简单梳理一下Hive笔记
1.Hive 简介
Hive:由Facebook开源用于解决海量结构化日志的数据统计工具。
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能。
HIve本质就是将HQL转换成MapReduce程序,也有其他的上级替代引擎比如spark和Tez
2.Hive安装配置 略过
3.Hive参数配置的方式
Hive在执行过程过,有时候需要通过修改参数配置的方式来完成一些别的操作,比如控制几个reduce或者是是够开启严格模式等..
(1)配置文件方式
默认配置文件:hive-default.xml
用户自定义配置文件:hive-site.xml
(2)命令行参数方式
启动Hive时,可以在命令行添加-hiveconf param=value来设定参数。
bin/hive -hiveconf mapred.reduce.tasks=10; --注意仅对本次hive启动生效
--查看参数设置
set mapred.reduce.tasks;
(3)参数声明方式
可以在HQL中使用SET关键字设定参数
set mapred.reduce.tasks=100; --也是对本次hive启动生效 查看方式同上
参数的优先级方式依次递增,即配置文件<命令行参数<参数声明.但是系统级别的参数设置 必须采用前两种,比如log4j的日志设定因为那些参数的读取在会话建立以前已经完成了。4.HIve数据类型
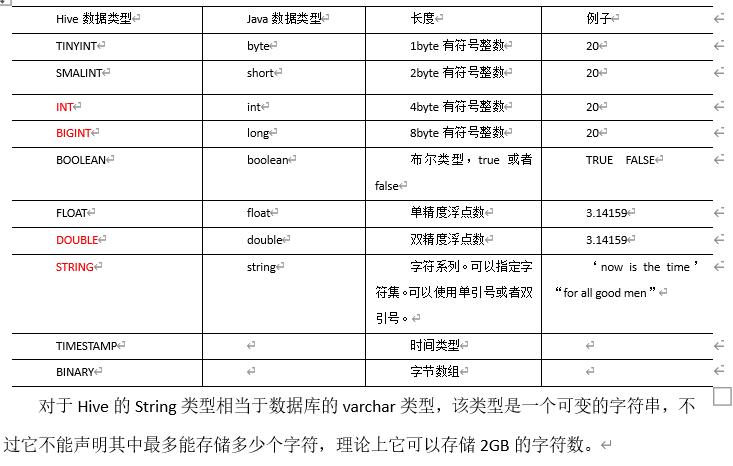
4.2 集合数据类型
STRUCT :如果某个列的数据类型是STRUCT{first STRING, last STRING},那么第1个元素可以通过字段.first来引用。相关方法有 name_struct
MAP :AP是一组键-值对元组集合,使用数组表示法可以访问数据。例如,如果某个列的数据类型是MAP,
其中键->值对是'first'->'John'和'last'->'Doe',那么可以通过字段名['last']获取最后一个元素 str_to_map(string,seq,seq)
ARRAY:数组是一组具有相同类型和名称的变量的集合。这些变量称为数组的元素,每个数组元素都有一个编号,编号从零开始。
例如,数组值为['John', 'Doe'],那么第2个元素可以通过数组名[1]进行引用。列转行 collect_set和collect_list
一般这些集合数据类型都和json格式离不开关系
json格式解析:
{"Name":"zzz","MyWife":["ava","18"],"MySon":[{"Name":"Son1"},{"Name":"Son2"},{"Name":"Son3"}]}
从上面的结构来看,是一个对象里面的第一项是个属性,
第二项是一个数组,
第三个是包含有多个对象的数组。 "MySon":[{"Name":"Son1"},{"Name":"Son2"},{"Name":"Son3"}]
调用起来,也是一层一层访问,对象的属性用.(点)叠加,数组用 [下标] 来访问。4.3 hive数据类型转换
(1)任何整数类型都可以隐式地转换为一个范围更广的类型,如TINYINT可以转换成INT,INT可以转换成BIGINT。
(2)所有整数类型、FLOAT和STRING类型都可以隐式地转换成DOUBLE。
(3)TINYINT、SMALLINT、INT都可以转换为FLOAT。
(4)BOOLEAN类型不可以转换为任何其它的类型。
(5)使用case(a as 数据类型) 进行强制类型转换 转换失败表达式返回控制null5.数据库基本操作
database.sql
--创建数据库:
CREATE DATABASE [IF NOT EXISTS] database_name
[COMMENT database_comment]
[LOCATION hdfs_path] --不指定路径的话 默认路径是/user/hive/warehouse/*.db。
[WITH DBPROPERTIES (property_name=property_value, ...)];
--显示数据库 在Hive中,我们使用show databases like 'test*'来模糊匹配数据库名,此处like可以省略。
show databases;
--查看数据库信息
desc database db_name;
--查看数据库详细信息
desc database extended db_name;
--切换数据库
use db_name;
--修改数据库 数据库的备注信息
alter database db_name set dbproperties('createtime'='20170830');
--删除数据库 最好使用if exists是否存在 只能删除空的数据库
drop database if exists db_name;
--强制删除 数据库不为空也能删除
drop database db_name cascade;
--exp:
create database if not exists my_db
comment "nametable"
location "/user/hive/my_db"
with dbproperties("createtime"="20200605","name"="xiao zhang");6.表操作
table.sql
--建表
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name -- 指定表名, EXTERNAL: 外部表
[(col_name data_type [COMMENT col_comment], ...)] -- 指定列名 列类型 列描述信息 ...
