
参考链接
https://raft.github.io/ 可手动调整参数,模拟不同场景
http://thesecretlivesofdata.com/raft/ 动态演示 强烈推荐
raft协议解决在分布式系统中的一致性问题,其容错性和性能基本上和Paxos相同,但是其复杂程度,易于理解程度都优于Paxos
raft的角色
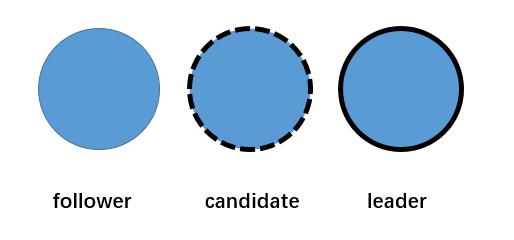
raft中有三种角色,分别为 follower-追随者,candidate-候选人,leader-领导者
raft集群中的节点都在这个三个状态中转换,并且同一时刻只能为其中一种角色,
ps,在这三种角色中follower,leader是稳定的角色,即会长期稳定存在的,candidate为临时角色,正常只会存在很短的时间,
正常情况下,一个raft集群只会有一个leader存在,如果存在两个(比如发生网络分区),那么能正常使用的最多也只有一个
raft的选举
两种场景下会触发选举,1)集群刚刚初始化完成,处于初始状态,此时集群节点都处于follower状态,2)原有的leader节点没有及时的给集群的follower节点发送心跳,此时会触发选举机制,follower节点会发现没有接受到leader的心跳,等待一段时间后自身进入candidate状态,这段时间称之为选举超时时间,具体为150ms~300ms的随机时间,
某个follower先超时,那么它自身状态会从follower切换为candidate-选举人,并且1)立即投自已一票(vote for self),2)开始新任期term,如果之前没有term信息,则任期为1,否则为term +1, 3) 向其他所有follower发送 选举请求,请求其他节点投票给自己,如果此candidate获得超过半数的follower的投票,那么他就当选为leader,将自身状态转化为leader
从其他follower角度来看,此follower在等待 选举超时的过程中,收到了其他candidate的选举请求,1)重置选举超时时间,即重新开始等待超时,2)判断选举请求来源的term和自身的term进行对比,如果来源term比自身的大,且未在此term内投过票,则给来源candidate投票。如果收到的选举请求term比自身的term还小,那么显然不用理会。
一些情况的考虑:
1,ABCDE五个节点,其中A目前是leader切宕机,BCDE没有等到A的心跳,认为A已经宕机,由于没有A的心跳也不会重置选举超时时间。一段时间后,B节点timeout,则进入candidate角色,将自身term加1,比如目前为2,并向其他 所有节点 发送投票请求;几乎同时C节点timeout(此时没有收到B节点的投票请求),自身term置为2,进入candidate角色并向其他 所有节点 发送投票请求。
