数据实时增量同步工具CDC之Maxwell和Canal
1.什么是CDC?
CDC是Change Data Capture(变更数据获取)的简称。可以基于增量日志,以极低的侵入性来完成增量数据捕获的工作。核心思想是,监测并捕获数据库的变动(包括数据或数据表的插入、更新以及删除等),
将这些变更按发生的顺序完整记录下来,写入到消息中间件中以供其他服务进行订阅及消费。
1.1什么是变更数据捕获?
CDC是指从源数据库捕获到数据和数据结构(也称为模式)的增量变更,近乎实时地将这些变更,传播到其他数据库或应用程序之处。
通过这种方式,CDC能够向数据仓库提供高效、低延迟的数据传输,以便信息被及时转换并交付给专供分析的应用程序。
与批量复制相比,变更数据的捕获通常具有如下三项基本优势:
CDC通过仅发送增量的变更,来降低通过网络传输数据的成本。
CDC可以帮助用户根据最新的数据做出更快、更准确的决策。例如,CDC会将事务直接传输到专供分析的应用上。
CDC最大限度地减少了对于生产环境网络流量的干扰。
常见的CDC工具有:
maxwell :基于MYSQL的binlog
canal :基于MYSQL的binlog
debezium
flinkcdc
注:sqoop不是CDC工具 sqoop是基于查询的全量数据捕获.
2.Maxwell
Maxwell 是由美国Zendesk开源,用Java编写的MySQL实时抓取软件。
实时读取MySQL二进制日志Binlog,并生成 JSON 格式的消息,
作为生产者发送给 Kafka,Kinesis、RabbitMQ、Redis、Google Cloud Pub/Sub、文件或其它平台的应用程序。
2.1 Maxwell工作原理
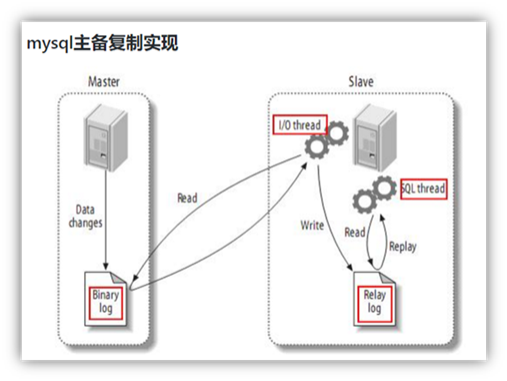
2.1.1 MySQL主从复制过程
<1>Master主库将改变记录,写到二进制日志(binary log)中
<2>Slave从库向mysql master发送dump协议,将master主库的binary log events拷贝到它的中继日志(relay log);
<3>Slave从库读取并重做中继日志中的事件,将改变的数据同步到自己的数据库。
2.1.2 MySQL的binlog
<1> binlog
MySQL的二进制日志可以说MySQL最重要的日志了,它记录了所有的DDL和DML(除了数据查询语句)语句,
以事件形式记录,还包含语句所执行的消耗的时间,MySQL的二进制日志是事务安全型的。
一般来说开启二进制日志大概会有1%的性能损耗。二进制有两个最重要的使用场景:
其一:MySQL Replication在Master端开启binlog,Master把它的二进制日志传递给slaves来达到master-slave数据一致的目的。
其二:自然就是数据恢复了,通过使用mysqlbinlog工具来使恢复数据。
二进制日志包括两类文件:二进制日志索引文件(文件名后缀为.index)用于记录所有的二进制文件,二进制日志文件(文件名后缀为.00000*)记录数据库所有的DDL和DML(除了数据查询语句)语句事件。
binlog文件的滚动:1)达到了滚动的大小 2)mysql服务停止
<2> mysql binlog的格式有三种,分别是STATEMENT,MIXED,ROW。
在配置文件中可以选择配置 binlog_format= statement|mixed|row
在配置文件中可以选择配置 binlog_format= statement|mixed|row
三种格式的区别:
statement
语句级,binlog会记录每次一执行写操作的语句。
相对row模式节省空间,但是可能产生不一致性,比如
update tt set create_date=now()
如果用binlog日志进行恢复,由于执行时间不同可能产生的数据就不同。
优点: 节省空间
缺点: 有可能造成数据不一致。
row
行级, binlog会记录每次操作后每行记录的变化。
优点:保持数据的绝对一致性。因为不管sql是什么,引用了什么函数,他只记录执行后的效果。
缺点:占用较大空间。
mixed
statement的升级版,一定程度上解决了,因为一些情况而造成的statement模式不一致问题
默认还是statement,在某些情况下譬如:
当函数中包含 UUID() 时;
包含 AUTO_INCREMENT 字段的表被更新时;
执行 INSERT DELAYED 语句时;
用 UDF 时;
会按照 ROW的方式进行处理
优点:节省空间,同时兼顾了一定的一致性。
缺点:还有些极个别情况依旧会造成不一致,另外statement和mixed对于需要对binlog的监控的情况都不方便。
综合上面对比,Maxwell想做监控分析,选择row格式比较合适。
2.1.3 修改mysql配置
sudo vim /etc/my.cnf
#添加进去
server-id= 1
#生成bitlog文件的前缀
log-bin=mysql-bin
binlog_format=row
binlog-do-db=gmall_rt
#想监控多个库就多加几个binlog-do-db
#重启mysql服务 让配置生效
systemctl restart mysqld2.1.4 Maxwell的工作原理
