数据采集案例(Flume+Kafka)
架构图
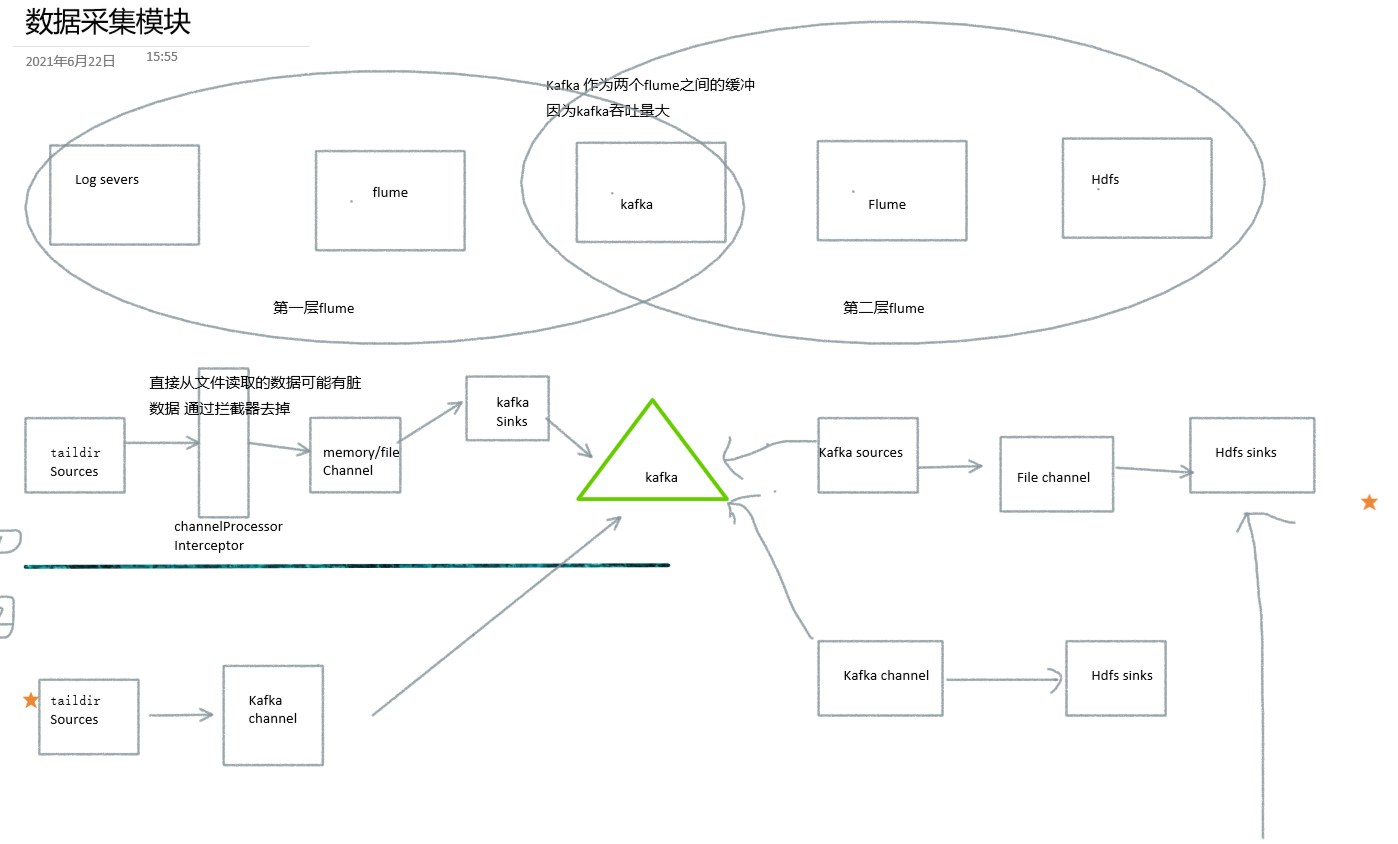
hdfs sinks需要注意零点漂移问题和小文件问题
数据采集案例
第一层采集:将数据从log日志文件采集到的kafka中 使用kafka channel
#file-flume-kafka.conf
#agent
a1.sources = r1
a1.channels = c1
#a1.sinks = k1
#sources
a1.sources.r1.type = TAILDIR
a1.sources.r1.positionFile = /opt/module/flume-1.9.0/position/position3.json
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1= /opt/module/applog/log/app.*
#Interceptor
a1.sources.r1.interceptors = i1
#全类名+创建拦截器对象的bulid方法的对象
a1.sources.r1.interceptors.i1.type =EventHeaderInterceptor.CheckEventInterceptor$MyBuilder
#channels
a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c1.kafka.bootstrap.servers =Ava01:9092,Ava02:9092,Ava03:9092
a1.channels.c1.kafka.topic = test_log
#a1.channels.c1.kafka.consumer.group.id = flume-consumer
a1.channels.c1.parseAsFlumeEvent = false
#关系
a1.sources.r1.channels = c1
#启动:
flume-ng agent --conf $FLUME_HOME/conf/ --conf-file $FLUME_HOME/jobs/file-flume-kafka.conf --name a1 -Dflume.root.logger=INFO,console第一层采集启动脚本
#!bin/bash
if [ $# -lt 1 ]
then echo "{stop|start}"
exit
fi
case $1 in
start)
for i in Ava02 Ava03
do
ssh $i "flume-ng agent --conf $FLUME_HOME/conf/ --conf-file $FLUME_HOME/jobs/file-flume-kafka.conf --name a1 -Dflume.root.logger=INFO,console 1>/opt/module/flume-1.9.0/logs/flume_log 2>&1 & "
done
;;
stop)
for i in Ava02 Ava03
do
ssh $i "ps -ef |grep -v grep | grep file-flume-kafka.conf | awk '{print \$2}' |xargs -n1 kill -9 "
done
;;
*)
echo "滚"
exit
;;
esac第二层采集:将数据从kafka从读取出来写到hdfs上
关于上传到hdfs的时间文件夹的解释:
是在flume sources将数据处理成event格式的时候 source会对event的header添加一点东西
源码 flume-kafka-source KafkaSource类的doprocess()方法
如果他们没有header的话 会在header里面put进去 timestamp(put进去的v的值也是当前系统时间) topic partition key 可能也包括offset..,
可以来个拦截器 自定义下header 将自己想要的timestamp传进去#kafka-flume-hdfs.conf
#agent
a1.sources = r1
a1.channels = c1
a1.sinks = k1
#KafkaSource
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.batchSize = 5000
#最大提交时间间隔
a1.sources.r1.batchDurationMillis = 2000
#从kafka取数
a1.sources.r1.kafka.bootstrap.servers = Ava01:9092,Ava02:9092,Ava03:9092
#哪个topic
a1.sources.r1.kafka.topics = test_log
#群组id 消费者需要指定
a1.sources.r1.kafka.consumer.group.id = flume
#event格式 不需要header