对于DE两个节点而言,先收到谁的投票请求就会给谁投票,这里假设投票给B,那么B节点就有个3张票。超过大多数,成功当选为leader,
对于BC节点而言,他们会收到对方发出的投票请求,且发现来源term和自身一致,但是由于BC节点在进入candidate后就会立即给自己投了一票,所以就不满足 在来源term内没有投票的限制,故不会给 对方投票,符合直观的认知,
ps:是否可以设定为 收到的来源term和自身一致,就不投票呢?我认为应该也行,term的变化一定伴随着投票的操作(我猜的),但可能在更复杂的情况下会有问题,之后在考虑
对于整个集群而言,B成为leader,且term为2,C竞选失败,term为2,此时的还想着再来一次竞选,当然这要等待一个选举超时时间,,但是B已经成为leader了,他会给所有的节点发送心跳,重置所有节点的选举超时时间,(这就是为何要给所有节点发送心跳,而不是给投票给自己的节点发送投票的原因吧),最终实现了集群的一致性
2,在1的基础上,将情况再复杂些。
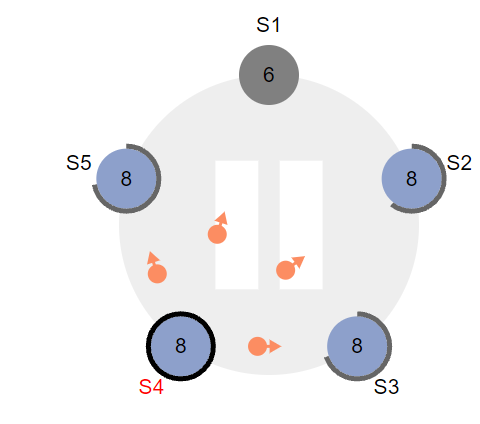
2.1 现有集群S1~5,S1节点宕机,S4,S3节点timeout,在投票环节各自得到两票,所以这两都没有获得大多数的节点认同,故没有选出leader
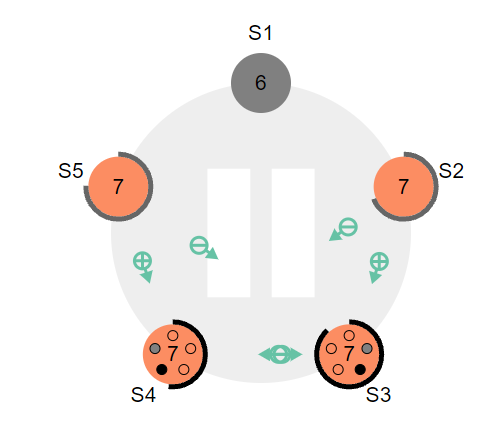
2.2 这时S3和S4都发现,有一个节点没有给他们投票,即宕机的S1,所有他们会不停的给S1发送投票请求,期望S1能给自己一票,同时S4,S3自身依然会等待选举超时时间
ps 这个超时时间可能是永久存在的,只有leader的心跳信号可以重置此时间
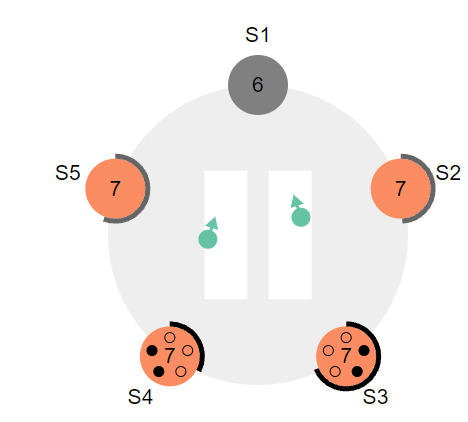
2.3 接着 S4 首先timeout,此时的动作和之前的一致,自身term加1,并且向其他所有节点发送投票请求,
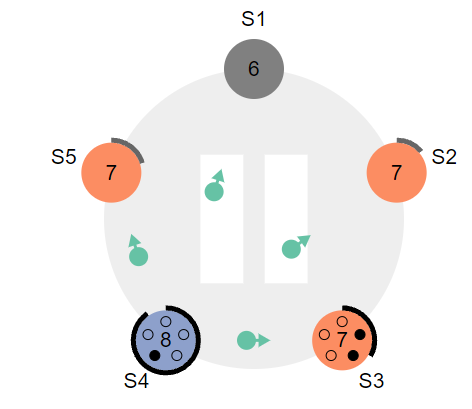
2.4 这一次,它成功获取大部分节点的投票,成功当选为leader,如果此时S1节点复活,会将自身term置为leader的term,并补全差距的日志(下一节)
3 本次场景为网络分区,导致集群脑裂,如下图所示,
成因:原集群为ABCDE,其中A是leader,发生网络分区导致AB 和DCE网络不同,DCE发生选举,选举E节点为leader(获得DCE三票,达到大多数),![]()
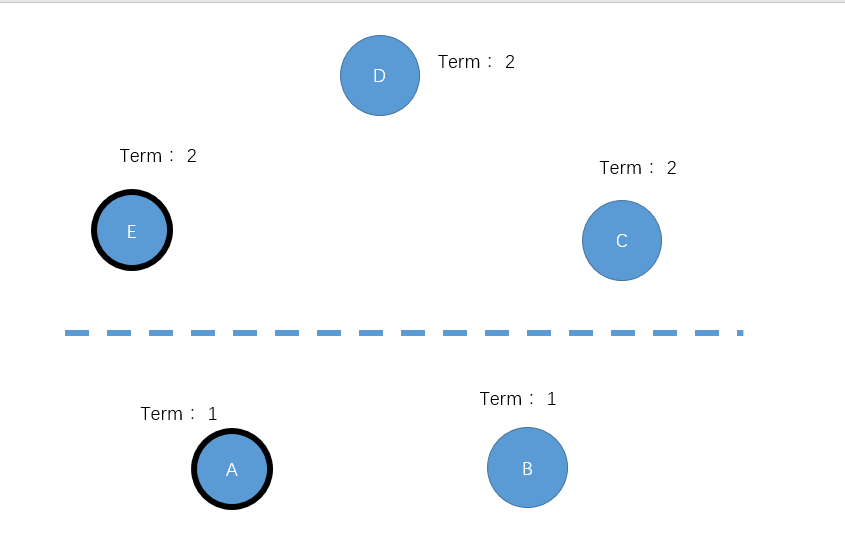
