

第3次作业-MOOC学习笔记:Python网络爬虫与信息提取
1.注册中国大学MOOC
2.选择北京理工大学嵩天老师的《Python网络爬虫与信息提取》MOOC课程
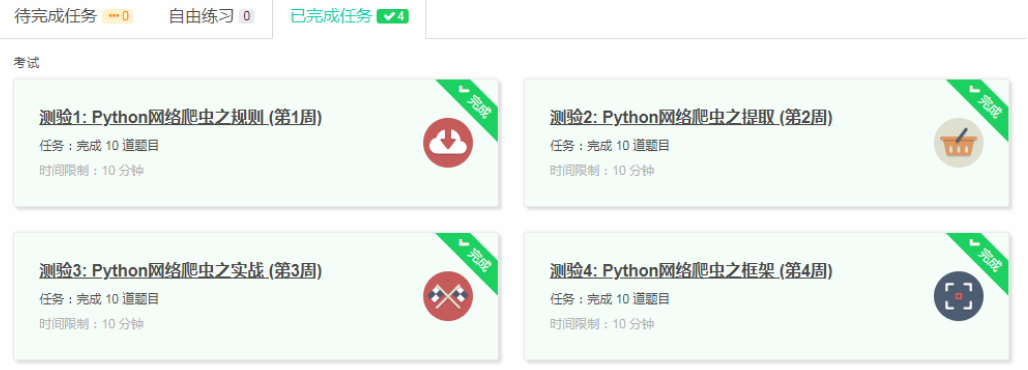
3.学习完成第0周至第4周的课程内容,并完成各周作业
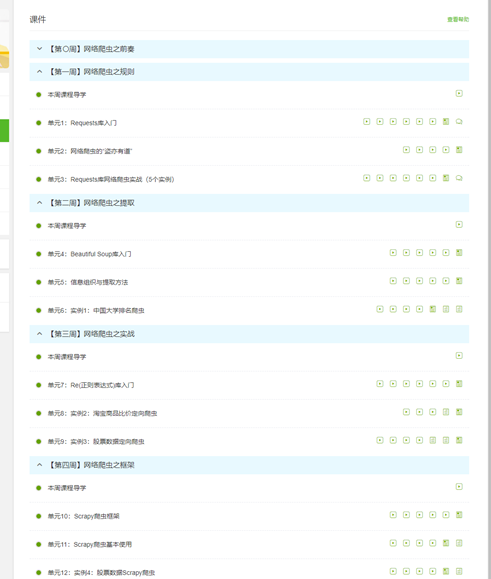
4.提供图片或网站显示的学习进度,证明学习的过程。

5.写一篇不少于1000字的学习笔记,谈一下学习的体会和收获。
心得:
在这两周里我初步学习了一个新的知识点,在慕课网上学习的爬虫,刚开始的时候还不太了解爬虫俩个字的含义以及所用到的知识,
在这两周的学习我已经初步了解了有关爬虫的知识,受益良多,下面是我这两周以来学习的心得及其体会
爬虫的作用:爬取我们所需要的数据并进行数据的清洗整理。
网页的三大特点
- 每一个网页都有一个唯一的url(统一资源定位符),来进行定位
- 网页都是通过HTMl(超文本)文本展示的
- 所有的网页都是通过http<超文本传输协议>(HTTPS)协议来传输的
爬虫的流程
- 分析网站,得到目标url
- 根据url,发起请求,获取页面的HTML的源码
- 从页面源码中提取数据
a. 提取到目标欧数据,做数据的赛选和持久化存储
b. 从页面中提取到新的url地址,继续执行第二部操作 - 爬虫结束:所有的目标url都提取完毕,并且得到了数据,再也没有其他请求任务了,这是意味着爬虫结束
通过爬虫抓取网页的流程
- 选取一部分的url作为种子url,将这些url放入到带爬取得任务队列里
- 从带爬取得任务队列中取出url,发起请求,将获取到的页面源码存储到本地,并将已经爬取过的url,放入已爬取队列中
- 从已爬取url的响应结果中,分析提取其他的url地址,继续添加到带爬取队列中,之后就是不断的循环,查到所有的url都提取完毕
200 :请求成功。301 : 永久重定向。302 : 临时重定向。401 : 未授权
403 : 服务器拒绝访问。404 : 页面丢失。405 : 请求方式不对
408 : 请求超时。500 : 服务器错误。503 : 服务器不可用
发起请求
会携带请求头:
’USer-Agent‘:模拟浏览器请求
‘Cookies’:存储在浏览器里,使用cookie表明身份
‘Refere’:说明当前请求是从哪个页面发起
在视频中老师 教我们的是利用python进行爬虫,首先我们要装一个第三方库Requests,这个可以说是python进行爬虫的好的第三方库
其中里面有着这样一些重要的方法如下:
(1)requests.put()是指向HTML网页提交PUT请求的方法,对应于HTTP的PUT ;
(2)requests.get()是指获取HTML网页的主要方法,对应于HTTP的GET;
(3)requests.delete()是指向HTML页面提交删除请求,对应于HTTP的DELETE。
(4)requests.post()是指向HTML网页提交POST请求的方法,对应于HTTP的POST ;
(5)requests.head()是指获取HTML网页头信息的方法,对应于HTTP的HEAD ;
(6)requests.patch()是指像HTTP网页提交局部修改请求,对应于HTTP的PATCH;
(7)requests.request()是指构造一个请求,支撑以下各种方法的基础方法 ;
此次的学习结合鄂老师的课程让我增加了关于python的知识,对网络爬虫产生了浓厚的兴趣,网络爬虫又被称为网页蜘蛛,是一种按照一定的规则,自动的抓取信息的程序或者脚本,可以在网站中爬取很多重要的信息,但是盗亦有道,还是需要在遵纪守法的前提下来学习提升自己。