a1.sources.r1.useFlumeEventFormat = false
#channel
a1.channels.c1.type = file
# 检查点文件将要存储的目录
a1.channels.c1.checkpointDir = /opt/module/flume-1.9.0/jobs/checkpointDir
#检查点备份 这个开了下面这个必须要开
#a1.channels.c1.useDualCheckpoints = true
#检查点备份的位置 不可以和 dataDirs 和 checkpointDir 在一个目录
#a1.channels.c1.backupCheckpointDir = /otherdic
#内存中维护file的checkpoint的最大值
a1.channels.c1.capacity = 1000000
#内存中维护的检查点的落盘时间
a1.channels.c1.checkpointInterval=30000
#Interceptor
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type =EventHeaderInterceptor.MyTimestampInterceptor$MyBuilder
#事务容量
a1.channels.c1.transactionCapacity = 10000
#文件写到哪里去
a1.channels.c1.dataDirs = /opt/module/flume-1.9.0/jobs/filechannel
#单个文件最大这么大
a1.channels.c1.maxFileSize =2146435071
# sources往channel放数据 放不进去的等待时间 超过了就删除 重新回去拿
a1.channels.c1.keep-alive=5
#sink
a1.sinks.k1.type = hdfs
#%Y 2020 $y 20
a1.sinks.k1.hdfs.path = /output/flume/events/%y-%m-%d
a1.sinks.k1.hdfs.filePrefix = events-
#文件夹滚动
a1.sinks.k1.hdfs.round = false
#文件滚动
#时间
a1.sinks.k1.hdfs.rollInterval = 10
#大小
a1.sinks.k1.hdfs.rollSize = 134217728
#不按照event个数创建文件
a1.sinks.k1.hdfs.rollCount = 0
#在替换转义序列时使用本地时间(而不是来自事件头的时间戳)。
#false 从event文件的header中获取时间戳
#true 使用本地时间戳 不从里面获取
# 在替换转义序列时使用本地时间(而不是来自事件头的时间戳)。
a1.sinks.k1.hdfs.useLocalTimeStamp= false
#控制输出文件是原生文件
#输出文件是压缩类型的文件 一共三种 SequenceFile(默认),DataStream 或者CompressedStream(压缩)
a1.sinks.k1.hdfs.fileType=CompressedStream
#压缩格式是lzo lzo压缩完的格式是 .lzo_deflate lzop压缩完的格式是.lzo
a1.sinks.k1.hdfs.codeC=lzop
#bind
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
#启动
flume-ng agent --conf $FLUME_HOME/conf/ --conf-file $FLUME_HOME/jobs/kafka-flume-hdfs.conf --name a1 -Dflume.root.logger=INFO,console 第二层采集启动脚本
#!bin/bash
if [ $# -lt 1 ]
then echo "{stop|start}"
exit
fi
case $1 in
start)
for i in Ava03
do
ssh $i "flume-ng agent --conf $FLUME_HOME/conf/ --conf-file $FLUME_HOME/jobs/kafka-flume-hdfs.conf --name a1 -Dflume.root.logger=INFO,console 1>/opt/module/flume-1.9.0/logs/flume_log 2>&1 & "
done
;;
stop)
for i in Ava03
do
ssh $i "ps -ef |grep -v grep | grep kafka-flume-hdfs.conf | awk '{print \$2}' |xargs -n1 kill -9 "
done
;;
*)
echo "滚"
exit
;;
esac
绝不摆烂

 浙公网安备 33010602011771号
浙公网安备 33010602011771号