此时clinet有可能访问到这两个leader,其中发送到E的请求正常执行,但是发送到A的请求,由于A节点无法获得大多数节点的认同,请求无法提交,进而导致请求失败,总的来说,集群还是只有一个leader
一段时间后 网络分区恢复,此时AEleader可以与所有节点通信,A节点的请求由于term小于DCE的term,SCE不会认同A的leader地位,而B节点显然会叛变,
对于A节点而言,它会收到另一个leader节点发送的请求,虽然自身也是leader,但由于term小于对方,所以会自动退位,从leader转化为follower。,认同E的leader地位,最后AB会补全和E的差异数据
以上图片来自https://raft.github.io/,非常好用的raft工具,可以自定义各种场景,用于分析
raft的日志
在一个正常运行的集群中,只有leader节点会与外界通信,集群内所有的改变,也是先由leader同步给集群内的其他节点,这时通过使用一种和心跳相同的,称之为 “append entries”的消息完成
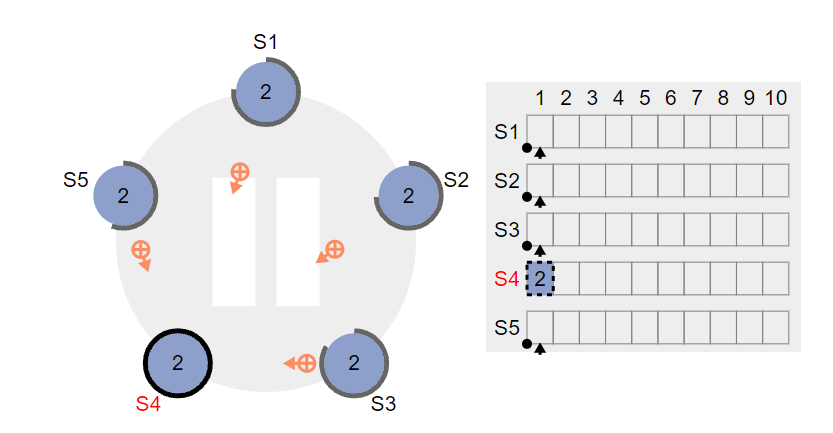
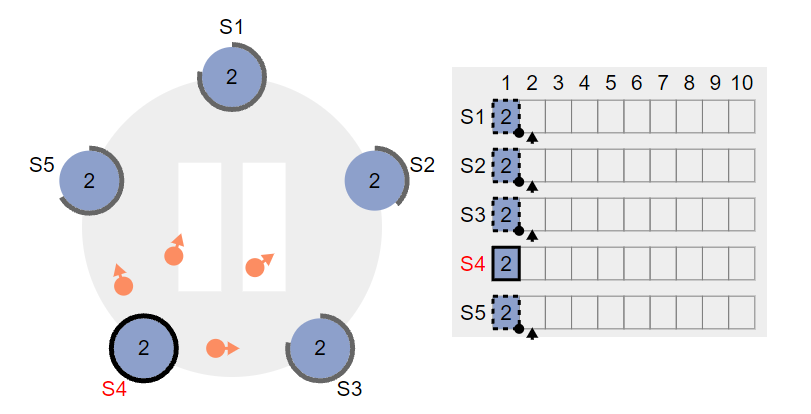
1,集群leader S4 接受到client 一个请求,假设为set 2,leader会将请求记录在自己的日志里,注意此时请求并没有执行,只是记录在日志里,类似redolog
值得注意的还有,此时leader已经发送了心跳,其他节点正在返回信息,这时leader接受了clinet的请求,并不会立刻同步给followwe节点,而是等待下一次发送心跳时将请求发送给followe节点
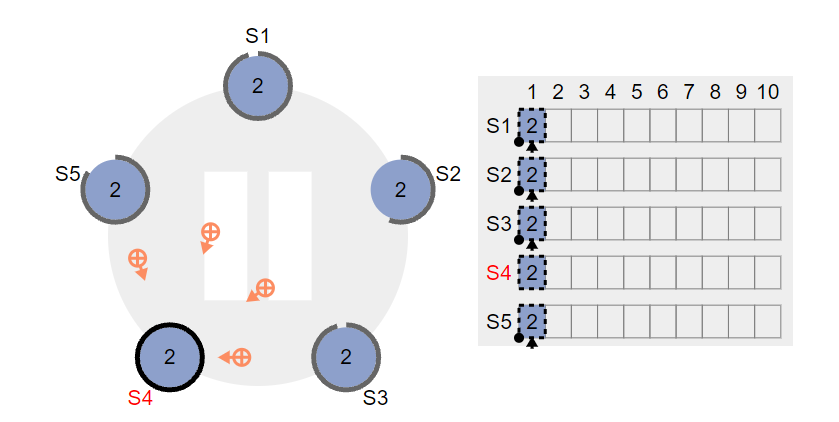
2,下一次心跳中,follower节点接受到 leader的心跳后,发现心跳信号里包含请求,如果follower可以执行该请求,则将请求记录在本地的日志里,然后返回YES
ps :如果不能执行呢?是不返回还是返回 NO。个人认为会返回NO,原因是不返回,可能会使得leader确认此请求是否被通过的时间增长,
3 leader收到大多数节点同意的信号后,将commit这个请求,并且返回client,此时对于client而言,请求已经完成,对于leader而言,还需要在下个心跳周期将请求commit的信息发送到follower。follower收到请求后,自身commit请求。最终达到集群一致
raft的学习暂且到这,下一篇将尝试对比下paxos和raft

 浙公网安备 33010602011771号
浙公网安备 33010602011771号