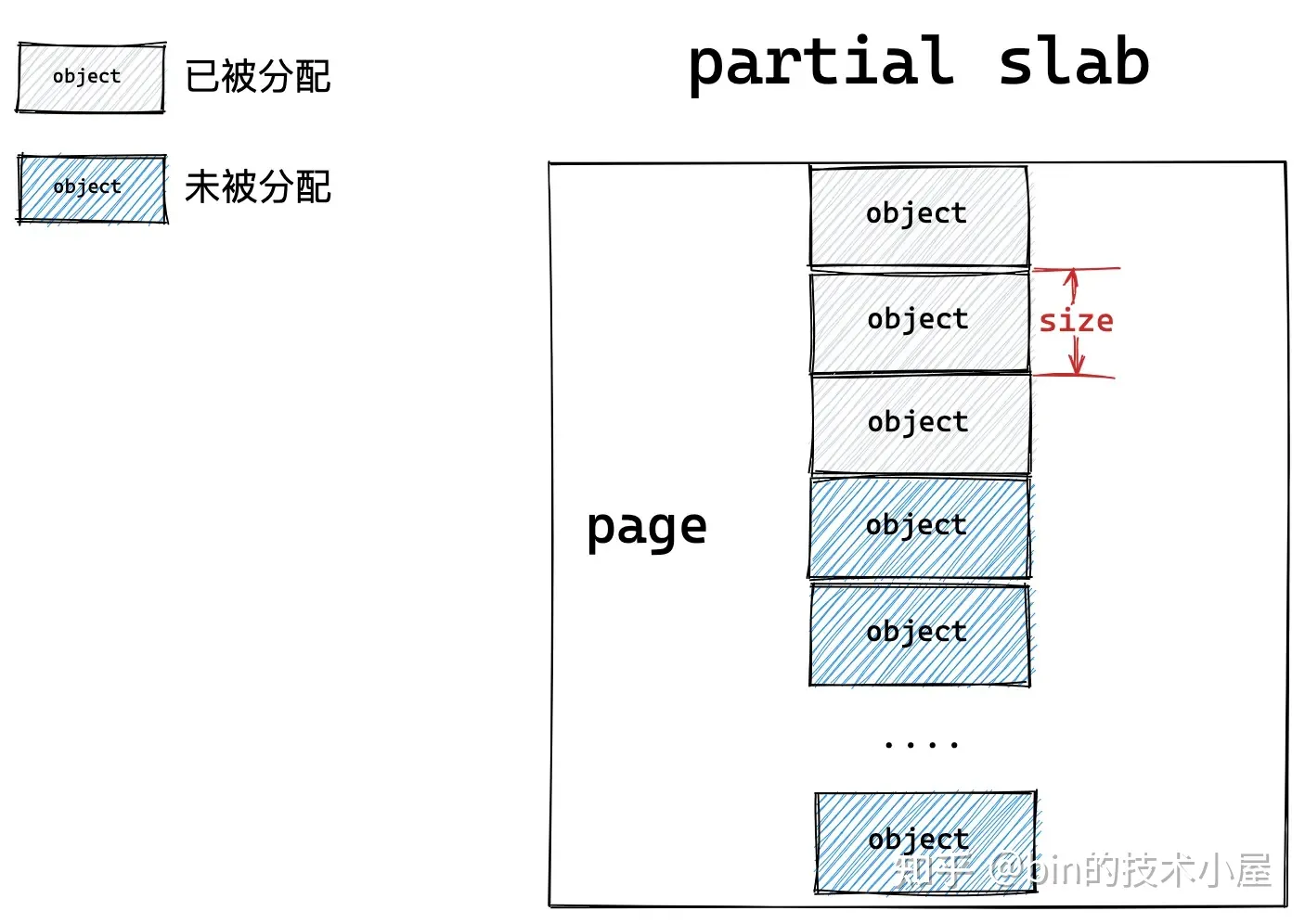
这些不同状态的 slab,会在 slab cache 中被不同的链表所管理,同时 slab cache 会控制管理链表中 slab 的个数以及链表中所缓存的空闲对象个数,防止它们无限制的增长。
slab cache 中除了需要管理众多的 slab 之外,还包括了很多 slab 的基础信息。比如:
slab 对象内存布局相关信息。
slab 中的对象需要按照什么方式进行内存对齐。
一个 slab 具体到底需要多少个物理内存页 page,一个 slab 中具体能够容纳多少个 object (内存块)。
slab分配流程以及管理逻辑
分配流程可以见下图:
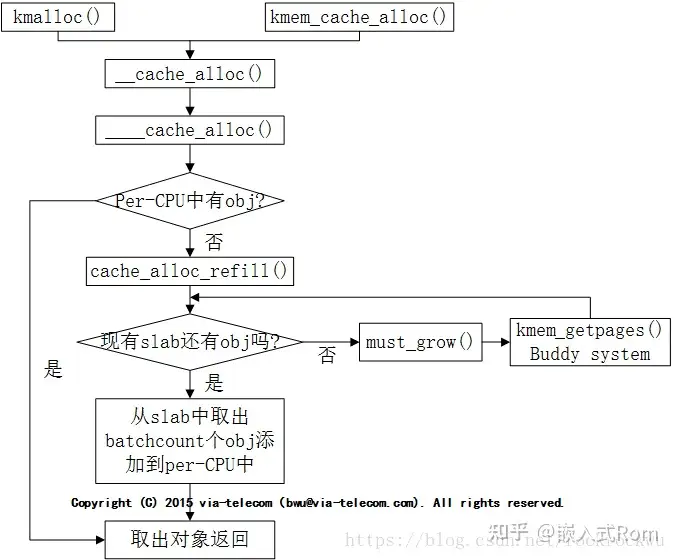
obj分配优先考虑从array_cache的entry中取,取的规则遵循LIFO原则,先从enry的末尾取出obj,因为这个obj很有可能还在硬件cache中,是热的。如果entry为空,则说明是第一次从array_cache中分配obj或者是array_cache中的所有obj都已分配,所以需要先从kmem_cache的kmem_list3中取出batchcount个obj,把这些obj全部填充到enty中,然后再分配。obj释放也是优先考虑释放到array_cache中,而不是直接释放到kmem_list3中。只有array_cache中的obj超过了limit上限,系统才会将enty中的头batchcount个obj搬到kmem_cache所在的kmem_list3中,然后将entry中剩余obj向前移动,然后再将准备释放的obj放到entry的末尾。