[COMMENT table_comment] -- 指定表的描述信息
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] -- 指定分区表的分区列
[CLUSTERED BY (col_name, col_name, ...) -- 指定分桶表的分桶列
[SORTED BY (col_name [ASC|DESC], ...)] -- 指定排序列
[INTO num_buckets BUCKETS] -- 指定桶数
[ROW FORMAT delimited fields terminated by ... ] -- 指定字段与字段的分隔符
[collection items terminated by ...] -- 指定集合元素的分隔符
[map keys terminated by ...] -- 指定map集合的kv的分隔符
[lines terminated by ... ] -- 指定多行数据的分隔符
[STORED AS file_format] -- 指定数据在文件中的存储格式
[LOCATION hdfs_path] -- 指定表在hdfs中对应的路径
[TBLPROPERTIES (property_name=property_value, ...)] -- 指定表的描述信息
[AS select_statement] -- 基于查询建表
[like ... ] -- 复制表结构
exp:
create
table if not exists person(
name string,friends array<string>,childs map<String ,int>,address struct<street:string,city:string,code:int>)
row format delimited fields terminated by","
collection items terminated by "_"
map keys terminated by ":"
lines terminated by "\n";
tblproperties(
"skip.header.line.count"="n", --跳过文件行首n行 由于hive插入外部表的逻辑 会一直生效 也就是之后从其他表insert的时候也会去掉第一条
"skip.footer.line.count"="n" --跳过文件行尾n行
)
--可以在创建表的时候指定好数据存储目录 提前准备好数据 不用load 表里直接就有数
create external table if not exists student5(
id int, name string
)
row format delimited fields terminated by '\t'
location '/student';
--查看详细信息
desc extended table_name
--常用的存储类型
[STORED AS file_format]
SEQUENCEFILE(二进制序列文件)、TEXTFILE(文本)、RCFILE(列式存储格式文件)
如果文件数据是纯文本,可以使用STORED AS TEXTFILE。如果数据需要压缩,使用 STORED AS SEQUENCEFILE。
--内部表和外部表的区别
内部表:Hive默认情况下会将这些表的数据存储在由配置项hive.metastore.warehouse.dir(例如,/user/hive/warehouse)所定义的目录的子目录下。
当我们删除一个管理表时,Hive也会删除这个表中数据。管理表不适合和其他工具共享数据。
外部表:使用EXTERNAL关键字创建.删除该表并不会删除掉这份数据,不过描述表的元数据信息会被删除掉。
--查看外部表的信息 Table Type是EXTERNAL_TABLE代表是外部表 MANAGED_TABLE代表是内部表(管理表)
desc formatted dept;
Table Type: EXTERNAL_TABLE
Table Type: MANAGED_TABLE
--删除外部表 元数据会被删除 但是数据还在
drop table dept;
--内部表 外部表的转换
alter table test2 set tblproperties("EXTERNAL"="FALSE"); 变成管理表
alter table test2 set tblproperties("EXTERNAL"="TRUE"); 变成外部表
--表的ddl操作
--重命名表
ALTER TABLE table_name RENAME TO new_table_name
--更新列 可以通过first或者after指定更新后的列在哪个位置
ALTER TABLE table_name CHANGE [COLUMN] col_old_name col_new_name column_type [COMMENT col_comment] [FIRST|AFTER column_name]
--增加和替换列 ADD是代表新增一字段,字段位置在所有列后面(partition列前),REPLACE则是表示替换表中所有字段。
ALTER TABLE table_name ADD|REPLACE COLUMNS (col_name data_type [COMMENT col_comment], ...)