很简单,就是把自己伪装成slave,假装从master复制数据
3.Maxwell安装配置
3.1 mysql中创建Maxwell账号和元数据库
--创建maxwell元数据库
CREATE DATABASE maxwell ;
--创建maxwell账号和权限
GRANT ALL ON maxwell.* TO 'maxwell'@'%' IDENTIFIED BY '123456';
GRANT SELECT ,REPLICATION SLAVE , REPLICATION CLIENT ON *.* TO maxwell@'%';3.2 修改maxwell配置文件
--复制配置文件 在maxwell根目录下
cp config.properties.example config.properties
--修改配置文件
vim config.properties
producer=kafka
#用,分隔
kafka.bootstrap.servers=Ava01:9092,Ava02:9092,Ava03:9092
#需要添加
kafka_topic=topic名字 发送到kafka的哪个topic #ods_base_db_m
# mysql login info
host=Ava01
user=maxwell
password=123456
#需要添加 后续初始化会用
client_id=maxwell_1
3.3 maxwell发送数据到消息队列的分区方式
--发送数据的分区方式是可选的
--可以对数据进行分区,解决数据倾斜问题,
--默认还是输出到指定Kafka主题的一个kafka分区,因为多个分区并行可能会打乱binlog的顺序
--如果要提高并行度,首先设置kafka的分区数>1,然后设置producer_partition_by属性
--database是指将database名字当做key 同一个数据库的所有表都会分配到同一个分区
--table table名字作为key 同一张表的数据发送到同一个分区
--primary_key 表中的主键为key 数据分配是最均匀的 但是可能会乱序
--transaction_id 事务id
--column 列名
--一般情况下 业务数据要保持消费顺序的话 采用 database+table 为key 将同一个库下的同一张表的数据发送到一个分区 因为kafka只能保证统一分区消费有序
#producer_partition_by=database # [database, table, primary_key, transaction_id, column]3.4 启动 需要指定配置文件
./maxwell --config /opt/module/maxwell-1.25.0/config.propertie3.5 maxwell发送数据 测试
#启动消费者
kafka-console-consumer.sh --bootstrap-server Ava01:9092 --topic maxwell_test在mysql配置文件里指定哪个库生成 binlog 就在那个库里执行一个update或者insert测试一下 观察消费者消费到的数据
4. Maxwell发送的数据
4.1 数据条数:
一条sql影响了N行, maxwell会发送N条消息 也就是会有 N个json 比如一个update语句影响了2条 maxwell会产生两条json
4.2 数据格式
DML
{
"database": "gmall_rt",
"table": "cart_info",
"type": "insert",
"ts": 1631706456,
"xid": 7886,
"xoffset": 13987,
"data": {
"id": 148278,
"user_id": "2059",
"sku_id": 13,
"cart_price": 4188,
"sku_num": 1,
"img_url": "http://47.93.148.192:8080/group1/M00/00/02/rBHu8l-sklaALrngAAHGDqdpFtU741.jpg",
"sku_name": "华为 HUAWEI P40 麒麟990 5G SoC芯片 5000万超感知徕卡三摄 30倍数字变焦 6GB+128GB亮黑色全网通5G手机",
"is_checked": null,
"create_time": "2021-09-15 19:47:33",
"operate_time": null,
"is_ordered": 0,
"order_time": null,
"source_type": "2401",
"source_id": null
}
}DDL
{
"type": "table-create",
"database": "gmall_rt",
"table": "user_info",
"def": {
"database": "gmall_rt",
"charset": "utf8",
"table": "user_info",
"columns": [
{
"type": "int",
"name": "id",
"signed": true
},
{
"type": "varchar",
"name": "name",
