分布式并行计算MapReduce
HDFS特点
1.数据冗余,软件容错很高。
2.流失数据访问,也就是HDFS一次写入,多次读写,并且没办法进行修改,只能删除之后重新创建
3.适合存储大文件。如果是小文件,而且是很多小文件,连一个块都装不满,并且还需要很多块,就会极大浪费空间。
HDFS的适用性和局限性:
1.数据批量读写,吞吐量高。
2.不适合交互式应用,延迟较高。
3.适合一次写入多次读取,顺序读取。
4.不支持多用户并发读写文件。
MapReduce:
MapReduce是并行处理框架,实现任务分解和调度。
其实原理说通俗一点就是分而治之的思想,将一个大任务分解成多个小任务(map),小任务执行完了之后,合并计算结果(reduce)。
2.HDFS上运行MapReduce
1)准备文本文件,放在本地/home/hadoop/wc

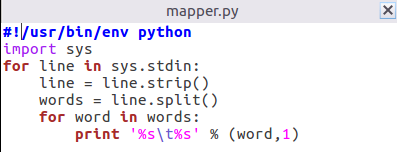
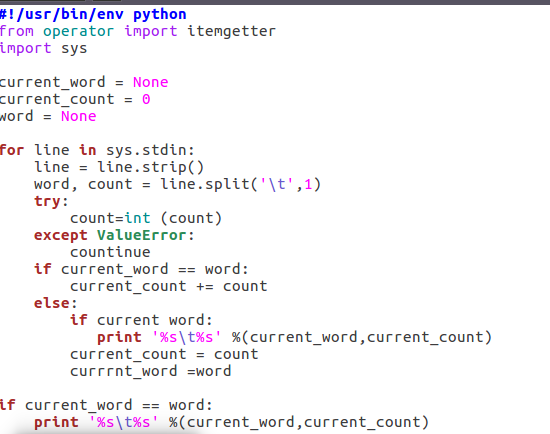
2)编写map函数和reduce函数,在本地运行测试通过
mapper
reduce
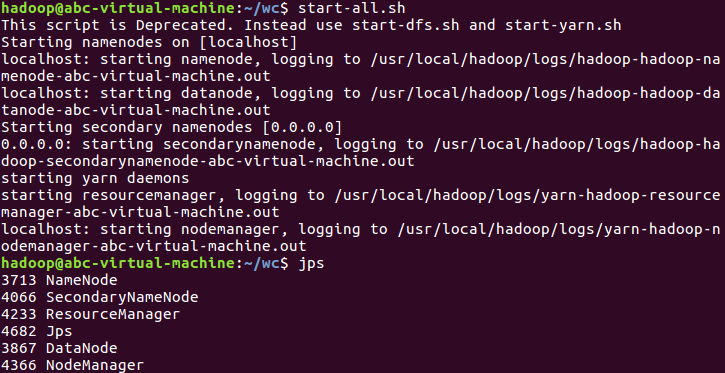
3)启动Hadoop:HDFS, JobTracker, TaskTracker
4)把文本文件上传到hdfs文件系统上 user/hadoop/input

5)streaming的jar文件的路径写入环境变量,让环境变量生效


6)建立一个shell脚本文件:streaming接口运行的脚本,名称为run.sh
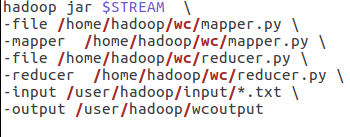
7)source run.sh来执行mapreduce
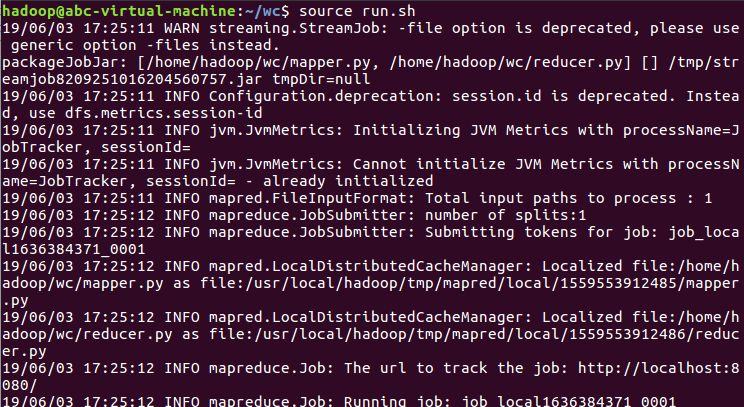
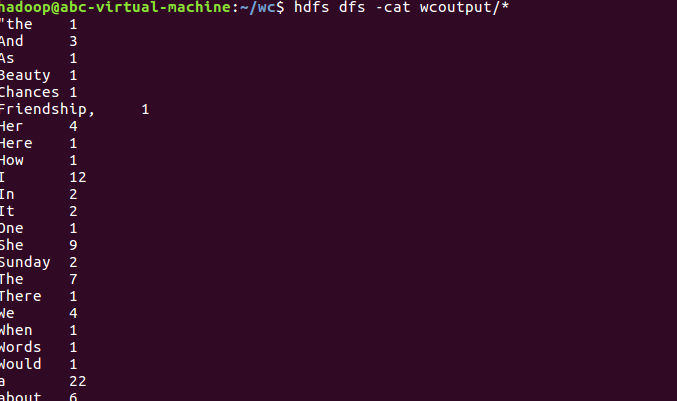
8)查看运行结果