slabinfo中的各种缓存信息解析
专用高速缓存和普通高速缓存
Slab将缓存分为两种:一种是专用高速缓存,另外一种是普通高速缓存。
1、专用高速缓存中用来存放内核使用的数据结构,例如:mm_struct, inode, vm_area_struct等。
2、普通高速缓存是指存放一般的数据,比如内核为指针分配的一段内存。普通高速缓存将分配区分为32(20),32*(21),32(22),…,32*(212)大小,共13个区域大小。另外,每个大小均有两个高速缓存,一个为DMA高速缓存,一个是常规高速缓存,它们都在cache_sizes表中进行设定,并有对应的名字cache_names。
以上可以用一张图看出(注:图文不完全对应):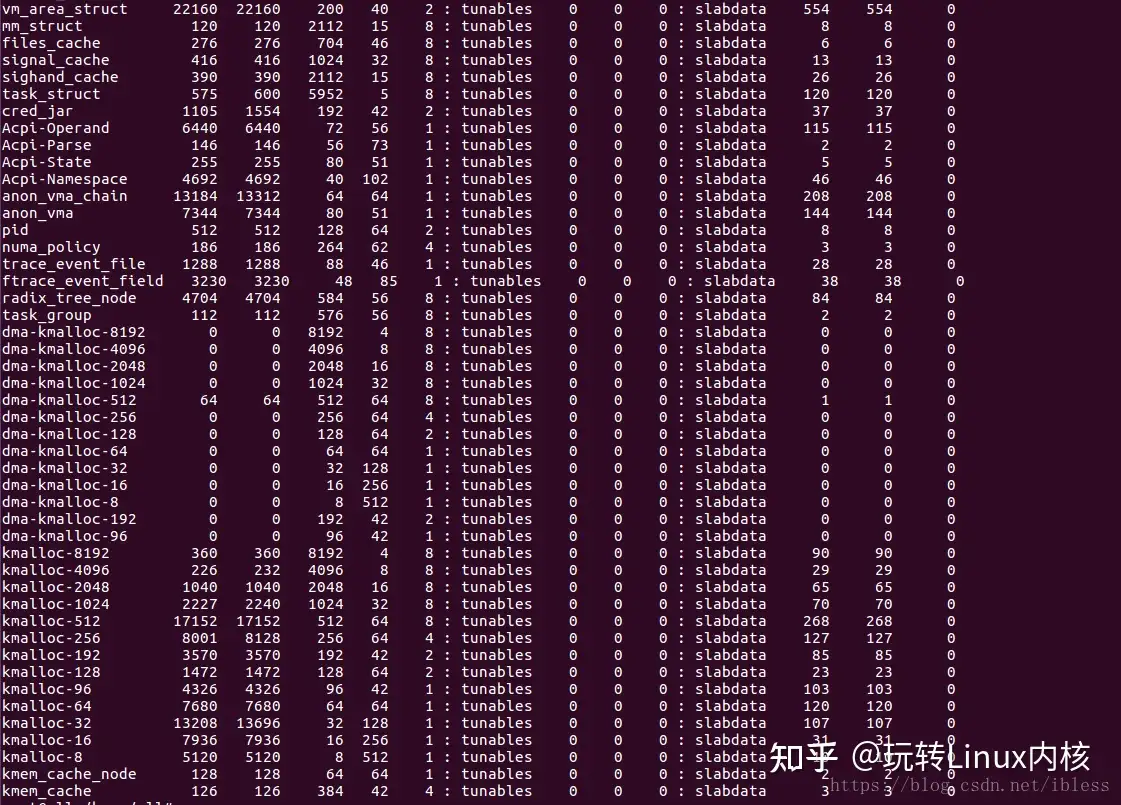
在Linux中使用 sudo cat /proc/slabinfo就可以得到上面的信息。
普通高速缓存只由SLAB分配器用于自己的目的,而专用高速缓存由内核的其余部分使用。专用的高速缓存是由kmem_cache_create()函数创建的,由kmem_cache_destroy()函数撤销,用于存放对象(或具体数据类型),普通高速缓存是系统初始化期间调用keme_cache_init()建立的。普通高速缓存中分配和释放空间使用kmalloc()和kfree()函数,网络上很多内容介绍的slab细节其实也都是内核开发者使用kmalloc()和kfree()才会关联的知识内容!