"charset": "utf8"
}
],
"primary-key": [ ]
},
"ts": 1631343066000,
"sql": "create table user_info(
id int,
`name` varchar(25)
)"
}4.3 maxwell的元数据
maxwell的元数据库的position表,记录读取的binlog文件和位置
支持断点还原

4.5 HA
maxwell一般不支持高可用,但是 较新版本,已经添加了 ha的功能,但是还在实验中
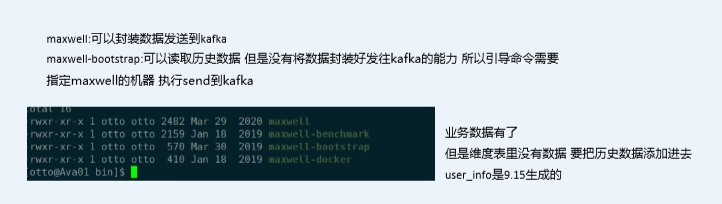
4.6 maxwell初始化功能
maxwell支持历史数据同步功能,也就是将没有生成binlog之前的数据也读取出来
支持 SELECT * FROM table 的方式进行全量数据初始化
因为本身记录了position所以最大程度的保持了数据一致
--执行命令
bin/maxwell-bootstrap --user maxwell --password 123456 --host Ava01 --database gmall_rt --table user_info --client_id maxwell_1
#参数解释
--user maxwell
数据库分配的操作 maxwell数据库的用户名
--password 123456
数据库分配的操作maxwell数据库的密码
--host
数据库主机名
--database
数据库名
--table
表名
--client_id
maxwell-bootstrap不具备将数据直接导入kafka或者hbase的能力,
通过--client_id指定将数据交给哪个maxwell进程处理,在maxwell的conf.properties中配置
5.maxwell的启动脚本 指定配置
vim /home/otto/bin/maxwell.sh
/opt/module/maxwell-1.25.0/bin/maxwell --config /opt/module/maxwell-1.25.0/config.properties >/dev/null 2>&1 &
====================================================Canal=========================================================================
先说Canal和Maxwell的区别:
1、maxwell支持断点还原、未来支持HA
canal支持HA(高可用),不支持断点还原
2、数据格式
maxwell轻量级,只有一些核心关键的字段
canal啥都有,old、sql、.........
data字段:如果一条sql影响了N行数据
maxwell有N个json,每个都是json串 方便处理
canal只有一个json,所以是一个数组 处理时稍显麻烦
3、maxwell支持历史数据同步
canal不支持历史数据同步,如果需要实现的话 可以新建一张临时表,将需要同步的数据插入临时表,使用canal监听临时表(数据重放、回溯)
4. 数字类型
当原始数据是数字类型时,maxwell会尊重原始数据的类型不增加双引,变为字符串。canal一律转换为字符串。
5.带原始数据字段定义
canal数据中会带入表结构。maxwell更简洁。
1.Canal
canal是用java开发的基于数据库增量日志解析,提供增量数据订阅&消费的中间件。
目前,canal主要支持了MySQL的binlog解析,解析完成后才利用canal client来处理获得的相关数据。(数据库同步需要阿里的otter中间件,基于canal)。
1.1 Canal的使用场景:
(1) 原始场景: 阿里otter中间件的一部分
otter是阿里用于进行异地数据库之间的同步框架,canal是其中一部分。
(2) 常见场景1:更新缓存
(3) 常见场景2:抓取业务数据新增变化表,用于制作拉链表。
(4) 常见场景3:抓取业务表的新增变化数据,用于制作实时统计(我们就是这种场景)
1.2 Canal的工作原理
和Maxwell类似 都是假装skave读取binlog
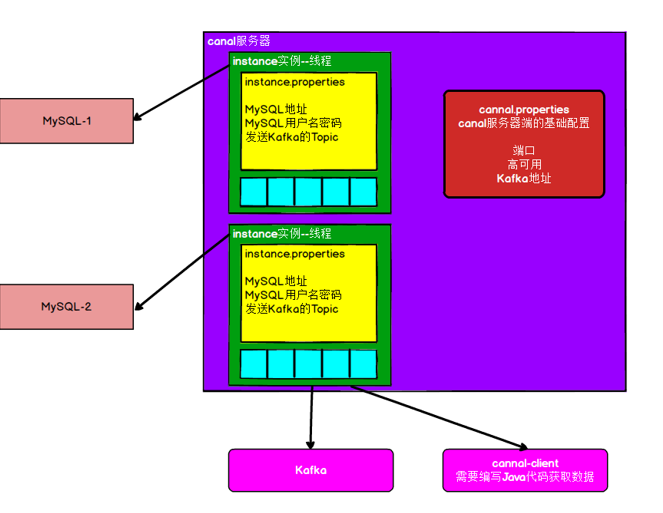
1.3 Canal的架构
1.4 安装配置
#给Canal也创建一个Mysql用户
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%' IDENTIFIED BY '密码' ;
#注:Canal的压缩包解压之后是散的 所以需要提前创建目录
#解压之后
cd /opt/module/canal/conf
vim canal.properties
注: canal的端口号默认是11111
# 修改canal的输出model,默认tcp,改为输出到kafka
# tcp, kafka, RocketMQ
canal.serverMode = kafka
#消息队列的配置项
##################################################
######### MQ #############
##################################################
