

理解爬虫原理
1. 简单说明爬虫原理
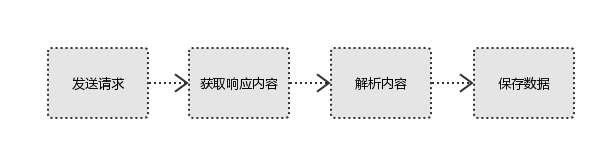
1:向服务器发起请求
通过HTTP库向目标站点发起请求,即发送一个Request,请求可以包含额外的headers等信息,等待服务器的响应。
2:获取响应内容
如果服务器正常响应,会得到一个Response,Response的内容便是所要获取的页面内容,类型可能有HTML、JSON、二进制文件(如图片、视频等类型)。
3:解析内容
得到的内容可能是HTML,可以用正则表达式、网页解析库进行解析。可能是JSON,可以直接转成JOSN对象进行解析,可能是二进制数据,可以保存或者进一步处理
4:保存内容
保存形式多样,可以保存成文本,也可以保存至数据库,或者保存成特定格式的文件。
2. 理解爬虫开发过程
1).简要说明浏览器工作原理;
2).使用 requests 库抓取网站数据;
requests.get(url) 获取校园新闻首页html代码
import requests
import bs4
from bs4 import BeautifulSoup
res = requests.get(url='http://news.gzcc.cn/html/xiaoyuanxinwen')
res.encoding = 'utf-8'
print(res.text)
3).了解网页
写一个简单的html文件,包含多个标签,类,id
<div class="dowebok">
<div class="logo"></div>
<div class="form-item">
<input id="username" type="text" autocomplete="off" placeholder="邮箱">
</div>
<div class="form-item">
<input id="password" type="password" autocomplete="off" placeholder="登录密码">
</div>
<div class="form-item"><button id="submit">登 录</button></div>
<div class="reg-bar">
<a class="reg" href="javascript:">立即注册</a>
<a class="forget" href="javascript:">忘记密码</a>
</div>
</div>
4).使用 Beautiful Soup 解析网页;
通过BeautifulSoup(html_sample,'html.parser')把上述html文件解析成DOM Tree
select(选择器)定位数据
找出含有特定标签的html元素
找出含有特定类名的html元素
找出含有特定id名的html元素
from bs4 import BeautifulSoup
htmlfile = open('test.html', 'r', encoding='utf-8')
htmlhandle = htmlfile.read()
soup = BeautifulSoup(htmlhandle, "html.parser");
# 找出含有特定标签的html元素
print(soup.select("username"));
# 找出含有特定类名的html元素
print(soup.select("password"));
# 找出含有特定id名的html元素
print(soup.select("submit"));
3.提取一篇校园新闻的标题、发布时间、发布单位
url = 'http://news.gzcc.cn/html/2019/xiaoyuanxinwen_0320/11029.html'
import requests
import bs4
from bs4 import BeautifulSoup
url='http://news.gzcc.cn/html/2018/xiaoyuanxinwen_1204/10615.html'
res=requests.get(url)
res.encoding='utf-8'
soup=BeautifulSoup(res.text,'html.parser')
t = soup.select('.show-title')[0].text
for news in soup.select('div'):
if len(news.select('.show-title'))>0:
head=news.select('.show-title')[0].text
message=news.select('.show-info')[0].text
print('标题: '+ head)
print('发布的相关单位及时间: '+message)
break
