
爬虫综合大作业
分析数据分析岗位的招聘情况,包括地区分布、薪资水平、职位要求等,了解最新数据分析岗位的情况
数据出选爬取
# -*- coding:utf-8 -*-
import urllib
import re,codecs
import time,random
import requests
from lxml import html
from urllib import parse
key='数据分析'
key=parse.quote(parse.quote(key))
headers={'Host':'search.51job.com',
'Upgrade-Insecure-Requests':'1',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
def get_links(page):
url ='http://search.51job.com/list/000000,000000,0000,00,9,99,'+key+',2,'+ str(page)+'.html'
r= requests.get(url,headers,timeout=10)
s=requests.session()
s.keep_alive = False
r.encoding = 'gbk'
reg = re.compile(r'class="t1 ">.*? <a target="_blank" title=".*?" href="(.*?)".*? <span class="t2">', re.S)
links = re.findall(reg, r.text)
return links
#多页处理,下载到文件
def get_content(link):
r1=requests.get(link,headers,timeout=10)
s=requests.session()
s.keep_alive = False
r1.encoding = 'gbk'
t1=html.fromstring(r1.text)
try:
job=t1.xpath('//div[@class="tHeader tHjob"]//h1/text()')[0]
company = t1.xpath('//p[@class="cname"]/a/text()')[0]
print(company)
label=t1.xpath('//p[@class="t2"]/span/text()')
education=t1.xpath('//div[@class="t1"]//span[2]/text()')[0]
salary = re.findall(re.compile(r'<span class="lname">.*?<strong>(.*?)</strong>',re.S),r1.text)[0]
area = t1.xpath('//div[@class="tHeader tHjob"]//span[@class="lname"]/text()')[0]
companytype=t1.xpath('//p[@class="msg ltype"]/text()')
workyear=t1.xpath('//div[@class="t1"]//span[1]/text()')[0]
describe = re.findall(re.compile(r'<div class="bmsg job_msg inbox">(.*?)任职要求',re.S),r1.text)
require = re.findall(re.compile(r'<div class="bmsg job_msg inbox">.*?任职要求(.*?)<div class="mt10">',re.S),r1.text)
try:
file = codecs.open('51job.xls', 'a+', 'utf-8')
item = str(company)+'\t'+str(job)+'\t'+str(education)+'\t'+str(label)+'\t'+str(salary)+'\t'+str(companytype)+'\t'+str(workyear)+'\t'+str(area)+'\t'+str(workyear)+str(describe)+'\t'+str(require)+'\n'
file.write(item)
file.close()
return True
except Exception as e:
print(e)
return None
#output='{},{},{},{},{},{},{},{}\n'.format(company,job,education,label,salary,area,describe,require)
#with open('51job.csv', 'a+', encoding='utf-8') as f:
#f.write(output)
except:
print('None')
for i in range(1,2000):
print('正在爬取第{}页信息'.format(i))
try:
#time.sleep(random.random()+random.randint(1,5))
links=get_links(i)
for link in links:
get_content(link)
#time.sleep(random.random()+random.randint(0,1))
except:
continue
print('有点问题')
利用panda去除无关数据
# -*- coding: UTF-8 -*-
import pandas as pd
import numpy as np
data=pd.read_excel('51joball.xlsx',sheet_name='Sheet1',header=0)
df=pd.DataFrame(data)
df=df[True- df.公司.duplicated()]#去重