canal.mq.servers = Ava01:9092,Ava02:9092,Ava03:9092
canal.mq.retries = 0
canal.mq.batchSize = 16384
canal.mq.maxRequestSize = 1048576
canal.mq.lingerMs = 100
canal.mq.bufferMemory = 33554432
canal.mq.canalBatchSize = 50
canal.mq.canalGetTimeout = 100
canal.mq.flatMessage = true
canal.mq.compressionType = none
canal.mq.acks = all
#canal.mq.properties. =
canal.mq.producerGroup = test
# Set this value to "cloud", if you want open message trace feature in aliyun.
canal.mq.accessChannel = local
# aliyun mq namespace
#canal.mq.namespace =
#创建多个实例:
#一个canal服务中可以有多个instance,conf/下的每一个example即是一个实例,
#每个实例下面都有独立的配置文件。默认只有一个实例example,如果需要多个实例处理不同的MySQL数据的话,直接拷贝出多个example,
#并对其重新命名,命名和配置文件中指定的名称一致,然后修改canal.properties中的canal.destinations=实例1,实例2,实例3。
canal.destinations = example
#只读取一个MySQL数据,所以只有一个实例,这个实例的配置文件在conf/example目录下
cd /opt/module/canal/conf/example
vim instance.properties
#配置数据库地址和用户名密码
canal.instance.master.address=Ava01:3306
canal.instance.dbUsername=canal
canal.instance.dbPassword=123456
# mq config
# 修改输出到Kafka的主题以及分区数
canal.mq.topic=canal_test
canal.mq.partition=0
# hash partition config
#canal.mq.partitionsNum=3
#canal.mq.partitionHash=test.table:id^name,.*\\..*
注意:默认还是输出到指定Kafka主题的一个kafka分区,因为多个分区并行可能会打乱binlog的顺序
如果要提高并行度,首先设置kafka的分区数>1,然后设置canal.mq.partitionHash属性2.Canal测试 (和上面maxwell测试一样)
3.CanalHA模式
这种zookeeper为观察者监控的模式,只能实现高可用,而不是负载均衡.
即同一时点只有一个canal-server节点能够监控某个数据源,只要这个节点能够正常工作,
那么其他监控这个数据源的canal-server只能做stand-by,直到工作节点停掉,其他canal-server节点才能抢占。
因为有一个stand-by也要占用资源,同时canal传输数据宕机的情况也比较少,所以好多企业是不配置canal的高可用的。
4.Canal数据格式
#ddl
{
"data": null,
"database": "gmall_rt",
"es": 1631347983000,
"id": 2,
"isDdl": true,
"mysqlType": null,
"old": null,
"pkNames": null,
"sql": "create table test_log (id VARCHAR(5) ,name VARCHAR(20))",
"sqlType": null,
"table": "test_log",
"ts": 1631347983479,
"type": "CREATE"
}
#影响多条是数组 处理确实不如maxwell方便
{
"data": [
{
"id": "1",
"name": "zs"
},
{
"id": "2",
"name": "xf"
}
],
"database": "gmall_rt",
"es": 1631348033000,
"id": 3,
"isDdl": false,
"mysqlType": {
"id": "VARCHAR(5)",
"name": "VARCHAR(20)"
},
"old": null,
"pkNames": null,
"sql": "",
"sqlType": {
"id": 12,
"name": 12
},
"table": "test_log",
"ts": 1631348033643,
"type": "INSERT"
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号