--增删改查表分区
alter table table_name add partition(day='20200404') ;
alter table table_name add partition(day='20200405') partition(day='20200406');
alter table table_name drop partition (day='20200406');
alter table table_name drop partition (day='20200404'), partition(day='20200405');
-- 查看分区表有多少分区
show partitions table_name;
--查看分区表结构
desc formatted table_name;
--二级分区 一般都是月+日的分区
create table dept_partition2(
deptno int, dname string, loc string
)
partitioned by (day string, hour string)
row format delimited fields terminated by '\t';
select * from dept_partition2 where day='20200401' and hour='12';7.装载数据
load
load data [local] inpath '数据的path' [overwrite] into table student [partition (partcol1=val1,…)];
load data local inpath "/opt/module/hive-3.1.2/student.txt" into table student;
load data local inpath "/opt/module/hive-3.1.2/test1.txt" overwrite into table test; --overwrite 表示覆盖 否则是追加insert
--通过查询语句向表中插入数据(Insert)
--注意 insert into:以追加数据的方式插入到表或分区,原有数据不会删除
-- insert overwrite:会覆盖表中已存在的数据 分两段执行 先清空再插入 而且如果查询结果为空 不会覆盖 (空值不覆盖原则)
--基本模式插入(根据单张表查询结果)
insert overwrite table student_par select id, name from student ;
--多表(多分区)插入模式(根据多张表查询结果) from上置
from student
insert overwrite table student partition(month='201707')
select id, name where month='201709'
insert overwrite table student partition(month='201706')
select id, name where month='201709';
--根据查询语句的结果建表
create table if not exists new_table_name as
select id, name from student;8.hive的数据导入和导出
导入导出
--hive数据的导入和导出
--insert命令导出数据 overwrite会把文件夹里面文件删除干净就剩个导出来的
insert overwrite local directory "/opt/module/hive-3.1.2/test" row format delimited fields terminated by "\t"
select * from test;
--导出到hdfs
insert overwrite directory "/insert_result" row format delimited fields terminated by "\t"
select * from test;
insert overwrite local directory "/opt/module/hive-3.1.2/test/sort" row format delimited fields terminated by "\t"
select deptno,sal from test.emp distribute by deptno sort by deptno ,sal asc;
--通过hadoop命令 直接将hive的数据文件导出
dfs -get '/user/hive/warehouse/test.db/test' /opt/module/hive-3.1.2/test
--shell脚本导出 >>追加 >覆盖
hive -e "select * from test.zjq2">zjq2.txt
hive -f sql.sql>zjq2.txt
--Export 导出 export和import主要用于两个Hadoop平台集群之间Hive表迁移。
--导出到hdfs 包含元数据
export table test.zjq2 to '/insert_result';
--导入 import Import 数据 必须要是export导出之后的
import table zjq2 from '/insert_result' ;
--Sqoop导入导出 参考下文
https://www.cnblogs.com/zzz01/p/14955050.html9.查询
select
--查询
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[ORDER BY col_list] --全局排序 只有一个reduce
[CLUSTER BY col_list --分组排序同一字段简写 只能升序
| [DISTRIBUTE BY col_list] --分组
[SORT BY col_list] --排序
]
[LIMIT number] --limit 2,3 从2开始输出3行
--like
like是模糊查询 还有Rlike RLIKE子句是Hive中这个功能的一个扩展,其可以通过Java的正则表达式这个更强大的语言来指定匹配条件。
--逻辑运算符
or not and
--having
(1)where后面不能写分组函数,而having后面可以使用分组函数。
(2)having只用于group by分组统计语句。
--full join
将会返回所有表中符合WHERE语句条件的所有记录。如果任一表的指定字段没有符合条件的值的话,那么就使用NULL值替代。
