
复合数据类型,英文词频统计
1.列表,元组,字典,集合分别如何增删改查及遍历。
(1)列表
增:
list.append()在末尾增加元素
list.extend()继承另一组列表
list.insert()插入元素
删:
del list()删除元素
改:
list[?]='?'修改元素
查:
x = list.index(?)查找元素的索引值
遍历:
for i in list:
print (i) 用for循环进行遍历
(2)元组
增删改查与列表大致相同,只是元组不能直接修改元素,不得删除单个元素。
(3)字典
增:dict['key']='value'
删:del dict['key']
改:if 'key' in dict1: dict1['key']='new_value'
查:if 'key' in dict: print dict1['key']
遍历:for i in dict['key']:
print(i)
(4)集合
增:s.add( x ) 将元素 x 添加到集合 s 中,如果元素已存在,则不进行任何操作。
删:s.remove( x ) 将元素 x 从集合 s 中移除,如果元素不存在,则会发生错误。
改:s[i]="?"
查:x in s 查找元素是否在集合中
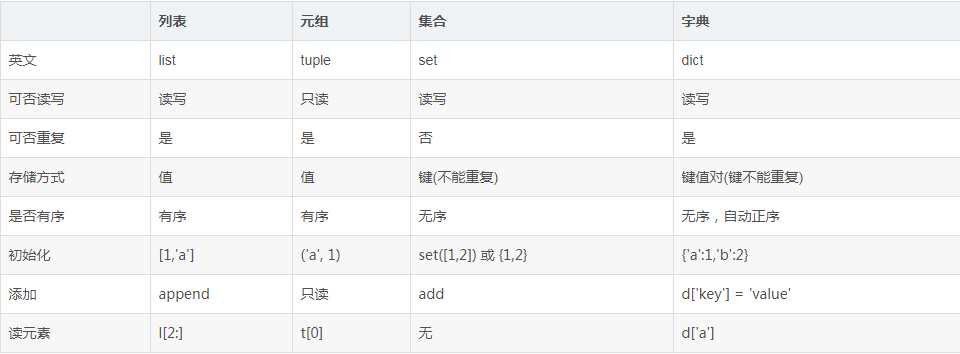
2.总结列表,元组,字典,集合的联系与区别。参考以下几个方面:
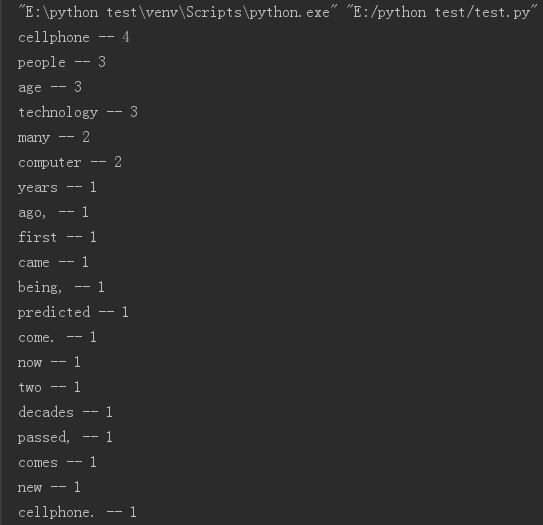
3.词频统计
import pandas as pd
import stopwords
stopwords = stopwords.get_stopwords('english')
f = open("english.txt", "r", encoding="utf-8")
str = f.read()
f.close()
remove = ",,—-。?.()?!‘’"
str = str.lower()
dict = {}
for i in remove:
str = str.replace(i, "")
list = str.split()
for word in list:
if word not in stopwords:
dict[word] = list.count(word)
d = sorted(dict.items(), reverse=True, key=lambda d: d[1])
for l in range(20):
print(d[l][0], "--", d[l][1])
pd.DataFrame(data=d).to_csv('words.csv',encoding='utf-8')
词云