本文这些关于slab的内容,本质都是内核态的内存分配和释放,请注意这和用户态malloc(),free()是两码事,malloc属于用户态的内存申请,由glibc通过系统调用brk,mmap实现。
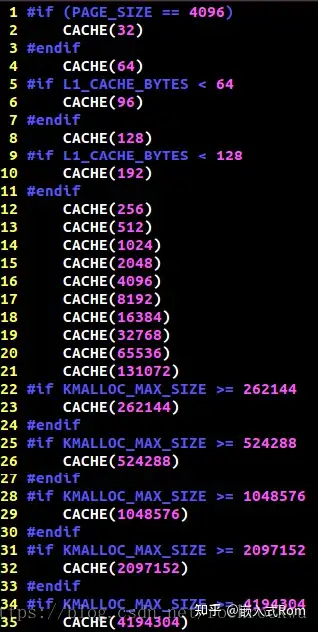
cache size表
内核在初始化的时候根据kmalloc_sizes.h文件中定义的obj大小,初始化了管理这些obj的slab,以及相关kmem_cache。(注意这里的图和上一节图不是同一个系统中截到,为网图,所以size大小两图并不是完全匹配,但是也是为了说明上一张图中的kmalloc-1024这些内容的出处)
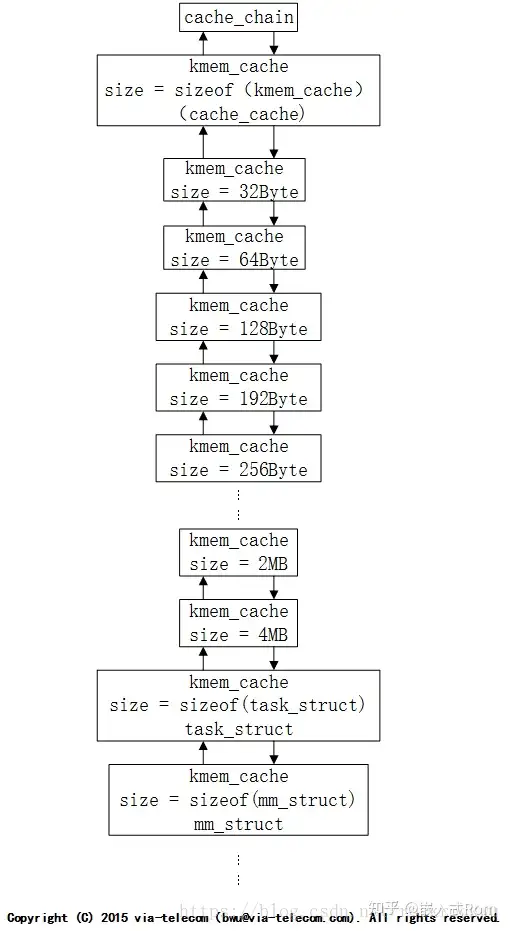
在初始化之后,系统中kmem_cache的链表大致如下。cache_chain上挂着系统中所有的kmem_cache。前面我们提到初始化的时候会根据kmalloc_sizes.h中的定义初始化好固定大小obj的slab以及对应的kmem_cache,这些kmem_cache称之为通用缓存,提供给kmalloc来使用的。kmalloc根据传入size大小来选择合适的kmem_cache,然后从他的array_cache中取出obj。所以我们可以发现kmalloc并没有malloc那么强大,kmalloc分配的时候只是去找和自己size最接近的obj,所以kmalloc分配有可能会造成内存浪费,甚至在某些情况下浪费的还不低!