--笛卡尔积
笛卡尔积会在下面条件下产生
(1)省略连接条件
(2)连接条件无效
(3)所有表中的所有行互相连接
--排序1 全局排序
Order By:全局排序,只有一个Reducer
ASC(ascend): 升序(默认)
DESC(descend): 降序
--排序2 每个reduce内部排序
Sort By:对于大规模的数据集order by的效率非常低。在很多情况下,并不需要全局排序,此时可以使用sort by。
Sort by为每个reducer产生一个排序文件。每个Reducer内部进行排序,对全局结果集来说不是排序。
--先设定reduce个数
set mapreduce.job.reduces=3;
--一般来说sort by 都和 Distribute By 一起使用 因为区内有序需要先有区才能排序 不指定分区方式的话是随机分区
select * from emp sort by deptno desc;
--分区(Distribute By)
在有些情况下,我们需要控制某个特定行应该到哪个reducer,通常是为了进行后续的聚集操作。distribute by 子句可以做这件事。distribute by类似MR中partition(自定义分区),进行分区,结合sort by使用
distribute by的分区规则是根据分区字段的hash码与reduce的个数进行模除后,余数相同的分到一个区。
Hive要求DISTRIBUTE BY语句要写在SORT BY语句之前。
--Cluster By
当distribute by和sort by字段相同时,可以使用cluster by方式。
cluster by除了具有distribute by的功能外还兼具sort by的功能。
但是排序只能是升序排序,不能指定排序规则为ASC或者DESC。
--这两个是等价的
select * from emp cluster by deptno;
select * from emp distribute by deptno sort by deptno;10.分区表
--分区表 注意:分区字段不能是表中已经存在的数据,可以将分区字段看作表的伪列。
-- 分区表load数据的时候 必须要指定分区
load data local inpath '/opt/module/hive/datas/dept_20200401.log' into table dept_partition partition(day='20200401');
--hive 指定分区插入 目标表分区字段不算一个字段
insert into table dept_partition_dy partition(loc=1700) select deptno,dname from dept where loc =1700;11.动态分区(重要)
动态分区
--动态分区 (常用)
关系型数据库中,对分区表Insert数据时候,数据库自动会根据分区字段的值,将数据插入到相应的分区中,Hive中也提供了类似的机制,
即动态分区(Dynamic Partition),只不过,使用Hive的动态分区,需要进行相应的配置。
--1.开启动态分区功能 默认是true 开启
hive.exec.dynamic.partition=true
--2.设置动态分区的模式 动态必须设置此参数。
打开动态分区后,动态分区的模式为strict和nonstrict。
strict可设置为静态和半动态,要求至少包含一个静态分区列 其他的分区字段可以设置为动态。
nonstrict可设置为静态、半动态和动态,
set hive.exec.dynamic.partition.mode = nonstrict;
--3.在所有执行MR的节点上,最大一共可以创建多少个动态分区。默认1000
hive.exec.max.dynamic.partitions=1000
--4.在每个执行MR的节点上,最大可以创建多少个动态分区 参数需要根据实际的数据来设定 默认是100 如果表的动态分区数大于100 会报错
hive.exec.max.dynamic.partitions.pernode=100
--5.整个MR Job中,最大可以创建多少个HDFS文件。默认100000
hive.exec.max.created.files=100000
--6.当有空分区生成时,是否抛出异常。一般不需要设置。默认false
hive.error.on.empty.partition=false
--设置之后 也可以先load到普通表 在insert进去分区表 动态分区会自动生成分区12.分桶表
分桶表
什么是分桶: 分桶是将数据集分解成更容易管理的若干部分的另一个技术。
分区针对的是数据的存储路径;分桶针对的是数据文件。
分桶规则: Hive的分桶采用对分桶字段的值进行哈希,然后除以桶的个数求余的方 式决定该条记录存放在哪个桶当中
分桶表的操作:
(1)reduce的个数设置为-1,让Job自行决定需要用多少个reduce或者将reduce的个数设置为大于等于分桶表的桶数
(2)从hdfs中load数据到分桶表中,避免本地文件找不到问题
(3)不要使用本地模式 (集群模式 不知道从哪个机器的loacl inpath 去load)
--分桶表 分区针对的是数据的存储路径;分桶针对的是数据文件
create table stu_bucket(id int, name string)
clustered by(id) --分区排序是按照哪个字段来的 不然怎么分桶 Hive的分桶采用对分桶字段的值进行哈希,然后除以桶的个数求余的方 式决定该条记录存放在哪个桶当中
into 4 buckets --分几个桶
row format delimited fields terminated by '\t';
--查看分桶个数
desc formatted stu_bucket;
Num Buckets: 413.抽样查询
抽样查询
--抽样查询
对于非常大的数据集,有时用户需要使用的是一个具有代表性的查询结果而不是全部结果。Hive可以通过对表进行抽样来满足这个需求。
语法: TABLESAMPLE(BUCKET x OUT OF y)
select * from stu_buck tablesample(bucket 1 out of 4 on id);
注意:x的值必须小于等于y的值14.hive函数
--Hive 函数 内置函数 自定义UDF函数 自定义UDTF函数 自定义UDAF函数 另外一篇博文细讲
https://www.cnblogs.com/zzz01/p/15102421.html15.Hive的压缩和存储
https://www.cnblogs.com/zzz01/p/15102525.html16.hive脚本中注意