df=df[df.职位.str.contains(r'.*?数据.*?|.*?分析.*?')]#提取包含数据或者分析的岗位
df.to_excel('new51job.xlsx')
整理数据
#coding:utf8
import xlrd
import codecs
import re
#加载Excel数据,获得工作表和行数
def load_from_xlsx(file):
data = xlrd.open_workbook(file)
table0 = data.sheet_by_name('Sheet1')
nrows = table0.nrows
return table0, nrows
#利用正则表达式提取月薪,把待遇规范成千/月的形式
def get_salary(salary):
if '-'in salary: #针对1-2万/月或者10-20万/年的情况,包含-
low_salary=re.findall(re.compile('(\d*\.?\d+)'),salary)[0]
high_salary=re.findall(re.compile('(\d?\.?\d+)'),salary)[1]
if u'万' in salary and u'年' in salary:#单位统一成千/月的形式
low_salary = float(low_salary) / 12 * 10
high_salary = float(high_salary) / 12 * 10
elif u'万' in salary and u'月' in salary:
low_salary = float(low_salary) * 10
high_salary = float(high_salary) * 10
else:#针对20万以上/年和100元/天这种情况,不包含-,取最低工资,没有最高工资
low_salary = re.findall(re.compile('(\d*\.?\d+)'), salary)[0]
high_salary=""
if u'万' in salary and u'年' in salary:#单位统一成千/月的形式
low_salary = float(low_salary) / 12 * 10
elif u'万' in salary and u'月' in salary:
low_salary = float(low_salary) * 10
elif u'元'in salary and u'天'in salary:
low_salary=float(low_salary)/1000*21#每月工作日21天
return low_salary,high_salary
def main():
data = load_from_xlsx(r'new51job.xlsx')
table, nrows = data[0], data[1]
print('一共有{}行数据,开始清洗数据'.format(nrows))
for i in range(1,nrows):
id=table.row_values(i)[0]
company=table.row_values(i)[1]
position = table.row_values(i)[2]
education = table.row_values(i)[3]
welfare = table.row_values(i)[4]
salary=table.row_values(i)[5]
area = table.row_values(i)[6][:2]#地区取到城市,把区域去掉
companytype = table.row_values(i)[7]
companysize = table.row_values(i)[8]
field = table.row_values(i)[9]
experience = table.row_values(i)[10]
responsibility = table.row_values(i)[11]
requirement = table.row_values(i)[12]
if salary:#如果待遇这栏不为空,计算最低最高待遇
getsalary=get_salary(salary)
low_salary=getsalary[0]
high_salary=getsalary[1]
else:
low_salary=high_salary=""
print('正在写入第{}条,最低工资是{}k,最高工资是{}k'.format(i,low_salary,high_salary))
output = '{}\t{}\t{}\t{}\t{}\t{}\t{}\t{}\t{}\t{}\t{}\t{}\t{}\t{}\n'.format(id, company, position, education, welfare,low_salary, high_salary, area, companytype,companysize, field, experience, responsibility,requirement)
f=codecs.open('51jobanaly.xls','a+')
f.write(output)
f.close()
if __name__=='__main__':
main()
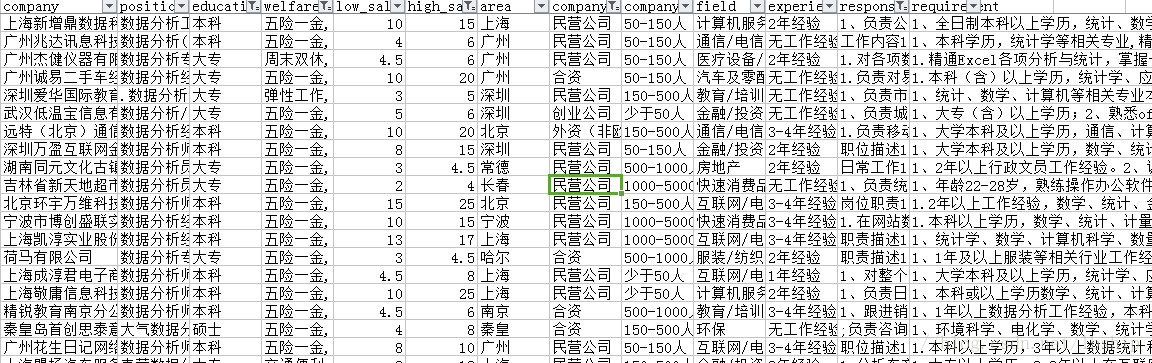
对于重复数据使用panda进行去重,还有去除重复数据,数据清洗得到的数据保存为xsl文件如下
数据可视化与分析
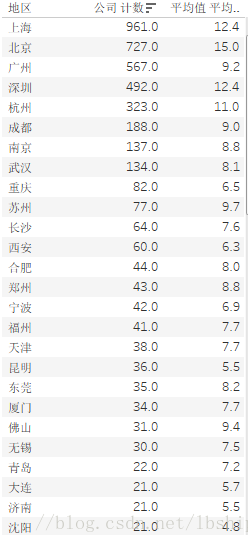
可以看出不论是招聘公司的数据还是平均待遇水平主要都是北上广深杭州占优势。成都紧随其后。
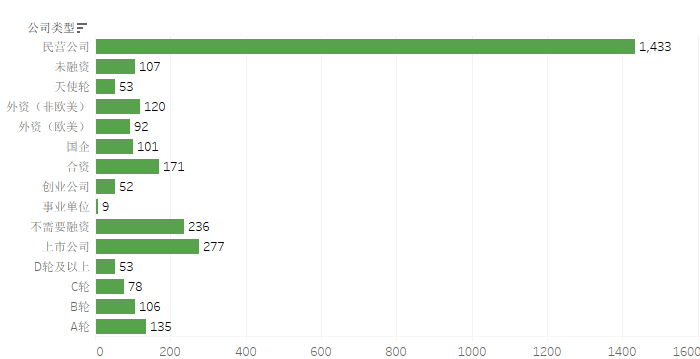
根据表格可以看出招聘的公司主要是民营企业和一些创业公司为主。
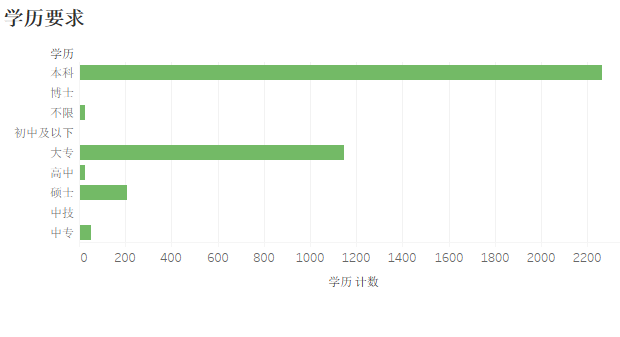
根据下表可以看出大部分公司对于学历要求是以本科为主,当然不乏与其他大公司对于更高学历的需求
生成词云