slab 着色
简单概括,slab 着色就是对 slab 使用不同的颜色(不同的偏移量),尽量使得不同的对象的映射到不同的硬件高速缓存行上。着色相关的内容最终被摒弃了(slub 分配器)。不过这里还是大概介绍一下什么叫着色:
假设cpu的缓存一行为32字节,cpu包含 512 个缓存行(缓存大小16K )。
假设对象 A,B均为32字节,且 A 的地址从 0 开始, B 的地址从 16K 开始,则根据组相联或直接相联映射方式(全相联方式很少使用), A,B 对象很可能映射到缓存的第0行,此时,如果CPU 交替的访问 A,B 各 50 次,每一次访问 缓存的第 0 行都失效,从而需要从内存传送数据。而 slab 着色就是为解决该问题产生的,不同的颜色代表了不同的起始对象偏移量,对于 B 对象,如果将其位置偏移向右偏移 32字节 ,则其可能会被映射到 cache 的第 1 行上,这样交替的访问 A,B 各 50 次,只需要 2 次内存访问即可。
这里的偏移量就代表了 slab 着色中的一种颜色,不同的颜色代表了不同的偏移量,尽量使得不同的对象的对应到不同的硬件高速缓存行上,以最大限度的提高效率。所谓着色,简单来说就是给各个slab增加不同的偏移量,设置偏移量的过程就是着色的过程。实际的情况比上面的例子要复杂得多, slab 的着色还要考虑内存对齐等因素,以及 slab内未用字节的大小,只有当未用字节数足够大时,着色才起作用。
一些源代码
这里贴出了kmalloc()、kmem_cache_alloc()、kfree()、kmem_cache_free()的代码。
这一节贴入的代码皆为linux2.6.11源码(说实话有点老)(可见于 https://elixir.bootlin.com/linux/v2.6.11/source)
分配 slab 对象kmem_cache_alloc()
位于mm/slab.c:
static inline void ** ac_entry(struct array_cache *ac)
{
return (void**)(ac+1);
}
static inline struct array_cache *ac_data(kmem_cache_t *cachep)
{
return cachep->array[smp_processor_id()];
}
/**
* kmem_cache_alloc - Allocate an object
* @cachep: The cache to allocate from.
* @flags: See kmalloc().
*
* Allocate an object from this cache. The flags are only relevant
* if the cache has no available objects.
*/
void * kmem_cache_alloc (kmem_cache_t *cachep, int flags)
{
return __cache_alloc(cachep, flags);
}
static inline void * __cache_alloc (kmem_cache_t *cachep, int flags)
{
unsigned long save_flags;
void* objp;
struct array_cache *ac;
cache_alloc_debugcheck_before(cachep, flags);
local_irq_save(save_flags);
ac = ac_data(cachep);
if (likely(ac->avail)) {
STATS_INC_ALLOCHIT(cachep);
ac->touched = 1;
objp = ac_entry(ac)[--ac->avail];
} else {
STATS_INC_ALLOCMISS(cachep);
objp = cache_alloc_refill(cachep, flags);
}
local_irq_restore(save_flags);
objp = cache_alloc_debugcheck_after(cachep, flags, objp, __builtin_return_address(0));
return objp;
}
首先试图从本地高速缓存获得一个空闲对象,如果没有,则调用 cache_alloc_refill() 函数重新填充本地高速缓存并获得一个空闲对象。cache_alloc_refill() 函数比较复杂,这里不展开。
释放 slab 对象kmem_cache_free()
位于mm/slab.c:
/**
* kmem_cache_free - Deallocate an object
* @cachep: The cache the allocation was from.
* @objp: The previously allocated object.
*
* Free an object which was previously allocated from this
* cache.
*/
void kmem_cache_free (kmem_cache_t *cachep, void *objp)
{
unsigned long flags;
local_irq_save(flags);
__cache_free(cachep, objp);
local_irq_restore(flags);
}
/*
* __cache_free
* Release an obj back to its cache. If the obj has a constructed
* state, it must be in this state _before_ it is released.
*
* Called with disabled ints.