""和''的区别
--hive 脚本中""和''的区别
vim test.sh
--在文件中添加如下内容
#!/bin/bash
do_date=$1
echo '$do_date'
echo "$do_date"
echo "'$do_date'"
echo '"$do_date"'
echo `date`
--2)查看执行结果
test.sh 2020-06-14
$do_date
2020-06-14
'2020-06-14'
"$do_date"
2020年 06月 18日 星期四 21:02:08 CST
--3)总结:
(1)单引号不取变量值
(2)双引号取变量值
(3)反引号`,执行引号中命令
(4)双引号内部嵌套单引号,取出变量值
(5)单引号内部嵌套双引号,不取出变量值17.其他
--执行hive -e 的时候 指定路径需要使用单引号''
hive -e "load data local inpath '/opt/data/regoods.txt' into table test.regoods;"
--hive -f 文件路径
启动hive的时候执行这个文件
hive order by 后跟 别名,HIve只能用聚合函数的别名排序,不可以用聚合函数的表达式排序18.多维分析(具体查看官网多维分析示例)
点击查看代码
--多维分析
select deptno,sex,count(1) from groupingsets group by deptno,sex;
等价于
select deptno,sex,count(1) from groupingsets group by deptno ,sex grouping sets((deptno,sex))
--相当于在上面的基础上在union上一个group by deptno 和 group by sex的结果
select deptno,sex,count(1) from groupingsets group by deptno ,sex grouping sets(deptno,sex,(deptno,sex))
--group by deptno 和 group by sex的结果
select deptno,sex,count(1) from groupingsets group by deptno ,sex grouping sets(deptno,sex);
启动hive
nohup 1>/opt/module/hive-3.1.2/logs/hiveserver2.log 2>&1 &
nohup /opt/module/hive-3.1.2/logs/metastore.log &
nohup: 放在命令开头,表示不挂起,也就是关闭终端进程也继续保持运行状态
0:标准输入
1:标准输出
2:错误输出
2>&1 : 表示将错误重定向到标准输出上
&: 放在命令结尾,表示后台运行
一般会组合使用: nohup [xxx命令操作] 1> file 2>&1 & , 表示将xxx命令运行的
结果输出到file中,并保持命令启动的进程在后台运行。hive服务启动脚本:
hiveservices.sh
#!/bin/bash
HIVE_LOG_DIR=/opt/module/hive-3.1.2/logs/
if [ ! -d $HIVE_LOG_DIR ]
then
mkdir -p $HIVE_LOG_DIR
fi
#检查进程是否运行正常,参数1为进程名,参数2为进程端口
function check_process()
{
pid=$(ps -ef 2>/dev/null | grep -v grep | grep -i $1 | awk '{print $2}')
ppid=$(netstat -nltp 2>/dev/null | grep $2 | awk '{print $7}' | cut -d '/' -f 1)
echo $pid
[[ "$pid" =~ "$ppid" ]] && [ "$ppid" ] && return 0 || return 1
}
function hive_start()
{
metapid=$(check_process HiveMetastore 9083)
cmd="nohup hive --service metastore >$HIVE_LOG_DIR/metastore.log 2>&1 &"
cmd=$cmd" sleep 4; hdfs dfsadmin -safemode wait >/dev/null 2>&1"
[ -z "$metapid" ] && eval $cmd || echo "Metastroe服务已启动"
server2pid=$(check_process HiveServer2 10000)
cmd="nohup hive --service hiveserver2 >$HIVE_LOG_DIR/hiveServer2.log 2>&1 &"
[ -z "$server2pid" ] && eval $cmd || echo "HiveServer2服务已启动"
}
function hive_stop()
{
metapid=$(check_process HiveMetastore 9083)
[ "$metapid" ] && kill $metapid || echo "Metastore服务未启动"
server2pid=$(check_process HiveServer2 10000)
[ "$server2pid" ] && kill $server2pid || echo "HiveServer2服务未启动"
}
case $1 in
"start")
hive_start
;;
"stop")
hive_stop
;;
"restart")
hive_stop
sleep 2
hive_start
;;
"status")
check_process HiveMetastore 9083 >/dev/null && echo "Metastore服务运行正常" || echo "Metastore服务运行异常"
check_process HiveServer2 10000 >/dev/null && echo "HiveServer2服务运行正常" || echo "HiveServer2服务运行异常"
;;
*)
echo Invalid Args!
echo 'Usage: '$(basename $0)' start|stop|restart|status'
;;
esac
绝不摆烂

 浙公网安备 33010602011771号
浙公网安备 33010602011771号