
LRU、FIFO缓存实现以及LinkedHashMap源码
本篇将描述如何使用LinkedHashMap实现LRU以及FIFO缓存,并将从LinkedHashMap源码层面描述是如何实现这两种缓存的。
1.缓存描述
首先介绍一下FIFO、LRU两种缓存:
FIFO(First In First out):先见先出,淘汰最先近来的页面,新进来的页面最迟被淘汰,完全符合队列。
LRU(Least recently used):最近最少使用,淘汰最近不使用的页面。
2.代码实现
以下是通过LinkedHashMap实现两种缓存。
public class Cache<K,V>{ private LinkedHashMap<K, V> map = null;//用LinkedHashMap实现 private int cap;//上限 public Cache(int cap, boolean lru) {//构造函数(lru:false即为lru) this.cap = cap; map = new LinkedHashMap<K,V>(cap, 0.75f, lru){//第三个参数即为LinkedHashMap中的accessOrder true:将按照访问顺序(如果已经存在将其插入末尾); false:按照插入数序(再次插入不影响顺序) @Override protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {//重写删除最早的entry return size() > cap;//如果条件当前size大于cap,就删除最早的(返回true) } }; } public V put(K key, V value){ return map.put(key, value); } @Override public String toString() { return map.toString(); } }
重写toString方法是为了测试时可以更简单的打印出两种缓存的效果。
下面是测试方法:
public static void main(String[] args) { //lru测试 Cache<Integer, Integer> cache = new Cache<Integer, Integer>(3, true); cache.put(1, 1); System.out.println(cache); cache.put(2, 2); System.out.println(cache); cache.put(3, 3); System.out.println(cache); cache.put(1, 1); System.out.println(cache); cache.put(4, 4); System.out.println(cache); //fifo测试 cache = new Cache<Integer, Integer>(3, false); cache.put(1, 1); System.out.println(cache); cache.put(2, 2); System.out.println(cache); cache.put(3, 3); System.out.println(cache); cache.put(1, 1); System.out.println(cache); cache.put(4, 4); System.out.println(cache); }
以下是测试结果:
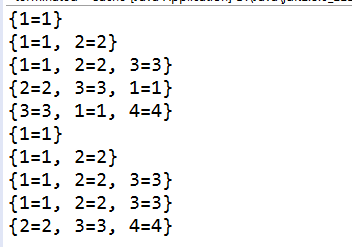
可以看到lru模式下,当缓存被访问到时,会将其放到末尾,因此按照最近最少被使用淘汰缓存;而fifo模式下缓存顺序按照进入顺序,最先进来的最先被淘汰。
那么为什么如此简单的使用LinkedHashMap就可以完成这两种常用缓存淘汰策略的实现呢?下面我们从LinkedHashMap源码来了解其内部是如何工作的。
3.源码分析
首先,我们来说说LinkedHashMap是如何做到能记录插入顺序的。这就要看它的Entry节点了:
1 static class Entry<K,V> extends HashMap.Node<K,V> { 2 Entry<K,V> before, after; 3 Entry(int hash, K key, V value, Node<K,V> next) { 4 super(hash, key, value, next); 5 } 6 } 7 8 transient LinkedHashMap.Entry<K,V> head; 9 10 transient LinkedHashMap.Entry<K,V> tail;
LinkedHashMap中的Entry继承了HashMap中的Node,并增加了一个before和after指向插入的前(后)一个Entry,并在LinkedHashMap中用head和tail记录首位节点,这个结构看起来就像是把HashMap和LinkedList结合起来,做到记录插入顺序。
那么LinkedHashMap中的put方法呢?当你打开LinkedHashMap去查找put方法时,你会发现找不到,因为其继承了HashMap,因此直接使用HashMap中的put方法,那么同一个put方法是如何做到在插入之后将before,after指针更新的呢?来看看HashMap的put是如何设计的吧:
1 public V put(K key, V value) { 2 return putVal(hash(key), key, value, false, true); 3 } 4 5 final V putVal(int hash, K key, V value, boolean onlyIfAbsent, 6 boolean evict) { 7 Node<K,V>[] tab; Node<K,V> p; int n, i; 8 if ((tab = table) == null || (n = tab.length) == 0) 9 n = (tab = resize()).length; 10 if ((p = tab[i = (n - 1) & hash]) == null) 11 tab[i] = newNode(hash, key, value, null); 12 else { 13 Node<K,V> e; K k; 14 if (p.hash == hash && 15 ((k = p.key) == key || (key != null && key.equals(k)))) 16 e = p; 17 else if (p instanceof TreeNode) 18 e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); 19 else { 20 for (int binCount = 0; ; ++binCount) { 21 if ((e = p.next) == null) { 22 p.next = newNode(hash, key, value, null); 23 if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st 24 treeifyBin(tab, hash); 25 break; 26 } 27 if (e.hash == hash && 28 ((k = e.key) == key || (key != null && key.equals(k)))) 29 break; 30 p = e; 31 } 32 } 33 if (e != null) { // existing mapping for key 34 V oldValue = e.value; 35 if (!onlyIfAbsent || oldValue == null) 36 e.value = value; 37 afterNodeAccess(e); 38 return oldValue; 39 } 40 } 41 ++modCount; 42 if (++size > threshold) 43 resize(); 44 afterNodeInsertion(evict); 45 return null; 46 }
我们着重看第37行以及44行,当插入一个节点的key存在于map中时,会调用37行的afterNodeAccess,当不存在时(即插入一个新节点),会调用44行的afterNodeInsertion。LinkedHashMap的before和after节点设置以及head和tail节点更新也是在这里完成的。
我们进入LinkedHashMap中的这两个方法看看其中做了些什么。首先来看afterNodeAccess:
1 void afterNodeAccess(Node<K,V> e) { // move node to last 2 LinkedHashMap.Entry<K,V> last; 3 if (accessOrder && (last = tail) != e) { 4 LinkedHashMap.Entry<K,V> p = 5 (LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after; 6 p.after = null; 7 if (b == null) 8 head = a; 9 else 10 b.after = a; 11 if (a != null) 12 a.before = b; 13 else 14 last = b; 15 if (last == null) 16 head = p; 17 else { 18 p.before = last; 19 last.after = p; 20 } 21 tail = p; 22 ++modCount; 23 } 24 }
上面的代码判断了accessOrder是否为true,如果是,则为根据访问数序,进入下面的代码块,将p放到tail(最新的位置),这个语意与lru一致;如果不是,就什么都不干,本方法完成,这个语意与fifo一致,因此Cache中构造方法的lru与accessOrder是一致的。
那么afterNodeInsertion又做了什么呢?
1 void afterNodeInsertion(boolean evict) { // possibly remove eldest 2 LinkedHashMap.Entry<K,V> first; 3 if (evict && (first = head) != null && removeEldestEntry(first)) { 4 K key = first.key; 5 removeNode(hash(key), key, null, false, true); 6 } 7 } 8 9 //这个方法是例子中Cache中的实现,当前(插入后)的size大于容量,返回true 10 protected boolean removeEldestEntry(Map.Entry<K,V> eldest) { 11 return size() > cap; 12 }
前7行是afterNodeInsertion内部的实现,判断是否需要删除最老的元素,如果是,就把最老的元素(最先进入的head节点)删除,而需要开发者实现的removeEldestEntry只需要判断size是否大于容量即可,如果大于,就说明缓存容量不够了,要删除head。而通过afterNodeAccess方法实现的lru中head为最久未被使用的元素,fifo中的head为最先进入的元素。
相信看到这里,你对如何使用LinkedHashMap实现LRU和FIFO两种缓存置换算法以及其原理都了解了吧,那么自己尝试动手做一下吧。
(tips:可以看看springboot、hibernate中如何用LinkedHashMap实现的lru缓存哦!)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号