*/
static inline void __cache_free (kmem_cache_t *cachep, void* objp)
{
struct array_cache *ac = ac_data(cachep);
check_irq_off();
objp = cache_free_debugcheck(cachep, objp, __builtin_return_address(0));
if (likely(ac->avail < ac->limit)) {
STATS_INC_FREEHIT(cachep);
ac_entry(ac)[ac->avail++] = objp;
return;
} else {
STATS_INC_FREEMISS(cachep);
cache_flusharray(cachep, ac);
ac_entry(ac)[ac->avail++] = objp;
}
}
首先检查本地高速缓存是否有空间给指向一个空闲对象的额外指针,如果有,该指针被加到本地高速缓存然后返回。否则,调用 cache_flusharray() 函数来清空本地高速缓存,再将指针加到本地高速缓存。 同样,cache_alloc_refill() 函数比较复杂,这里不展开。
分配通用对象kmalloc()
位于include/linux/slab.h:
static inline void *kmalloc(size_t size, int flags)
{
if (__builtin_constant_p(size)) {
int i = 0;
#define CACHE(x) \
if (size <= x) \
goto found; \
else \
i++;
#include "kmalloc_sizes.h"
#undef CACHE
{
extern void __you_cannot_kmalloc_that_much(void);
__you_cannot_kmalloc_that_much();
}
found:
return kmem_cache_alloc((flags & GFP_DMA) ?
malloc_sizes[i].cs_dmacachep :
malloc_sizes[i].cs_cachep, flags);
}
return __kmalloc(size, flags);
}
mm/slab.c:
/**
* kmalloc - allocate memory
* @size: how many bytes of memory are required.
* @flags: the type of memory to allocate.
*
* kmalloc is the normal method of allocating memory
* in the kernel.
*
* The @flags argument may be one of:
*
* %GFP_USER - Allocate memory on behalf of user. May sleep.
*
* %GFP_KERNEL - Allocate normal kernel ram. May sleep.
*
* %GFP_ATOMIC - Allocation will not sleep. Use inside interrupt handlers.
*
* Additionally, the %GFP_DMA flag may be set to indicate the memory
* must be suitable for DMA. This can mean different things on different
* platforms. For example, on i386, it means that the memory must come
* from the first 16MB.
*/
void * __kmalloc (size_t size, int flags)
{
struct cache_sizes *csizep = malloc_sizes;
for (; csizep->cs_size; csizep++) {
if (size > csizep->cs_size)
continue;
#if DEBUG
/* This happens if someone tries to call
* kmem_cache_create(), or kmalloc(), before
* the generic caches are initialized.
*/
BUG_ON(csizep->cs_cachep == NULL);
#endif
return __cache_alloc(flags & GFP_DMA ?
csizep->cs_dmacachep : csizep->cs_cachep, flags);
}
return NULL;
}
EXPORT_SYMBOL(__kmalloc);
释放通用对象kfree()
mm/slab.c:
/**
* kfree - free previously allocated memory
* @objp: pointer returned by kmalloc.
*
* Don't free memory not originally allocated by kmalloc()
* or you will run into trouble.
*/
void kfree (const void *objp)
{
kmem_cache_t *c;
unsigned long flags;
if (!objp)
return;
local_irq_save(flags);
kfree_debugcheck(objp);
c = GET_PAGE_CACHE(virt_to_page(objp));
__cache_free(c, (void*)objp);
local_irq_restore(flags);
}
总结
其实本文理论上应该是深入理解linux内核的阅读笔记,但这本书实在是过老了,而且本书其实也只是罗列函数和变量并没有讲明白slab,许多本文内容实际上也是网上各路内容的总结。而该书里面linux2.6.11内核的许多代码很明显已经存在缺陷并被后续高得多版本的内核进行了优化,就slab而言,还有许多机制如内存池、多cpu等本书没有讲明白或者属于后面slub的优化内容,以及一些内存的分配机制,本书也未说的很清楚。
因此,本文实际上是阅读该书之后,重新对slab的一些内容的整理,因此本文前面各节并不和2.6.11的slab源码强对应,但其是属于linux各版本slab的算法内容这是肯定无疑的,因此本文一些图文不匹配或者和你打开2.6.11的源码发现并不完全对应,请不要在意。
本人强烈推荐可以继续阅读(https://www.cnblogs.com/binlovetech/p/17288990.html) 的内容来更清楚的了解slab。
参考:
https://www.cnblogs.com/binlovetech/p/17288990.html
https://www.dingmos.com/index.php/archives/23/#
https://freeflyingsheep.github.io/posts/kernel/memory/slab/
https://www.zhihu.com/question/31648017?sort=created

 浙公网安备 33010602011771号
浙公网安备 33010602011771号